量化精度调优指南
背景
量化误差
标准的对称量化公式为 quantized=clamp(round(scalefloat),qmin,qmax),产生误差的地方主要有:
-
round 产生的舍入误差。例如:当采用 int8 量化,scale 为 0.0078 时,浮点数值 0.0157 对应的定点值为 round(0.0157 / 0.0078) = round(2.0128) = 2, 浮点数值 0.0185 对应的定点值为 round(0.0185 / 0.0078) = round(2.3718) = 2。两者均产生了舍入误差,且由于舍入误差的存在,两者的定点值一致。
-
clamp 产生的截断误差。当 qmax * scale 无法覆盖需要量化的数值范围时,可能产生较大截断误差。例如:当采用 int8 量化,scale 为 0.0078 时,qmax * scale = 127 * 0.0078 = 0.9906,大于 0.9906 的值对应的定点值将被截断到 127。
量化必然产生误差,但误差对模型精度的影响程度却不同,原因如下:
-
有些离群点有较大截断误差对模型几乎没有影响。
-
不同算子对误差的敏感程度不同。例如:sigmoid,softmax 等算子,对输入在特定定义域内误差的容忍度比较高,而 topk,sort 等算子对误差非常敏感。
-
模型具有一定的鲁棒性,泛化性,小的误差可以视作训练中的一种正则。
注意
基于这些原因,量化误差对模型精度的影响不应当只观察单算子量化误差,应当重点关注单算子量化对整个模型输出的影响,单算子误差只作为辅助参考。整个精度调优的过程是以观察量化对整个模型输出的影响为主,单算子误差为辅,不断调整量化配置缓解截断误差和舍入误差的过程。
减小量化误差
-
对于舍入误差,可以使用更小的 scale,这样可以使得单个定点值对应的浮点值范围变小。由于直接减小 scale 会导致截断误差,所以常用的方法是使用更高的精度类型,比如:将 int8 换成 int16,由于定点值范围变大, scale 将减小。
-
对于截断误差,可以使用更大的 scale。scale 一般是由量化工具使用统计方法得到,scale 偏小的原因是校准数据不够全,校准方法不对,导致 scale 统计的不合理。比如:某一输入的理论范围为 [-1, 1],但校准或 qat 过程中,没有观测到最大值为 1 或最小值为 -1 的样本或观测到此类样本的次数太少。应该增加此类数据或者根据数值范围,手动设置固定 scale。在截断误差不大的情况下,可以调整校准参数,通过不同的校准方法和超参缓解截断误差。
量化精度调优
量化精度调优包括两个方面:
-
模型结构和量化配置检查。检查主要目的是避免非调优类的问题影响量化精度,比如:qconfig 配置错误,使用了量化不友好的共享模块等。
-
混合精度调优。先使用高精度算子为主的模型快速迭代出精度达标的模型,获取精度上限和性能下限,再使用精度调优工具分析并调整量化配置,得到兼顾精度与性能的量化模型。
注意
请注意,在进行下方精度调优操作之前,请务必先验证自身 pipeline 正确性。
模型结构和量化配置检查
在模型完成 prepare 之后,首先需要检查量化配置错误和模型结构对量化不友好的情况。可以使用 debug 工具中的 check_qat_model 接口进行检查,接口使用方式可参考精度调优工具使用指南章节。
注意
prepare 接口中已集成 check_qat_model,可以直接在运行目录下查看 model_check_result.txt。
算子融合
检查模型中是否存在可以融合但没有融合的模块。模型在 BPU 上部署时会将 conv / bn / add / relu 等算子融合,在 qat 模型中,这些算子会被替换为一个 Module,避免在中间插入伪量化节点。如果这些算子没有融合,那么中间会产生额外的量化节点,对精度和性能可能产生轻微影响。下面的例子表明 conv 和 relu 没有 fuse。
Fusable modules are listed below:
name type
------ -----------------------------------------------------
conv <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'>
relu <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'>
在 prepare 的不同 method 中,可能导致产生算子融合错误的原因和解决方法有:
-
PrepareMethod.JIT 和 PrepareMethod.JIT_STRIP:
a. 动态代码块中包含算子融合,需要使用 dynamic_block 进行标注。
b. 调用次数变化的部分在 trace 时仅执行了一次,需要使用能够让调用次数变化的部分执行多次的输入作为 example_inputs。
-
PrepareMethod.EAGER:未进行 fuse 操作或 fuse_modules 写错,需要检查并修复手写的 fuse 逻辑。
共享模块
由于 horizon_plugin_pytorch 采用模块替换的方式插入量化节点,所以对于一个模块仅能统计一组量化信息。当一个模块对象被多次调用且多次调用的输出数据分布差异较大时,使用同一组量化参数将产生较大误差,需要将共享模块拆开。如果多次调用的输出数据分布差异不大,那么就不需要拆开共享模块。这里先对共享模块的概念做一个说明,后面逐层比较的时候可以结合这里的结果决定是否需要拆开共享模块。
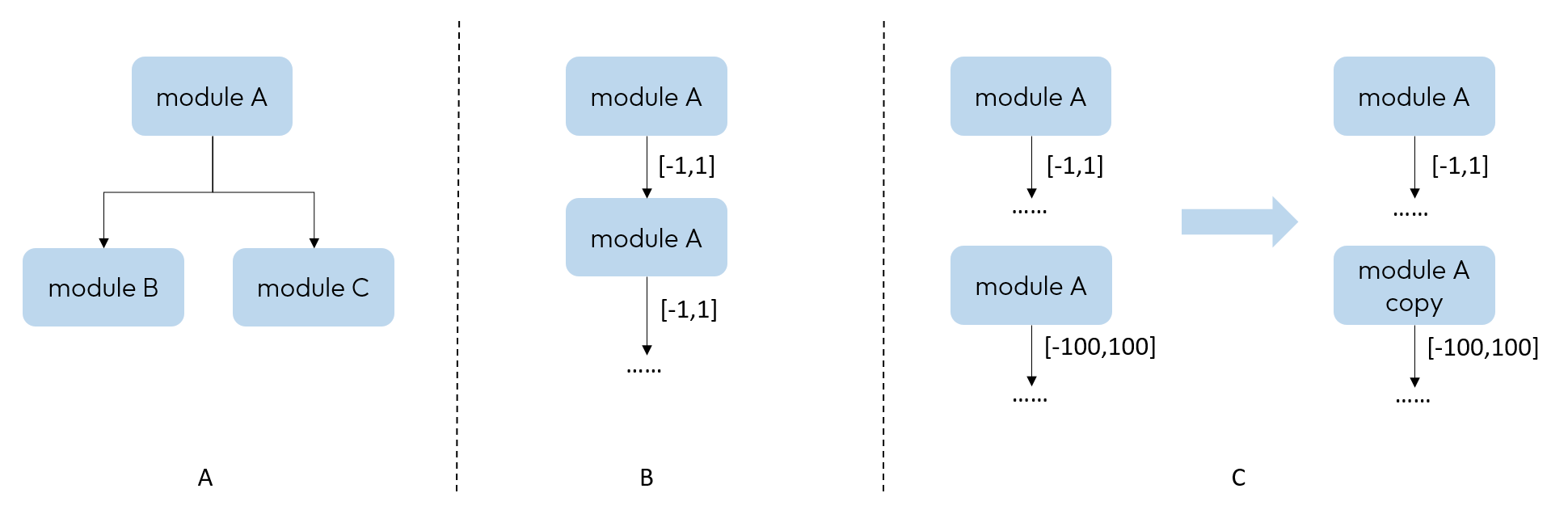
三种常见理解中的“共享”与这里所说的“共享”的异同:
A. 一个 module 后接多个 module,module A 被认为是共享,但这里 module A 仅被调用一次,输出数据分布不存在差异,不会影响量化精度,在调用次数检查中也不会体现出来。
