#量化精度调优实战
本章以一个实际精度调优的例子介绍整个流程,请确保先看完量化精度调优指南章节,了解相关的理论知识和工具用法。
#模型结构和量化配置检查
在对模型做完 QAT 相关的适配和改造后,运行程序,运行目录下会生成 model_check_result.txt,先检查这个文件。
#算子融合检查
首先查看算子融合的情况,发现有少量算子未按照预期融合。
Fusable modules are listed below:
name type
------------------------------------------------ --------------------------------------------------------------------------
model.view_transformation.input_proj.0.0 <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
model.view_transformation._generated_add_0 <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'>
name type
------------------------------------------------ --------------------------------------------------------------------------
model.view_transformation.input_proj.1.0 <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
model.view_transformation._generated_add_2 <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'>
name type
------------------------------------------------ --------------------------------------------------------------------------
model.view_transformation.input_proj.2.0 <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
model.view_transformation._generated_add_4 <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'>
name type
------------------------------------------------ --------------------------------------------------------------------------
model.view_transformation.input_proj.3.0 <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
model.view_transformation._generated_add_6 <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'>
name type
------------------------------------------------ --------------------------------------------------------------------------
model.view_transformation.input_proj.4.0 <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
model.view_transformation._generated_add_8 <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'>
name type
------------------------------------------------ --------------------------------------------------------------------------
model.view_transformation.input_proj.5.0 <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
model.view_transformation._generated_add_10 <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'>
查看 model.view_transformation.input_proj 模块。
class BevFormer(BaseModule):
def process_input(self, feats):
...
for cam_idx in range(num_cameras):
# 因动态代码块的存在,需要使用 dynamic_block 标注才能正常融合
with Tracer.dynamic_block(self, "bevformer_process_input"):
src = cur_fpn_lvl_feat[cam_idx]
bs, _, h, w = src.shape
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
src = self.input_proj[str(cam_idx)](src)
src = src + self.cams_embeds[cam_idx][None, :, None, None]
src = src + self.level_embeds[feat_idx][None, :, None, None]
src = src.flatten(2).transpose(1, 2) # B, C, H, W --> B, C, H*W --> B, H*W, C
src_flatten.append(src)
#共享模块检查
接着我们进行共享模块的检查,对于 called times > 1 的模块需要拆开。
Each module called times:
name called times
--------------------------------------------------------------------------------------- --------------
...
model.map_head.sparse_head.decoder.gen_sineembed_for_position.div.reciprocal 8
model.map_head.sparse_head.decoder.gen_sineembed_for_position.div.mul 8
model.map_head.sparse_head.decoder.gen_sineembed_for_position.sin_model.sin 8
model.map_head.sparse_head.decoder.gen_sineembed_for_position.cos_model.cos 8
model.map_head.sparse_head.decoder.gen_sineembed_for_position.stack 8
model.map_head.sparse_head.decoder.gen_sineembed_for_position.cat 4
model.map_head.sparse_head.decoder.gen_sineembed_for_position.mul 8
model.map_head.sparse_head.decoder.gen_sineembed_for_position.dim_t_quant 4
...
calibration 或 qat 训练后发现精度比较差,使用 debug 工具时可以在逐层比较中观察这些共享算子的统计信息,base model 为浮点模型,analy model 为校准模型。以 model.map_head.sparse_head.decoder.gen_sineembed_for_position.div.mul 的其中两次调用为例,量化表示的最大值为 128 * 0.0446799 ≈ 5.719,在第一次使用中,输出范围明显小于 [-5.719, 5.719],误差较小, 第二次使用中,输出范围超出 [-5.719, 5.719],数值被截断,产生了较大误差。两次数值范围的差异也导致统计出的 scale 不准确。
+------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+--------------------------------+---------------+------------+------------------+-------------------+------------------+-------------------+
| | mod_name | base_op_type | analy_op_type | shape | quant_dtype | qscale | base_model_min | analy_model_min | base_model_max | analy_model_max |
|------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+--------------------------------+---------------+------------+------------------+-------------------+------------------+-------------------+
...
| 1227 | model.map_head.sparse_head.decoder.gen_sineembed_for_position.div | horizon_plugin_pytorch.nn.div.Div | horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional.mul | torch.Size([1, 1600, 128]) | qint8 | 0.0446799 | 0.0002146 | 0.0000000 | 4.5935526 | 4.5567998 |
...
| 1520 | model.map_head.sparse_head.decoder.gen_sineembed_for_position.div | horizon_plugin_pytorch.nn.div.Div | horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional.mul | torch.Size([1, 1600, 128]) | qint8 | 0.0446799 | 0.0000000 | 0.0000000 | 6.2831225 | 5.7190272 |
...
