训练后量化(PTQ)常见问题
模块准备&算子支持
如何准备地平线支持转换的浮点模型?
地平线 PTQ 浮点转换工具链支持 Caffe1.0 和 ONNX(10≤opset_version≤19 且 ir_version≤9)两种模型格式。ONNX 导出方式参考如下:
| 训练框架 | ONNX导出方式 |
|---|---|
| Caffe1.0 | 地平线原生支持,无需导出ONNX |
| Pytorch | Pytorch导出ONNX及模型可视化教程 |
| TensorFlow2 | TensorFlow2导出ONNX及模型可视化教程 |
| PaddlePaddle | PaddlePaddle导出ONNX及模型可视化教程 |
| 其他框架 | ONNX Tutorials |
以上,模型可视化教程内的 ONNX 模型 opset_version、 ir_version 版本支持范围与当前略有差异,请以当前版本范围为准。
如何验证原始浮点 ONNX 模型的正确性?
工具链在转换模型时,会使用基于公版 ONNXRuntime 封装的接口实现模型的解析和前向,所以我们应该在使用工具链之前先检查原始浮点 ONNX 模型本身的合法性(即是否能够正常推理), 以及从训练框架导出 ONNX 的过程中是否引入了精度偏差。具体测试方式可参考:HBRuntime 推理库 章节。
如何修改模型的输入 layout?
PTQ工具不支持转换过程中修改模型的输入layout格式,PTQ转换过程中会保持模型layout不改变。如有修改layout需求可以直接在导出onnx前修改模型完成layout的改变。
如需要从模型层面修改,建议使用如下方式实现:
-
在 DL 框架中增加 transpose,使其输入 layout 为 NHWC,并重新导出 ONNX 模型;
-
使用 onnx 库直接修改模型,参考如下:
模型转换
如何理解yaml文件中的编译器优化等级参数?
在模型转换的yaml配置文件中,编译参数组提供了optimize_level参数来选择模型编译的优化等级,可选范围为 O0~O2。其中:
-
O0 不做任何优化,编译速度最快,适合在模型转换功能验证、调试不同校准方式时使用。
-
O1 - O2 随着优化等级越高,编译优化时的搜索空间就会越大。
-
编译器的优化策略并不是算子粒度层面的,而是针对整个模型的全局优化。
如何编译得到多 batch 模型?
根据原模型种类,我们将分为动态输入模型和非动态输入模型来讨论这个问题。
-
input_batch参数仅在input_shape第一维为1的时候可以使用,(模型为多输入时,需要所有输入的input_shape第一维均为1),且此参数仅在原始onnx模型本身支持多batch推理时才能生效,该参数仅支持配置一个数值,模型为多输入时,配置后该值将作用于模型的所有输入。 -
每份校准数据shape大小,应和
input_shape的大小保持一致。
动态输入模型:如果原模型为动态输入模型时,比如,?x3x224x224(动态输入模型必须使用input_shape参数指定模型输入信息)。
-
当配置input_shape为1x3x224x224时,如果您想编译得到多batch的模型,可以使用
input_batch参数,此时每份校准数据shape大小为1x3x224x224。 -
当配置input_shape的第一维为大于1的整数时,原模型本身将会认定为多batch模型,将无法使用
input_batch参数,且需要注意每份校准数据shape大小。例如配置input_shape为4x3x224x224时,此时每份校准数据shape大小需要为4x3x224x224。
非动态输入模型:
-
当输入的input shape[0]为1时,可以使用
input_batch参数,每份校准数据shape大小与原模型shape保持一致。 -
当输入的input shape[0]不为1时,不支持使用
input_batch参数。
多输入模型在转换过程中,模型输入顺序发生变化,此种情况正常么?
此种情况是正常现象,多输入模型在转换过程中,模型输入顺序是有可能发生变化的。 可能发生的情况如下例所示:
-
原始浮点模型输入顺序:input1、input2、input3。
-
original.onnx模型输入顺序:input1、input2、input3。
-
quanti.bc模型输入顺序:input2、input1、input3。
-
hbm模型输入顺序:input3、input2、input1。
-
当您做精度一致性对齐时,请确保输入顺序是正确的,不然有可能会影响精度结果。
-
如果您想查看hbm模型输入的顺序,可以使用
hb_model_info指令来查看,input_parameters info分组中列出的输入顺序,即为hbm模型的输入顺序。
如何理解PTQ模型转换过程中的主动量化和被动量化?
在模型成功转换成hbm模型后,可能会出现发现仍然有个别op运行在CPU上的情况,但回头仔细对照工具链算子约束列表,明明该op是符合算子约束条件的,也就是理论上该算子应该成功运行在BPU上,为什么仍然是CPU计算呢?