B. 一个 module 被反复调用多次,但多次输出数据分布差异较小。虽然在调用次数检查中可以看出来,但对量化精度影响较小,不需要修改。
C. 一个 module 被反复调用多次,多次输出分布差异较大。在调用次数检查中可以看出来,且对量化精度影响较大,需要手动将其复制拆分。
在 model_check_result.txt 中,可以查看每个 module 的调用次数。正常每个 op 仅调用 1 次,0 表示未被调用,超过 1 次则表示调用了多次。下面的例子中,conv 为共享模块。
Each module called times:
name called times
------- --------------
conv 2
quant 1
dequant 1
# 对应代码
# def forward(self, x):
# x = self.quant(x)
# x = self.conv(x)
# x = self.conv(x)
# x = self.dequant(x)
# return x
QConfig 配置错误
qconfig 使用错误可能导致模型未按照预期的方式量化,从而产生精度损失(比如:混用模板和 qconfig 属性两种设置方法)。这里主要检查每个算子的输入输出是否符合预期,在 model_check_result.txt 中查看:
-
dtype 是否与设置一致。
-
是否开启高精度输出。
Each layer out qconfig:
+---------------+-----------------------------------------------------------+---------------+---------------+----------------+-----------------------------+
| Module Name | Module Type | Input dtype | out dtype | ch_axis | observer |
|---------------+-----------------------------------------------------------+---------------+---------------+----------------+-----------------------------|
| quant | <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> | torch.float32 | qint8 | -1 | MovingAverageMinMaxObserver |
| conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint8 | qint8 | -1 | MovingAverageMinMaxObserver |
| relu | <class 'horizon_plugin_pytorch.nn.qat.relu.ReLU'> | qint8 | qint8 | qconfig = None | |
| dequant | <class 'horizon_plugin_pytorch.nn.qat.stubs.DeQuantStub'> | qint8 | torch.float32 | qconfig = None | |
+---------------+-----------------------------------------------------------+---------------+---------------+----------------+-----------------------------+
# 这里的检查结果显示所有模块都为 int8 量化,如果您配置了 int16,说明配置没有生效,需要检查 qconfig 的用法是否正确。
Weight qconfig:
+---------------+-------------------------------------------------------+----------------+-----------+---------------------------------------+
| Module Name | Module Type | weight dtype | ch_axis | observer |
|---------------+-------------------------------------------------------+----------------+-----------+---------------------------------------|
| conv | <class 'horizon_plugin_pytorch.nn.qat.conv2d.Conv2d'> | qint8 | 0 | MovingAveragePerChannelMinMaxObserver |
+---------------+-------------------------------------------------------+----------------+-----------+---------------------------------------+
除此以外,model_check_result.txt 中还会有异常 qconfig 提示(如存在异常 qconfig)。这里的内容为工具识别到的需要您再检查一下的 qconfig 配置,需要您结合实际场景查看是否符合预期,不一定就是错误的。如下方所列的 Fixed scale 的相关提示,此时您需要检查下该层 fixed scale 设置是否符合预期。
Please check if these OPs qconfigs are expected..