查看 model.map_head.sparse_head.decoder.gen_sineembed_for_position 模块。
class AnchorDeformableTransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, return_intermediate=False):
...
# 构造不同的 gen_sineembed_for_position,拆开使用。
for i in range(len(self.layers)):
self.add_module(
"gen_sineembed_for_position%d" % (i), PositionEmbedding()
)
def forward(...):
...
for lid, layer in enumerate(self.layers):
ref_shape = reference_points.shape
assert ref_shape[-1] == 2
reference_points_reshape = reference_points.view(ref_shape[0], -1, 2)
query_sine_embed = getattr(self, "gen_sineembed_for_position%d" % (lid))(reference_points_reshape)
...
#QConfig 正确性检查
input dtype statistics:
+----------------------------------------------------------------------------+-----------------+---------+----------+----------+
| module type | torch.float32 | qint8 | qint16 | qint32 |
|----------------------------------------------------------------------------+-----------------+---------+----------+----------|
| <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 290 | 15 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvReLU2d'> | 0 | 6 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | 0 | 228 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.gelu.GELU'> | 0 | 63 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 3 | 425 | 725 | 140 |
| <class 'horizon_plugin_pytorch.nn.qat.batchnorm.BatchNorm2d'> | 0 | 9 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> | 5 | 117 | 9 | 72 |
| <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 0 | 64 | 125 | 0 |
| <class 'torch.nn.modules.dropout.Dropout'> | 0 | 53 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.linear.LinearReLU'> | 1 | 17 | 0 | 28 |
| <class 'horizon_plugin_pytorch.nn.qat.conv_transpose2d.ConvTranspose2d'> | 0 | 1 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | 0 | 8 | 0 | 56 |
| <class 'horizon_plugin_pytorch.nn.qat.linear.LinearAdd'> | 0 | 4 | 0 | 4 |
| <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | 0 | 8 | 0 | 4 |
| total | 299 | 1018 | 859 | 304 |
+----------------------------------------------------------------------------+-----------------+---------+----------+----------+
output dtype statistics:
+----------------------------------------------------------------------------+-----------------+---------+----------+----------+
| module type | torch.float32 | qint8 | qint16 | qint32 |
|----------------------------------------------------------------------------+-----------------+---------+----------+----------|
| <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | 0 | 123 | 182 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.conv2d.ConvReLU2d'> | 0 | 6 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | 0 | 228 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.gelu.GELU'> | 0 | 63 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | 0 | 341 | 716 | 64 |
| <class 'horizon_plugin_pytorch.nn.qat.batchnorm.BatchNorm2d'> | 0 | 9 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> | 0 | 85 | 18 | 100 |
| <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> | 0 | 55 | 134 | 0 |
| <class 'torch.nn.modules.dropout.Dropout'> | 0 | 53 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.linear.LinearReLU'> | 0 | 18 | 0 | 28 |
| <class 'horizon_plugin_pytorch.nn.qat.conv_transpose2d.ConvTranspose2d'> | 0 | 1 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | 0 | 8 | 0 | 56 |
| <class 'horizon_plugin_pytorch.nn.qat.linear.LinearAdd'> | 0 | 4 | 0 | 0 |
| <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | 12 | 0 | 0 | 0 |
| total | 12 | 994 | 1050 | 248 |
+----------------------------------------------------------------------------+-----------------+---------+----------+----------+
Each layer out qconfig:
+---------------------------------------------------------------------------------------------+----------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+-------------------+--------------+
| Module Name | Module Type | Input dtype | out dtype | ch_axis | observer |
|---------------------------------------------------------------------------------------------+----------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------+-------------------+--------------|
...
| model.obstacle_head.reg_branches.0.0 | <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> | ['qint8'] | ['qint32'] | -1 | MixObserver |
...