针对此问题,您可参考 地平线官方社区文章,该文章对模型转换工具链中内部的量化原理与背后的逻辑进行了介绍,并针对问题提供了几种解决方法。
如何理解 shape_inference_fail.onnx?
该模型只会在 PTQ 模型转换失败时产出,无特殊意义,可向地平线提供该模型和模型转换时的 log 文件进行 debug 分析。
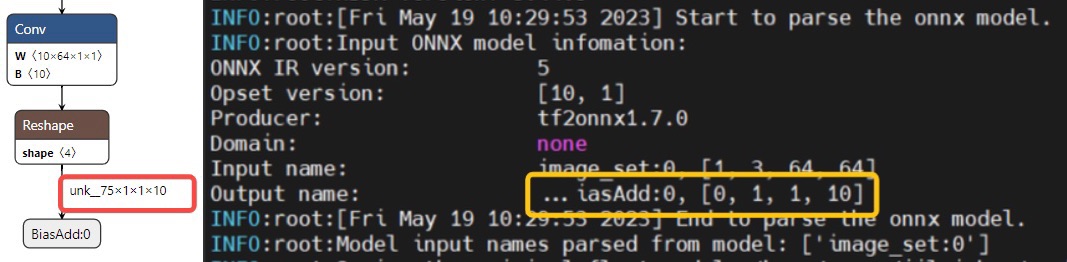
如何理解 log 中模型输入输出 shape 为 0?
模型转换日志会打印模型的输入输出节点的 name 及 shape,但有时也会出现 shape 为 0 的情况,如下图所示。 其主要发生在 batch 维度,因为某些模型的输出 shape 是动态的(使用 dim_param 来存储),转换工具前向推理模型(shape_inference)后就会使用?来占位,此时日志打印就会显示为 0。 这种情况是符合预期的,不会影响模型转换,无需过分关注。
如何理解optimized模型中算子发生变化?
为了提高模型的上板性能,模型转换有一个Optimizer模块,该模块会对模型进行一些图优化,以提升模型上板的性能。 Optimizer模块主要包括常量折叠、算子替换、算子属性/输入更改、算子融合、算子移动等功能。
Optimizer模块会导致模型的算子发生变化,该模块会对模型进行一些等价的图优化。