+-----------------+----------------------------------------------------------------------------+------------------------------------------------------------------+
| Module Name | Module Type | Msg |
|-----------------+----------------------------------------------------------------------------+------------------------------------------------------------------|
| sub[sub] | <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> | Fixed scale 3.0517578125e-05 |
+-----------------+----------------------------------------------------------------------------+------------------------------------------------------------------+
S100/S100P 混合精度调优
调优流程
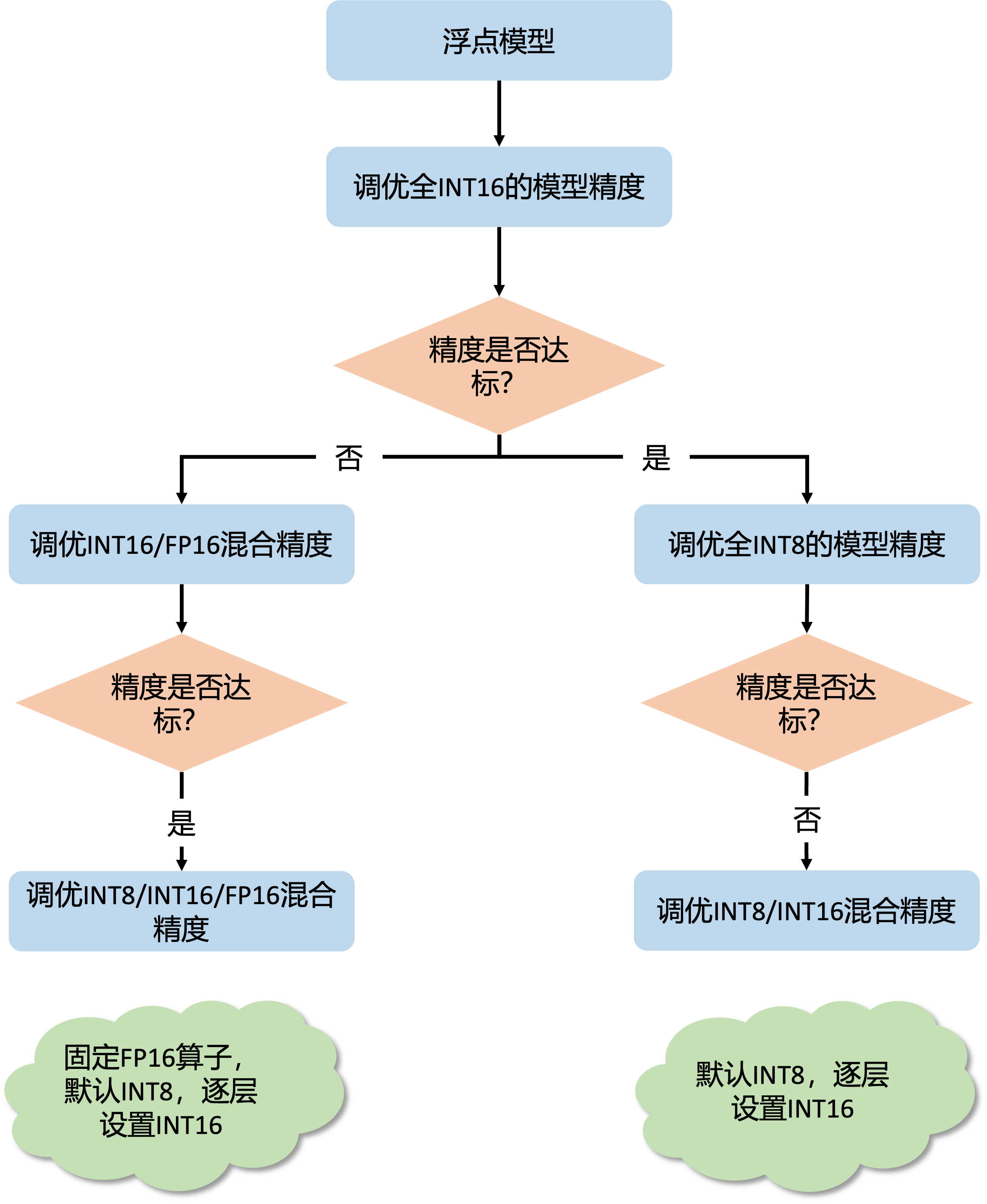
整个流程首先进行全 int16 精度调优,此阶段用于确认模型的精度上限,排查工具使用问题和量化不友好模块。
-
在确认全 int16 精度满足需求后,进行全 int8 精度调优。如果精度不达标则进行 int8 / int16 混合精度调优,在全 int8 的基础上逐步增加 int16 的比例,该阶段需要您在精度和性能间做权衡,在满足精度的前提下,找出性能尽可能好的量化配置。
-
如果全 int16 精度不满足需求,则进行 int16 / fp16 混合精度调优。理想情况下 int16 / fp16 混合精度调优可以解决所有精度问题。在此基础上进行 int8 / int16 / fp16 混合精度调优,固定所有 fp16 算子的配置,按照 1 中 int8 / int16 混合精度调优的方法调整 int16 算子比例。
基本调优手段
基本调优手段的目标是快速迭代,在全 int16 精度调优和全 int8 精度调优中,模型只是一个快速迭代的中间状态,一般仅使用基本调优手段。
而在混合精度调优中追求使用更少的高精度算子,需要按精度需求决定是否使用更加复杂的高级调优手段,这会带来更多的试错和迭代成本,但模型的精度和性能可以调得更好。
Calibration
-
调整校准 step。校准数据越多越好,但因为边际效应的存在,当数据量大到一定程度后,对精度的提升将非常有限。如果训练集较小,可以全部用来 calibration,如果训练集较大,可以结合 calibration 耗时挑选大小合适的子集,建议至少进行 10 - 100 个 step 的校准。
-
调整 batch size。一般 batch size 要尽可能大,如果数据噪声较大或模型离群点较多,可以适当减小。
-
使用推理阶段的前处理 + 训练数据进行校准。校准数据应接近真实分布,可以使用翻转这类数据增强,不要使用旋转,马赛克等会改变真实分布的数据增强方法。
QAT
-
调整学习率。
a. 初始学习率:取消 warmup,取消 learning rate decay 策略,使用不同的固定学习率(1e-3, 1e-4, ...)finetune 少量 step,并观察评测指标,取效果最好的作为初始学习率。如果浮点模型不同模块学习率不同,那么这里也要做对应尝试。
b. Scheduler:learning rate decay 策略与浮点对齐,但需要确保没有 warmup 类的策略,例如浮点 learning rate decay 策略为 cosine annealing,那么 qat 也应该使用 cosine annealing。
-
尝试固定和更新 input / output scale 两种策略。一般来说,校准模型精度较好时,固定 input / output scale 进行 QAT 训练可以取得更好的效果,精度较差时,则不能固定。具体使用哪种策略,没有明确指标可以参考,需要分别进行尝试。
-
训练 step 数一般不超过浮点训练的 20%,可结合训练的 loss 和评测结果酌情调整。
特别需要注意的点:
-
除上述需要调整的内容以外,其余 qat 训练配置与浮点训练对齐。
-
如果在浮点训练中使用了 freeze bn 的技巧,那么 qat 训练中需要将 qat mode 设置为 withbn。
from horizon_plugin_pytorch.qat_mode import QATMode, set_qat_mode
set_qat_mode(QATMode.WithBN)
注意
在 qat 调参的过程中,你可能会遇到无论怎么调参精度都不达标、nan 或 qat loss 明显异常的情况。可以按照如下步骤排查:
-
去掉 prepare 模型的步骤,用 qat pipeline finetune 浮点模型,排除训练 pipeline 的问题。
-
关掉 fake quant 进行 qat 训练,排除量化工具使用问题。qat 训练的精度应该与 finetune 浮点模型几乎一致。
from horizon_plugin_pytorch.quantization import set_fake_quantize, FakeQuantState
# 同样适用于排查 calibration 精度问题
set_fake_quantize(model, FakeQuantState._FLOAT)
- lr 设置为 0,进行 qat 训练,排除参数调整不到位的问题。qat 训练的精度应该与 calibration 精度几乎一致。
高级调优手段
高级调优手段一般需要花费较多时间不断进行尝试,因此建议您在对精度有较高要求时使用,包括如下几种方式可进行高级调优。