| model.obstacle_head.reg_out_dequant0 | <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | ['qint8'] | [torch.float32] | qconfig = None | |
存在如下问题:
-
存在 qint32 输出的算子。高精度输出体现在这里的表格中是 torch.float32,并不是 qint32,应该是 qconfig 配置错误。需修改 model.obstacle_head.reg_branches.0.0 的 qconfig 配置。
-
DequantStub 存在 qint8 输入,说明有几处可能未高精度输出。模板只支持 dequant 前的 GEMM 类算子自动高精度输出,需要排查这些 dequant 前是否为 GEMM 类算子。
-
除 quant 和 dequant 外,少量算子有 fp32 输入,说明有几处可能缺少 quant 节点。如果编译模型,会发现模型并不是全一段,有部分算子被退回 cpu,可以在每一层的详细输入输出类型中看出是哪个算子,并插入 quantstub。
#混合精度调优
整个流程首先进行全 int16 精度调优,此阶段用于确认模型的精度上限,排查工具使用问题和量化不友好模块。在确认全 int16 精度满足需求后,进行全 int8 精度调优。如果精度不达标则进行 int8 / int16 混合精度调优,在全 int8 的基础上逐步增加 int16 的比例,该阶段需要在精度和性能间做权衡,在满足精度的前提下,找出性能尽可能好的量化配置。
#全 INT16 精度调优
| 分支 | float | 目标(损失 < 1%) | 全 int16 calibration |
|---|---|---|---|
| 动态 | 73.6 | 72.864 | 0 |
| 静态 | 55.5 | 54.945 | 0 |
第一次校准,精度崩溃。正常情况下,全 int16 量化方式不会导致精度崩溃,需要针对造成掉点的输出进行精度 debug,这里静态和动态分支的输出任意取一个做如下改造。这里的示例加上了部分后处理(sigmoid),并且只针对静态分支(map)的最后一层输出做 debug。
class BevNet(pl.LightningModule):
def forward(self, batch):
...
# return image, calibration, gt_dict, mask_dict, pred_dict
# 只针对掉点的输出 debug。针对全部输出 debug 也可以,但没有针对性,速度也会慢一点
return pred_dict['map']['preds']['layer_3']
class MapQRHead(BaseModule):
def forward_branch(self, hs, init_reference, inter_references):
outputs = []
for lvl in range(hs.shape[0]):
...
cls_out = getattr(self, "cls_out_dequant%d" % (lvl))(self.cls_branches[lvl](hs[lvl]))
pts_out = getattr(self, "pts_out_dequant%d" % (lvl))(self.pts_branches[lvl](hs[lvl])).view(bs, -1, 2)
# 这个属于后处理逻辑,虽然放在 dequant 之后,但精度 debug 也要加上
pts_out = pts_out.sigmoid()
pts_out = pts_out.view(bs, self.num_polyline, self.num_pts_per_polyline, -1)
y = torch.cat([cls_out, pts_out, attr_out[0], attr_out[1], attr_out[2], attr_out[3], attr_out[4]], dim=-1) # bs,num_polyline,num_pts,n_attr
outputs.append(y)
return outputs
得到的 debug 结果如下:
op_name sensitive_type op_type L1
--------------------------------------------------------------------------------------- ---------------- -------------------------------------------------------------------------- ----------
model.view_transformation.transformer.layers.0.quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.580483
model.obstacle_head.decoder.layers.0.cross_attn.quant_normalizer activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.130977
...
从量化敏感度看,排前面的主要是几个 quantstub。在逐层比较中分析这几个敏感算子的量化误差是哪种误差。
+------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+--------------------------------+---------------+------------+------------+--------------+------------+------------+-------------+-------------+-------------------------------------------------+------------------+-------------------+------------------+-------------------+-------------------+--------------------+------------------+-------------------+-----------------+-------------------+
| | mod_name | base_op_type | analy_op_type | shape | quant_dtype | qscale | Cosine | MSE | L1 | KL | SQNR | Atol | Rtol | base_model_min | analy_model_min | base_model_max | analy_model_max | base_model_mean | analy_model_mean | base_model_var | analy_model_var | max_atol_diff | max_qscale_diff |
|------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+--------------------------------+---------------+------------+------------+--------------+------------+------------+-------------+-------------+-------------------------------------------------+------------------+-------------------+------------------+-------------------+-------------------+--------------------+------------------+-------------------+-----------------+-------------------|
...
| 791 | model.view_transformation.transformer.layers.0.quant | horizon_plugin_pytorch.quantization.stubs.QuantStub | horizon_plugin_pytorch.nn.qat.stubs.QuantStub | torch.Size([1, 1875, 24, 2]) | qint8 | 0.7764707 | 0.9999968 | 0.1134158 | 0.3205845 | 0.0000081 | 46.6785774 | 0.3882294 | 1.0000000 | -99.0000000 | -98.6117706 | 0.9999269 | 0.7764707 | -53.0977783 | -52.8312225 | 2459.8188477 | 2446.8227539 | 0.3882294 | 0.4999923 |
...