在转换流程中,hb_compile打印日志中Calibrated Cosine列出现nan的几种情况以及导致此类问题的原因?
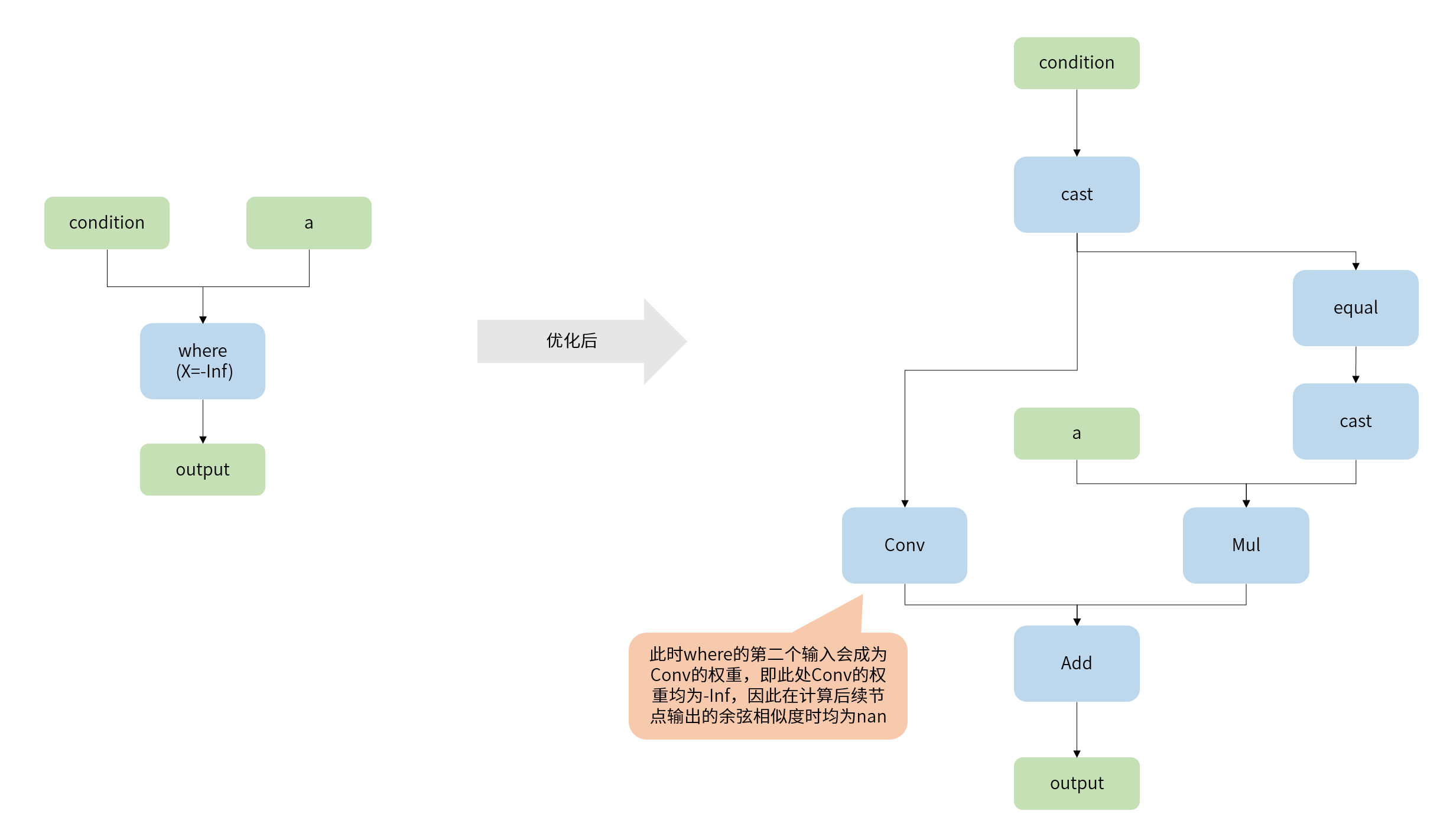
情况1:模型中where算子的第二个输入为-Inf
在转化过程中的优化阶段,为了能够保证where算子可以被量化,在优化阶段会将此算子拆解成多个可量化算子的组合。当 where 的第二个输入为 -Inf 时,会出现转换过程中出现nan的情况。具体原因如下:
情况2:模型中出现全 0 tensor
1). 由 concat 导致出现全0 tensor
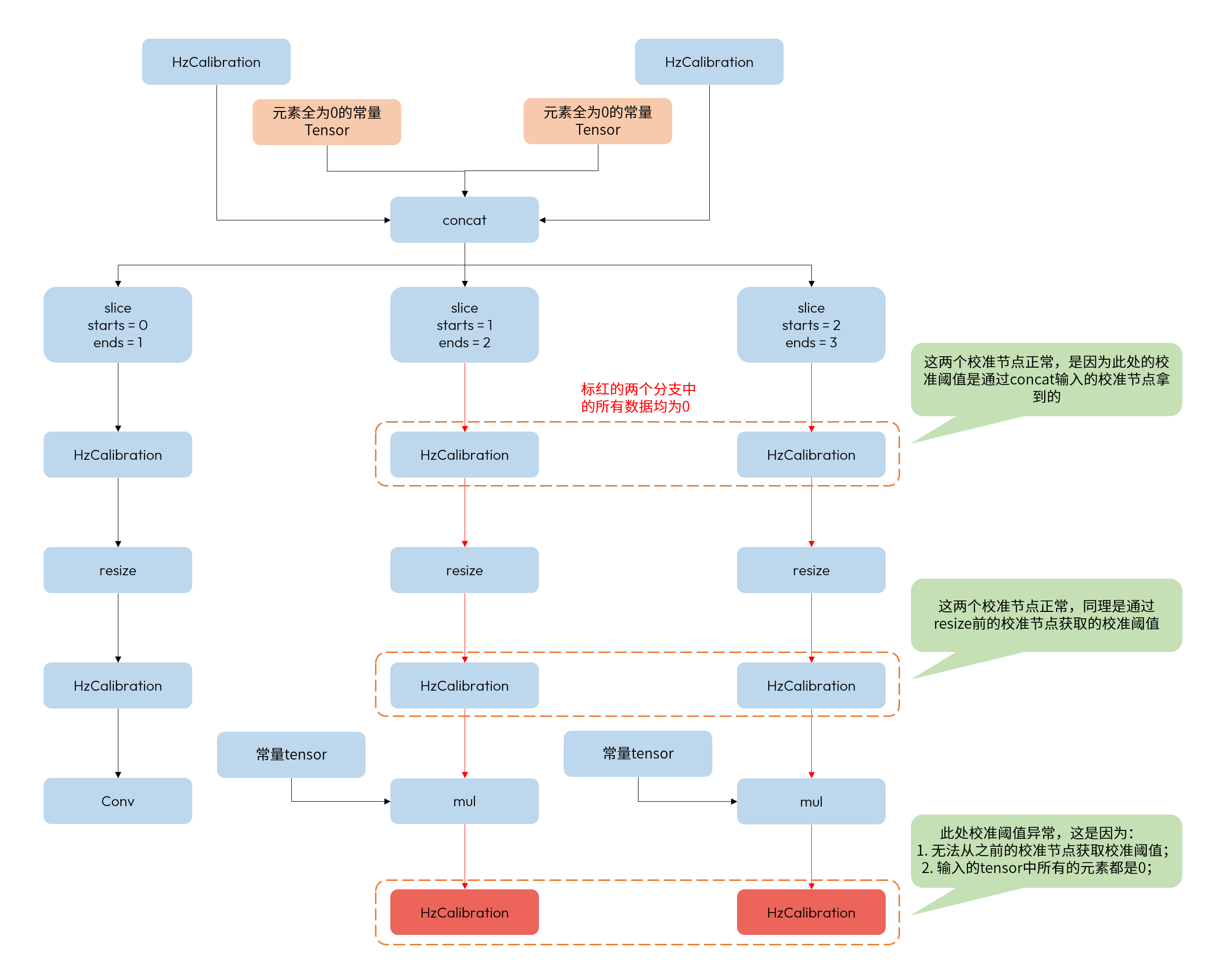
以上述结构为例,concat的两个输入为全0常量,因此在后续经过slice后的输出有可能出现某个分支中流动的数据均为0的情况,并且导致HzCalibration出现非法阈值(即:阈值为0)。
2). 由equal导致出现全0 tensor
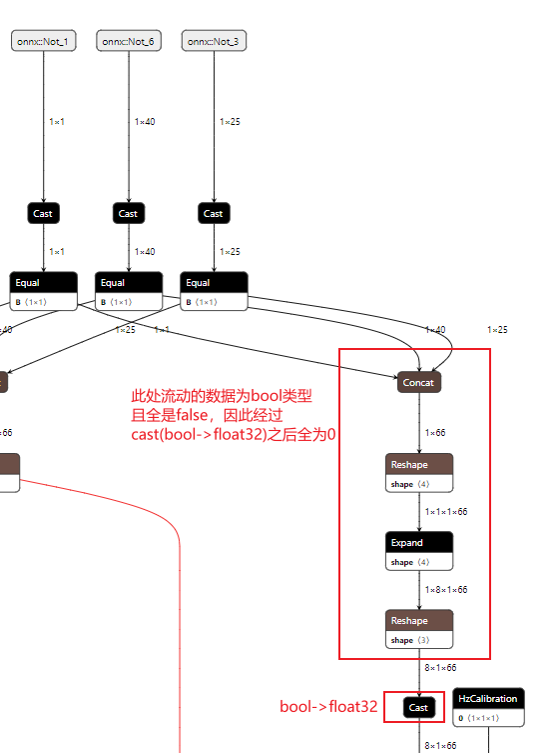
以上述结构为例,模型的输入onnx::Not_3为bool型tensor,在经过cast+equal之后,导致tensor中的数据均为false,在经过cast(bool -> float32)后,出现全0 tensor。
此种情况需要客户尝试使用多组数据进行测试,进而排除由校准数据导致模型出现全0的可能。