设置 Fixed Scale
模型中的某些地方很难依靠统计的方式获得最佳的量化 scale。常见的需要设置 fixed scale 的情况:算子的输出值域确定时需要设置 fixed scale。
比如:输入数据为速度 km / h,值域为 [0, 200], 对于 quantstub 而言,输出值域是固定的,需要将 scale 设置为 200 / 量化数值范围。之所以这么做是因为量化 scale 值是基于统计方法获取的,在正常的校准数据中,很难保证每一个样本都达到边界情况,统计方法为了消除离群点会使用滑动平均,导致得到的量化范围小于实际值。在上面输入数据为速度的例子中,如果不设置 fixed scale,那么统计出来的最大速度可能是大多数车辆的平均速度,导致所有超过这个速度的样本在输入时就产生较大的精度损失。您在这里可能很难识别所有需要设置 fixed scale 的情况,但在精度 debug 的逐层比较步骤中,将很容易发现此类问题。
下图中,输入 a 和 b 值域确定,输入 c 值域不确定,除 quantstub_c 和后一个 add 以外,其余算子均需要设置 fixed scale。
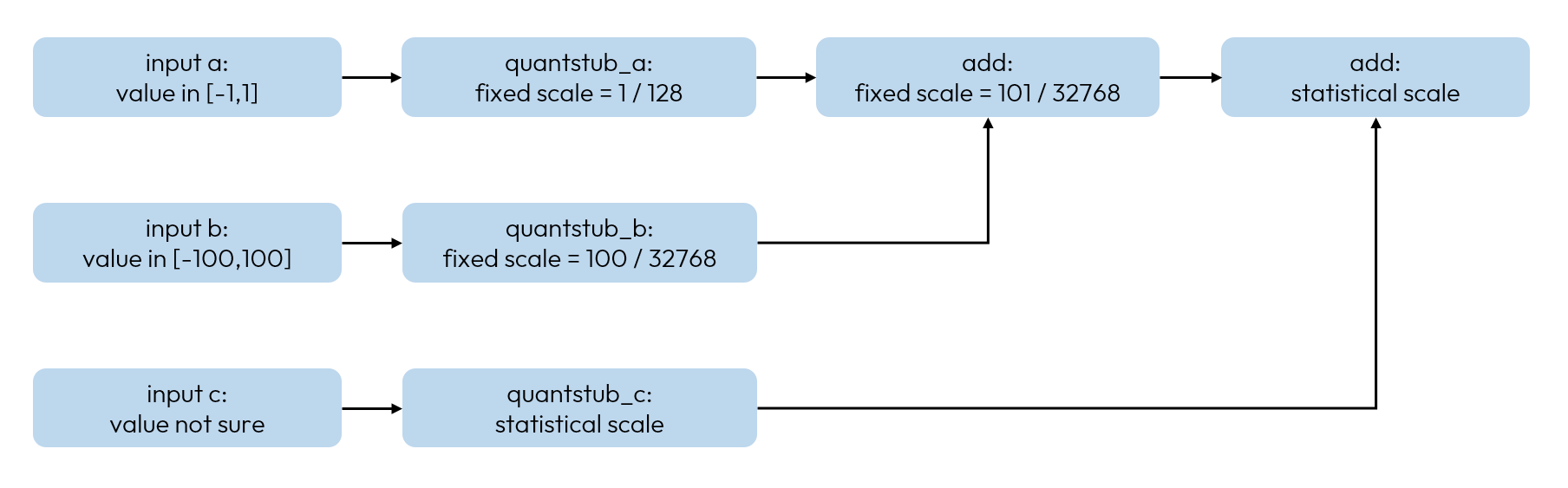
Calibration
尝试不同的校准方法。Plugin 支持多种校准方法,推荐尝试 min max / percentile / kl / mse / mix 这几种方法,调参经验见Calibration 指南。
QAT
-
调整 weight decay。weight decay 会影响模型中权重的数值范围,更小的数值范围更加量化友好。有时,只调整 qat 阶段的 weight decay 还不足以解决问题,需要调整浮点训练阶段的 weight decay。
-
调整数据增强。量化模型比浮点模型的学习能力更差,太强的数据增强会影响 qat 模型收敛,一般需要适当减弱数据增强。
分部量化
除了上述调优方法外,还可以使用分部量化定位精度问题。只建议在所有调优方法都无效的情况下再使用分部量化。
将模型某些部分的伪量化关闭,对比伪量化打开和关闭时的模型精度,定位这些部分的量化是否存在问题。可以使用类似二分查找的方法缩小范围,精确定位问题。
对于浮点计算,可以对比 fake cast 打开和关闭时的模型精度。
from horizon_plugin_pytorch.utils.quant_switch import GlobalFakeQuantSwitch
from horizon_plugin_pytorch.quantization.fake_cast import FakeCast
# head 不量化的例子
class Model(nn.Module):
def _init_(...):
def forward(self, x):
x = self.quant(x)
x = self.backbone(x)
x = self.neck(x)
GlobalFakeQuantSwitch.disable() # 关闭 fake quantization
FakeCast.disable() # 关闭 fake cast
x = self.head(x)
GlobalFakeQuantSwitch.enable() # 打开 fake quantization
FakeCast.enable() # 打开 fake cast
return self.dequant(x)
INT8 / INT16 混合精度调优 & INT16 / FP16 混合精度调优
混合精度调优的基本思路是在某一精度的基础上逐步增加更高精度算子的比例,直到达到精度需求。在 int8 / int16 混合精度调优中,以全 int8 模型为基础,逐步增加 int16 算子的数量。而在 int16 / fp16 混合精度调优中,则以全 int16 模型为基础,逐步增加 fp16 算子的数量。
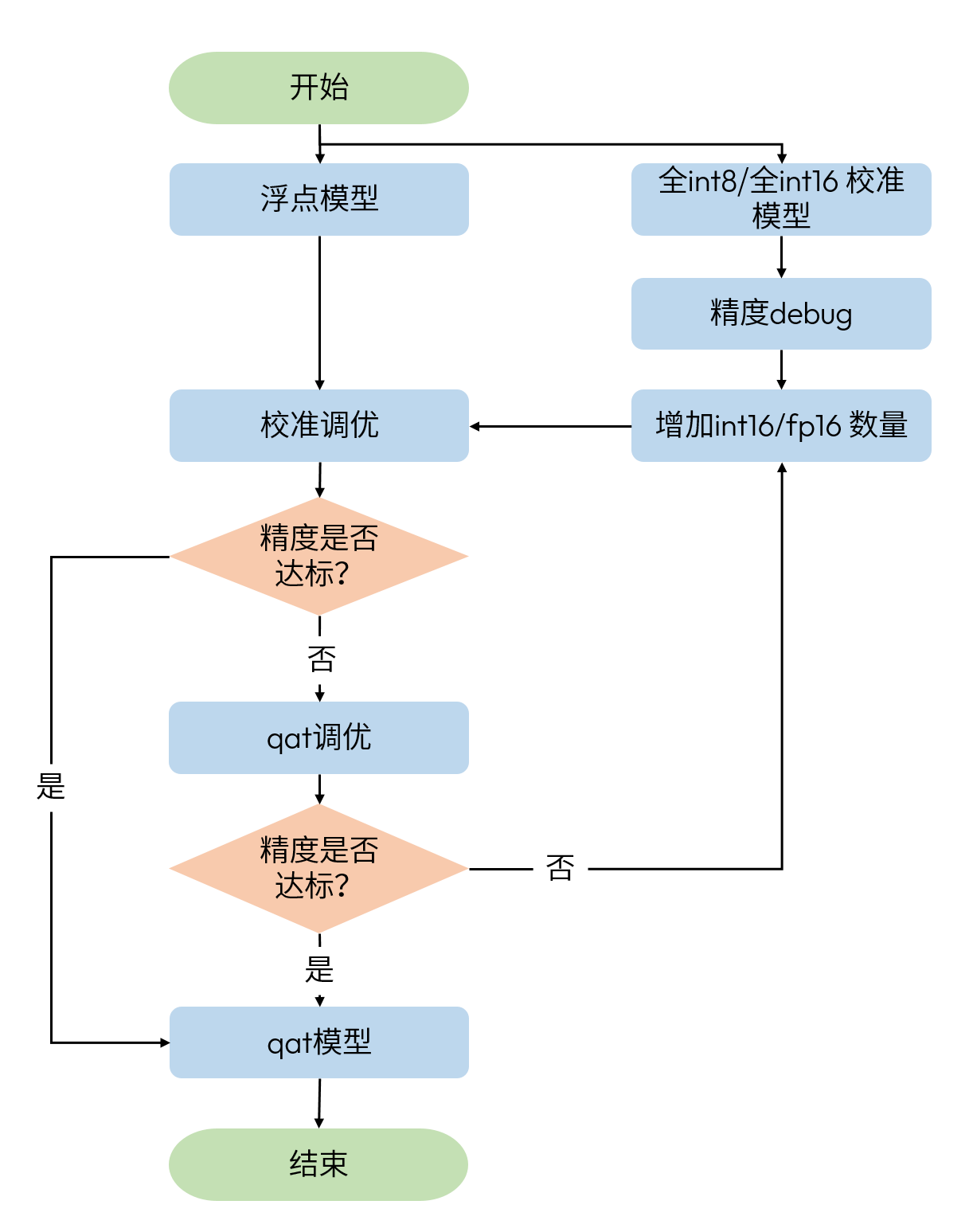
上图中的校准和 qat 调优可参考 基本调优手段 和 高级调优手段 章节,增加 int16 / fp16 的高精度算子数量依赖于精度 debug 工具产出的一系列 debug 结果。
qat 精度 debug 全部基于浮点模型和校准模型的对比,一般来说,不推荐您将浮点模型和 qat 模型进行对比,经过 qat 训练,浮点模型和 qat 模型已失去可比性,请先阅读 精度调优工具使用指南 章节了解相关背景。首先,提供数据集查找校准模型损失较大的 badcase,在 badcase 的基础上进行逐层比较并计算量化敏感度。
查找 Badcase
精度 debug 的全部操作都围绕 badcase 展开。您需要提供一个量化精度较差的样本集,此过程会遍历样本集,对比每一个样本在浮点模型和校准模型输出上的误差。一般情况下,不需要您提供误差的度量函数。
注意
从查找 badcase 开始,对比模型需要带上部分后处理逻辑(从原始后处理逻辑中删除或替换会使得模型输出完全失去可比性的操作)。举两个例子:
-
sigmoid 不能删除。落在 sigmoid 饱和域的数值对误差不敏感,但 0 附近的数值对误差非常敏感,删除 sigmoid 将不能正常反应不同定义域内的量化误差对精度的影响。
-
nms 需要删除。微小误差会导致 nms 结果完全不同,使得输出不能直接反映量化误差对精度的影响。
debug 工具已支持自动替换 sort / topk / argmax,除了这些算子,您需要检查模型和带上的后处理中是否还有类似的算子,将此算子之后的部分全部删除。
使用 debug 工具中的 auto_find_bad_case 接口查找 badcase,参考如下:
from horizon_plugin_profiler.model_profilerv2 import QuantAnalysis
# 1. 初始化量化分析对象
qa = QuantAnalysis(float_net, calibration_model, "fake_quant")