| 883 | model.obstacle_head.decoder.layers.0.cross_attn.quant_normalizer | horizon_plugin_pytorch.quantization.stubs.QuantStub | horizon_plugin_pytorch.nn.qat.stubs.QuantStub | torch.Size([1, 7500, 8, 32]) | qint8 | 0.0522360 | 0.3601017 | 0.9630868 | 0.6762735 | 0.0000729 | -0.6995326 | 12.4819937 | 601413.5625000 | -9.2183294 | -6.5295014 | 10.2716885 | 6.6339736 | -0.0177280 | -0.0255637 | 0.8194664 | 0.6810485 | 12.4819937 | 238.9537970 |
...
对于 model.view_transformation.transformer.layers.0.quant:
-
量化类型仍然为 qint8,说明 int16 的配置未生效,需要排查除 setter 以外,是否手动设置了 int8 qconfig.
-
scale 是 0.7764707, 能表示的浮点范围为 0.776 * (-128) = -99.38 到 0.776 * 127 = 98.61。结合这里的物理含义,此 quant 的输入范围应该是 -100 到 1, 所以会产生少量的截断误差。同时,此数值范围较大,对于 int8 来说,也会产生较大的舍入误差。所以需要改为 int16 量化并按输入范围设置固定 scale 为 100 / 32768。
对于 model.obstacle_head.decoder.layers.0.cross_attn.quant_normalizer,也一样是类似的问题。
修改完成后,重新跑校准和精度 debug,可以观察到精度明显提升,之前敏感度排序靠前的几个算子,敏感度也有明显下降。之后,我们进行 qat 训练。
| 分支 | float | 目标(损失 < 1%) | 全 int16 calibration |
|---|---|---|---|
| 动态 | 73.6 | 72.864 | 73.4 |
| 静态 | 55.5 | 54.945 | 54 |
初次 QAT 训练,发现精度崩溃,loss 曲线不收敛。
| 分支 | float | 目标(损失 < 1%) | 全 int16 calibration | 全 int16 qat | finetune float |
|---|---|---|---|---|---|
| 动态 | 73.6 | 72.864 | 73.4 | 0 | 0 |
| 静态 | 55.5 | 54.945 | 54 | 0 | 0 |
做以下尝试:
-
因为校准指标差的不多,所以认为模型中已不包含量化工具使用问题,首先想到的是调整 lr,weight decay 等许多方法,仍然无法解决这个问题。
-
精度 debug。发现 model.map_head.sparse_head.decoder.gen_sineembed_for_position0.dim_t_quant 在 int16 量化的情况下,敏感度排名靠前,仍然误差较大。
op_name sensitive_type op_type L1 quant_dtype
----------------------------------------------------------------------------- ---------------- -------------------------------------------------------------------------- ---------- -------------
model.map_head.sparse_head.decoder.gen_sineembed_for_position0.dim_t_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.82213 qint16
model.map_head.sparse_head.decoder.gen_sineembed_for_position1.dim_t_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.184159 qint16
model.map_head.sparse_head.pts_branches.0.6 activation <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> 0.131423 qint16
model.map_head.sparse_head.decoder.gen_sineembed_for_position2.dim_t_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.111852 qint16
model.map_head.sparse_head.pts_branches.1.6 activation <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> 0.0930651 qint16
model.map_head.sparse_head.sigmoid activation <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> 0.0887103 qint16
model.map_head.sparse_head.pts_branches.2.6 activation <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> 0.0728263 qint16
model.map_head.sparse_head.reference_points.2 activation <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> 0.0689369 qint16
查看逐层比较,量化范围为 32767 * 0.2642754 ≈ 8659.51,虽然数值比较大,但没有明显的截断误差.
+------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+----------------------------------+---------------+------------+------------+-------------+-----------+------------+-------------+-------------+-------------------------------------------------+------------------+-------------------+------------------+-------------------+-------------------+--------------------+------------------+-------------------+-----------------+-------------------+
| | mod_name | base_op_type | analy_op_type | shape | quant_dtype | qscale | Cosine | MSE | L1 | KL | SQNR | Atol | Rtol | base_model_min | analy_model_min | base_model_max | analy_model_max | base_model_mean | analy_model_mean | base_model_var | analy_model_var | max_atol_diff | max_qscale_diff |
|------+-------------------------------------------------------------------------------+-----------------------------------------------------------------------------------+-----------------------------------------------------------------------------+----------------------------------+---------------+------------+------------+-------------+-----------+------------+-------------+-------------+-------------------------------------------------+------------------+-------------------+------------------+-------------------+-------------------+--------------------+------------------+-------------------+-----------------+-------------------|
...