模型性能
如何理解BPU加速和CPU计算两种形式?
-
BPU加速:是指模型在板端推理时,该算子可以通过BPU硬件进行量化加速。其中,大部分算子(如conv等)是硬件直接支持的。有些会被替换成其他算子实现加速(如gemm会被替换成conv),还有一些则依赖特定的上下文(如Reshape、Transpose需要前后均为BPU算子)才能被动量化。
-
CPU计算:对于模型中BPU硬件无法直接或间接加速的算子,工具链会将其放在CPU上计算,runtime预测库也会在模型推理时自动完成执行硬件的异构调度。
是否有硬件支持模型输入颜色空间转换?
BPU 支持常见模型输入格式间的转换(例如 nv12 -> rgb/bgr)和数据归一化,可以通过 yaml 文件进行配置。 具体请见 input_type_train、input_type_rt、mean_value、scale_value、std_value 等参数的说明。
如何理解编译器优化等级?
yaml 文件 optimize_level 参数可配置 O0~O2 的编译器优化等级,优化等级越高则搜索空间越大,通常耗时也会更多。优化等级并不会针对算子粒度层面进行一些确定的优化策略,大部分算子的优化与优化等级没关系(这些优化不耗时)。优化等级主要是对全局优化起作用,是结合整个模型进行的分析和优化。
如何处理模型首尾部的量化/反量化算子?