# 2. 查找 badcase,如果数据数量较多,可以指定 num_steps,只在部分数据中查找 badcase
qa.auto_find_bad_case(dataloader)
查找 badcase 完成后,查看结果文件,对于模型的每一个输出,在每一种误差度量下,debug 工具都会找一个最差的样本。在下面这个例子中,模型一共有 3 个输出,第一个表格表示每一个输出在每一种度量下的最差样本 index,第二个表格表示对应的误差是多少,第三个表格表示当前度量下,模型所有输出中误差最大的 badcase index。
The bad case input index of each output:
Name/Index COSINE L1 ATOL
------------ -------- ---- ------
0-0 4 1 1
0-1 14 1 1
0-2 12 9 9
The metric results of each badcase:
Name/Index COSINE L1 ATOL
------------ -------- --------- ---------
0-0 0.969289 0.996721 11.9335
0-1 0.974127 0.0404785 12.6742
0-2 0.450689 1.08771 20.821809
The bad case input index of the worst output:
metric dataloader index
-------- ------------------
COSINE 11
L1 17
ATOL 0
注意
在后续 debug 的过程中,我们可以针对与精度掉点相关的输出进行 debug。不同的模型输出需要使用不同的误差 metric,通常情况下,L1 / ATOL / COSINE 可以反应绝大部分问题。L1 和 ATOL 适用于 bbox 回归等需要反应绝对误差的任务,COSINE 适用于分类等需要反应整体分布误差的任务。
逐层比较
逐层比较会使用指定的 badcase 分别跑浮点模型和校准模型,并对比每一层的输出,对其进行统计并计算误差,可以使用 debug 工具中的 compare_per_layer 接口进行对比。compare_per_layer 适用于极为细致的精度问题分析,如果精度损失不明显,可以先跳过这一步,后面再结合敏感度结果做分析。
from horizon_plugin_profiler.model_profilerv2 import QuantAnalysis
# 1. 初始化量化分析对象
qa = QuantAnalysis(float_net, calibration_model, "fake_quant")
# 2. 查找 badcase,如果数据数量较多,可以指定 num_steps,只在部分数据中查找 badcase
qa.auto_find_bad_case(dataloader)
# 3. 使用 badcase 运行模型,获取每一层的信息
qa.run()
# 4. 逐层比较获取到的信息
qa.compare_per_layer()
逐层比较的结果可以通过生成的文本文件来查看。在文本文件中,可以从上至下查看从哪个算子开始,误差被放大。
+------+----------------------------------------+-----------------------------------------------------------------------------+-----------------------------------------------------------+---------------------------------------+---------------+-----------+------------+-----------------+--------------+------------+--------------+---------------+-------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+-----------------+-------------------+
| | mod_name | base_op_type | analy_op_type | shape | quant_dtype | qscale | Cosine | MSE | L1 | KL | SQNR | Atol | Rtol | base_model_min | analy_model_min | base_model_max | analy_model_max | base_model_mean | analy_model_mean | base_model_var | analy_model_var | max_atol_diff | max_qscale_diff |
|------+----------------------------------------+-----------------------------------------------------------------------------+-----------------------------------------------------------+---------------------------------------+---------------+-----------+------------+-----------------+--------------+------------+--------------+---------------+-------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+--------------------+-----------------+-------------------|