| 1296 | model.map_head.sparse_head.decoder.gen_sineembed_for_position0.dim_t_quant | torch.ao.quantization.stubs.QuantStub | horizon_plugin_pytorch.nn.qat.stubs.QuantStub | torch.Size([128]) | qint16 | 0.2642754 | 0.9999999 | 0.0058058 | 0.0670551 | 0.0000000 | 89.0683746 | 0.1328125 | 0.0845878 | 1.0000000 | 1.0571015 | 8659.6435547 | 8659.5107422 | 1009.3834229 | 1009.3997803 | 3694867.5000000 | 3694819.5000000 | 0.1328125 | 0.5025535 |
...
打印 dim_t,发现是非均匀分布,对线性量化不友好,在数值较小时会产生较大误差。
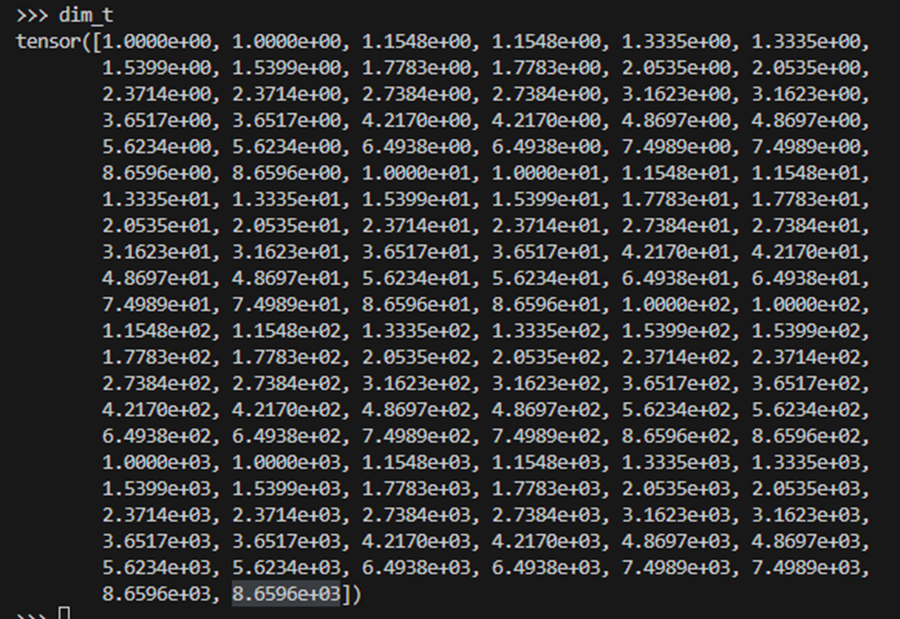
dim_t 是一个除法分母,当 dim_t 较小时,舍入误差会被除法放大。因为 dim_t 是固定的,而且知道前几个小数值的舍入误差影响较大,我们只要将他分成两组量化,在 div 之后再 cat 起来就行,这样就能保证第一组 scale 变小,减小舍入误差。
class PositionEmbedding(torch.nn.Module):
def forward(self, pos_tensor):
dim_t = torch.arange(128, dtype=torch.float32, device=pos_tensor.device)
dim_t = 10000 ** (2 * (dim_t // 2) / 128)
# dim_t = self.dim_t_quant(dim_t)
# pos_x = x_embed[:, :, None] / dim_t
dim_t_1 = dim_t[:32] # 如果调整得更细,32 也可以调大或调小。
dim_t_2 = dim_t[32:]
pos_x_1 = x_embed_1[:, :, None] / dim_t_1
pos_x_2 = x_embed_2[:, :, None] / dim_t_2
pos_x = torch.cat([pos_x_1, pos_x_2])
此时,再看全 int16 校准和 qat 精度,校准精度有一定提升, qat 精度仍然崩溃。
| 分支 | float | 目标(损失 < 1%) | 全 int16 calibration | 全 int16 qat | finetune float |
|---|---|---|---|---|---|
| 动态 | 73.6 | 72.864 | 73.4 | 0 | 0 |
| 静态 | 55.5 | 54.945 | 54.7 | 0 | 0 |
开始排查训练 pipeline 的问题:
-
使用 qat 流程和训练参数 finetune 浮点模型,并与浮点训练对比,发现 loss 仍然偏大,精度仍然崩溃。
-
将 lr 设置为 0,finetune 仍然精度崩溃,于是定位到问题与 qat 无关,是 qat 训练所使用的代码未与浮点代码对齐。
仔细对比修改记录,解决浮点模型的对齐问题后,再重新进行全 int16 模型的校准和 qat,精度达标。
| 分支 | float | 目标(损失 < 1%) | 全 int16 calibration | 全 int16 qat |
|---|---|---|---|---|
| 动态 | 73.6 | 72.864 | 73.4 | 74.1 |
| 静态 | 55.5 | 54.945 | 54.7 | 55.3 |
#全 INT8 精度调优
因为我们在全 int16 debug 中已经发现有一些比较敏感的算子,在全 int8 调优中可以将这些算子直接设置为 int16(也可以假设没发现保持 int8,在 int8 精度 debug 中也是可以找出来的),其余算子设置为 int8。在这样的量化配置下,校准和 qat 精度都崩溃。
| 分支 | float | 目标(损失 < 1%) | 全 int16 calibration | 全 int16 qat | 全 int8 calibration | 全 int8 qat |
|---|---|---|---|---|---|---|
| 动态 | 73.6 | 72.864 | 73.4 | 74.1 | 0 | 0 |
| 静态 | 55.5 | 54.945 | 54.7 | 55.3 | 0 | 0 |
需要使用 debug 工具分析后增加 int16 算子。
#INT8 / INT16 混合精度调优
按照全 int8 debug 的结果,将前几个敏感度断层式领先的算子设置为 int16。
op_name sensitive_type op_type L1 quant_dtype