PTQ 工具链默认会在 featuremap 输入模型的首部插入量化算子来实现输入数据从 float32 到更低 bit 计算类型的映射,并在所有模型的尾部插入反量化算子来实现输出数据从低 bit 计算(若 BPU 以 conv 结尾则默认为 int32 输出) 到 float32 的映射。而量化/反量化算子在 CPU 上的执行效率并不高,特别是在数据 shape 比较大的时候。
所以我们更建议通过将量化/反量化操作融合进前后处理,此种方式最为高效,具体说明请见:反量化节点的融合实现。
如何使用 unitconv 算子优化模型性能?
模型中的一个算子能运行在 BPU 上,除了其本身应满足 BPU 支持条件外,还需要能在校准时找到它的量化阈值。 而部分非计算密集型算子(如 concat,reshape 等)的量化阈值会依赖于上下游算子的 featuremap Tensor。 因此,若这些算子在模型首尾处就会默认跑在 CPU 上。 此时若想追求更高效的性能,可以在该算子前/后插入 unitconv 来引入新的量化阈值统计,进而将其量化在 BPU 上。 具体说明可见:unit_conv使用说明(用于优化模型性能) 。
但需要注意的是,这种方法有可能会引入一定的量化损失。 以 conv+reshape+concat 结构输出的模型为例, 工具链默认 conv 会以 int32 高精度输出,反量化至 float32 后再送给 CPU 上的 reshape 和 concat。 若在 concat 之后插入 unitconv,则整个结构都将以 int8 低精度运行在 BPU 上, 此时虽然最后的 unitconv 还能以 int32 高精度输出,但前面 conv 输出的精度压缩已经引入了一定的量化损失。 所以,是否插入 unitconv 来优化性能还请综合考虑。
如何理解模型分段的性能影响?
当模型在BPU算子中间存在不能加速的CPU算子时,在BPU算子和CPU算子之间切换计算时会引入一定的性能损耗,具体包括两方面:
-
CPU算子性能远低于BPU算子。
-
CPU和BPU之间的异构调度还会引入量化、反量化算子(运行在CPU上),且因为内部计算需要遍历数据,所以其耗时会与shape大小成正比。
地平线建议您尽量选择BPU算子搭建模型,以获取更好的性能表现。
模型精度
是否支持 int16/int32计算?
大部分算子默认使用int8计算,部分算子支持int16、fp16计算,算子支持范围持续扩充中,具体详见 工具链算子支持约束列表,另外:
-
若模型中的 BPU 部分以 Conv 结尾,则该算子默认为 int32 高精度输出;
-
DSP 硬件也具备 int8/int16/float32 的计算能力。
如何正确处理模型的校准数据?
PTQ 模型校准数据的准备请参考 数据准备-模型校准集准备 章节。另外,对于 featuremap 输入的模型,请自行完成数据的预处理,并通过 numpy.save 接口保存为所需输入类型的 npy文件。
如何 dump 模型中间层输出?
在模型转换阶段,yaml 文件中的 debug_mode 参数如果配置了 dump_all_layers_output,则会为每个卷积和矩阵乘算子增加一个反量化输出节点,它会显著的降低模型上板后的性能。
其中,output_nodes 参数可以指定模型中的任意节点为输出节点,更利于我们调试调优。 此外,还可以使用 hb_verifier 工具对比定点模型 quantized_model.bc 和上板 hbm 模型的一致性。
在板端部署阶段,hrt_model_exec 工具也支持以 bin 或 txt 的格式保存节点输出(包括用 output_nodes 参数指定的节点),具体使用方式可参考: hrt_model_exec工具介绍 。
如何理解模型尾部部分BPU可加速算子运行在CPU上?
首先,我们需要理解以下两个概念:
-
目前只在模型尾部支持Conv算子以int32高精度输出。
-
通常情况下,模型转换会在optimization阶段将Conv与其后的BN和ReLU/ReLU6融合在一起进行计算。但由于BPU硬件本身限制,在模型尾部以int32高精度输出的Conv却并不支持算子融合。
所以如果模型以Conv+ReLU/ReLU6结尾,那么为了保证量化模型的整体精度,Conv会默认以int32高精度输出,ReLU/ReLU6则会跑在CPU上。同理,其他尾部可加速算子运行在CPU上也都是默认精度优先的选择。不过,地平线支持在yaml文件通过配置 quant_config 将这些算子运行在BPU上,从而获取更好的性能表现,但会引入一定的精度损失。