| 0 | backbone.quant | horizon_plugin_pytorch.quantization.stubs.QuantStub | horizon_plugin_pytorch.nn.qat.stubs.QuantStub | torch.Size([4, 3, 512, 960]) | qint16 | 0.0078125 | 0.9999999 | 0.0000000 | 0.0000000 | 0.0000000 | inf | 0.0000000 | 0.0000000 | -1.0000000 | -1.0000000 | 0.9843750 | 0.9843750 | -0.1114422 | -0.1114422 | 0.1048462 | 0.1048462 | 0.0000000 | 0.0000000 |
| 1 | backbone.mod1.0 | torch.nn.modules.conv.Conv2d | horizon_plugin_pytorch.nn.qat.conv_bn2d.ConvBN2d | torch.Size([4, 32, 256, 480]) | qint16 | 0.0003464 | 0.4019512 | 0.4977255 | 0.4296696 | 0.0115053 | -0.3768753 | 14.2325277 | 5343133.5000000 | -5.9793143 | -15.0439596 | 8.7436047 | 17.3419971 | 0.1503869 | 0.0484397 | 0.4336909 | 0.3707855 | 14.2325277 | 41088.2696619 |
| 2 | backbone.mod1.1 | torch.nn.modules.batchnorm.BatchNorm2d | torch.nn.modules.linear.Identity | torch.Size([4, 32, 256, 480]) | qint16 | 0.0003464 | 0.9999998 | 0.0000000 | 0.0000000 | 0.0000000 | inf | 0.0000000 | 0.0000000 | -15.0439596 | -15.0439596 | 17.3419971 | 17.3419971 | 0.0484397 | 0.0484397 | 0.3707855 | 0.3707855 | 0.0000000 | 0.0000000 |
| 3 | backbone.mod2.0.head_layer.conv.0.0 | torch.nn.modules.conv.Conv2d | horizon_plugin_pytorch.nn.qat.conv_bn2d.ConvBNReLU2d | torch.Size([4, 64, 256, 480]) | qint16 | 0.0004594 | 0.5790146 | 49.3001938 | 4.0790396 | 0.0415040 | 0.3848250 | 164.3788757 | 4046676.7500000 | -164.3788757 | 0.0000000 | 140.9307404 | 25.1951389 | -0.5375993 | 0.2460073 | 53.5661125 | 0.2699530 | 164.3788757 | 357789.3997821 |
| 4 | backbone.mod2.0.head_layer.conv.0.1 | torch.nn.modules.batchnorm.BatchNorm2d | torch.nn.modules.linear.Identity | torch.Size([4, 64, 256, 480]) | qint16 | 0.0004594 | 0.7092103 | 0.3265578 | 0.2332140 | 0.0003642 | 3.0239849 | 17.1071243 | 1.0000000 | -17.1071243 | 0.0000000 | 25.1951389 | 25.1951389 | 0.0127933 | 0.2460073 | 0.6568668 | 0.2699530 | 17.1071243 | 37235.6102222 |
| 5 | backbone.mod2.0.head_layer.conv.0.2 | torch.nn.modules.activation.ReLU | torch.nn.modules.linear.Identity | torch.Size([4, 64, 256, 480]) | qint16 | 0.0004594 | 1.0000001 | 0.0000000 | 0.0000000 | 0.0000000 | inf | 0.0000000 | 0.0000000 | 0.0000000 | 0.0000000 | 25.1951389 | 25.1951389 | 0.2460073 | 0.2460073 | 0.2699530 | 0.2699530 | 0.0000000 | 0.0000000 |
| 6 | backbone.mod2.0.head_layer.short_add | horizon_plugin_pytorch.nn.quantized.functional_modules.FloatFunctional.add | horizon_plugin_pytorch.nn.qat.conv_bn2d.ConvBNAddReLU2d | torch.Size([4, 32, 256, 480]) | qint16 | 0.0004441 | 0.5653002 | 1.6375992 | 0.4214573 | 0.0008538 | 1.6659310 | 39.9804993 | 1.0000000 | -39.9804993 | 0.0000000 | 19.6796150 | 19.6796150 | 0.0330326 | 0.4544899 | 2.4056008 | 0.5625318 | 39.9804993 | 90017.7454165 |