--------------------------------------------------------------------------------------- ---------------- -------------------------------------------------------------------------- --------- -------------
model.view_transformation.ref_point_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 1.79371 qint8
model.map_head.sparse_head.decoder.gen_sineembed_for_position0.dim_t_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 1.46594 qint8
model.map_head.sparse_head.decoder.reg_branch_output_add0 activation <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> 0.352401 qint8
model.map_head.sparse_head.decoder.gen_sineembed_for_position1.dim_t_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.246953 qint8
model.view_transformation.transformer.layers.0.linear2 activation <class 'horizon_plugin_pytorch.nn.qat.linear.Linear'> 0.22353 qint8
model.map_head.sparse_head.decoder.gen_sineembed_for_position2.dim_t_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.214513 qint8
model.map_head.sparse_head.decoder.reg_branch_output_add1 activation <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> 0.185211 qint8
model.map_head.sparse_head.sigmoid activation <class 'horizon_plugin_pytorch.nn.qat.segment_lut.SegmentLUT'> 0.1826 qint8
model.map_head.sparse_head.decoder.gen_sineembed_for_position3.dim_t_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 0.166937 qint8
最终,使用敏感度 top 0.5% 的算子 int16 ,精度达标。接下来,还可以再精调学习率,weight decay 等参数,在使用更少的 int16 的情况下使得 qat 精度达标。
| 分支 | float | 目标(损失 < 1%) | 全 int8 calibration | 全 int8 qat | int8 + ref_point_quant int16 calibration | int8 + ref_point_quant int16 qat | int8 + 敏感度 top 0.5% int16 calibration | int8 + 敏感度 top 0.5% int16 qat |
|---|---|---|---|---|---|---|---|---|
| 动态 | 73.6 | 72.864 | 0 | 0 | 70.9 | 71.3 | 71 | 73.1 |
| 静态 | 55.5 | 54.945 | 0 | 0 | 7.5 | 27.8 | 53.7 | 55.1 |
#过程回顾
-
优先查看敏感度(与精度掉点相关的输出),看完敏感度再看逐层比较。确定某一算子敏感后,先通过逐层比较或统计量确认造成的误差是舍入误差还是截断误差,然后再针对性的调整量化配置。
-
int8 / int16 调优由敏感度setter完成,只需要设置比例即可,暂时没有太多难度。精度调优的重点应放在全 int16 调优,这里需要把使用问题,量化不友好模块等等各种千奇百怪的问题都解决。
-
全 int16 calib 要有一个没有崩溃的精度。精度崩溃说明有使用问题或者量化不友好,整个过程是不断 debug,按照上面介绍的方法,分析 top 敏感算子,修改量化配置的过程,直到有一个不崩溃的精度为止。有些修改并不会立即反映出有精度上的提升,但应该能观察到修改相关的算子敏感度变低了。