| 7 | backbone.mod2.0.head_layer.relu | torch.nn.modules.activation.ReLU | torch.nn.modules.linear.Identity | torch.Size([4, 32, 256, 480]) | qint16 | 0.0004441 | 1.0000000 | 0.0000000 | 0.0000000 | 0.0000000 | inf | 0.0000000 | 0.0000000 | 0.0000000 | 0.0000000 | 19.6796150 | 19.6796150 | 0.4544899 | 0.4544899 | 0.5625318 | 0.5625318 | 0.0000000 | 0.0000000 |
注意
当发现掉点的算子后,首先查看 base_model_min / base_model_max / analy_model_min / analy_model_max,确认极值是否产生较大误差。
-
min / max 产生较大误差:此时浮点模型该算子的输出范围应该大幅超过了校准得到的范围。查看该算子的 scale,以 dtype 和 scale 算出校准得到的最大值,比如:scale 为 0.0078,dtype 为 int8,那么最大值应为 0.0078 * 128 = 0.9984,再与 base_model_max 和 analy_model_max 进行对比。统计出的 scale 太小原因可能有:校准数据不合理(校准数据太少,分布偏差,产生的输出范围过小),未设置 fixed scale 导致,共享模块等。
-
min / max 未产生较大误差:同样以 1 中的方法计算校准最大值并与 base_model_max 和 analy_model_max 进行对比,确认此时浮点模型该算子的输出范围没有大幅超过校准得到的范围。此类精度问题可能由量化类型分辨率不足或数值范围过大导致。
a. 观察当前的量化 dtype 与数值范围是否匹配,一般最大值超过 10 则不建议使用 int8 量化。
b. 定位是什么原因导致校准统计出了较大的数值范围,可能是离群点或设置了不合理的数值。
计算量化敏感度
这一步会评估模型中的量化节点对精度的影响,可以使用 debug 工具中的 sensitivity 接口评估量化敏感度。具体的评估方法为,以 badcase 作为模型输入,分别将每一个量化节点打开,对比量化模型与浮点模型输出的误差,误差的度量标准与查找 badcase 时使用的一致。
from horizon_plugin_profiler.model_profilerv2 import QuantAnalysis
# 1. 初始化量化分析对象
qa = QuantAnalysis(float_net, calibration_model, "fake_quant")
# 2. 查找 badcase,如果数据数量较多,可以指定 num_steps,只在部分数据中查找 badcase
qa.auto_find_bad_case(dataloader)
# 3. 使用 badcase 运行模型,获取每一层的信息
qa.run()
# 4. 逐层比较获取到的信息
qa.compare_per_layer()
# 5. 计算量化敏感度
qa.sensitivity()
量化敏感度的结果中,敏感度排名越高的算子对模型精度影响越大,需要将其设置为更高的精度类型。
sensitive_type 列有 weight / activation 两种,分别表示只打开该算子的 weight 量化节点/输出量化节点的情况。
op_name sensitive_type op_type L1 quant_dtype
--------------------------------------------------------------------------------------------------------------- ---------------- -------------------------------------------------------------------------- -------- ------------
bev_stage2_e2e_dynamic_head.head.transformer.decoder.layers.5.cross_attn.quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 1.59863 qint8
bev_stage2_e2e_dynamic_head.head.transformer.decoder.layers.5.norm3.var_mean.pre_mean activation <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> 1.52816 qint16
bev_stage2_e2e_dynamic_head.head.ref_pts_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 1.16427 qint8
bev_stage2_e2e_dynamic_head.head.fps_quant activation <class 'horizon_plugin_pytorch.nn.qat.stubs.QuantStub'> 1.13563 qint8
bev_stage2_e2e_dynamic_head.head.transformer.decoder.mem_bank_layer.emb_fps_queue_add activation <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> 1.11997 qint8
bev_stage2_e2e_dynamic_head.head.transformer.decoder.mem_bank_layer.temporal_norm2.weight_mul activation <class 'horizon_plugin_pytorch.nn.qat.functional_modules.FloatFunctional'> 1.09876 qint8
注意
我们认为即使非常难量化的模型,也应当存在一些算子的量化敏感度是较低的,所以在正常的敏感度表中,敏感度应当是有高有低的,且最后几个算子的量化敏感度应当接近于 0。如果发现最后几个算子的误差仍然较大,那么考虑模型中是否存在没有去除干净的后处理,nms 等。
设置需要用到敏感度模板,用法详见 QConfig 详解 章节。若模型有多个输出,每个输出都会生成一个对应的敏感度表,您可以选取若干指标相差较大的输出所对应的敏感度表,设置敏感度模板。下面是 int8 / int16 混合精度调优中,设置 2 个输出敏感度表 int8 敏感度 top 20% int16 的例子。总的 int16 个数为两个表中 top 20% int16 算子的并集。之后不断调整 int16 的比例,直到找到满足精度需求的最少 int16 比例。
qat_model = prepare(
model,
example_inputs=example_input,
qconfig_setter=(
sensitive_op_calibration_8bit_weight_16bit_act_qconfig_setter(table1, ratio=0.2),
sensitive_op_calibration_8bit_weight_16bit_act_qconfig_setter(table2, ratio=0.2),
default_calibration_qconfig_setter,
)
)
qat_model = prepare(
model,
example_inputs=example_input,
qconfig_setter=(
sensitive_op_qat_8bit_weight_16bit_act_qconfig_setter(table1, ratio=0.2),
sensitive_op_qat_8bit_weight_16bit_act_qconfig_setter(table2, ratio=0.2),
default_qat_qconfig_setter,
)
)
输出较多的模型精调 int16 数量时,可以参考下面的经验进行调整:
-
二分调整比例。全部敏感度表按照同一比例进行设置,二分调整。精度达标以后,再针对单独的敏感度表减少高精度比例,同样可以使用二分的方式进行调整。
-
根据计算量进行调整。敏感度表的最后一列 flops 表示当前算子的计算量。一般来说,计算量与耗时正相关,将计算量大的算子数据类型设置为高精度可能对性能产生更大影响。在以优化性能为目标进行精调时,可以考虑从下往上将计算量大的算子保持低精度类型。比如下面的例子中,qat 精度可以满足需求的前提下,可以将 head.layers.0.camera_encoder.3 保持为 int8。
op_name sensitive_type op_type ATOL dtype flops
---------------------------------------------------------------- ---------------- -------------------------------------------------------------------------- ---------- ------- ------------------
head.layers.0.camera_encoder.0 activation <class 'horizon_plugin_pytorch.nn.qat.linear.LinearReLU'> 55.0853 qint8 21504(0.00%)
head.layers.0.camera_encoder.3 activation <class 'horizon_plugin_pytorch.nn.qat.linear.LinearReLU'> 46.2698 qint8 1998323712(5.28%)
head.layers.0.camera_encoder.1 activation <class 'horizon_plugin_pytorch.nn.qat.linear.LinearReLU'> 42.0853 qint8 21504(0.00%)
head.layers.0.camera_encoder.2 activation <class 'horizon_plugin_pytorch.nn.qat.linear.LinearReLU'> 37.0853 qint8 21504(0.00%)
...
目前暂不提供根据敏感度批量设置 fp16 的接口,需要根据 int16 的敏感度结果,使用 ModuleNameQconfigSetter 设置少量 fp16。下面是 int16 / fp16 混合精度调优中,设置 int16 敏感度 top1 fp16 的例子。
module_name_to_qconfig = {
"op_1": get_qconfig(in_dtype=torch.float16, weight_dtype=torch.float16, out_dtype=torch.float16),
}
qat_model = prepare(
model,
example_inputs=example_input,
qconfig_setter=(
ModuleNameQconfigSetter(module_name_to_qconfig),
calibration_8bit_weight_16bit_act_qconfig_setter,
)
)
qat_model = prepare(
model,
example_inputs=example_input,
qconfig_setter=(
ModuleNameQconfigSetter(module_name_to_qconfig),
qat_8bit_weight_16bit_act_qconfig_setter,
)
)
S100P 浮点算力有限,如果没有必须使用 fp16 的情况,尽量使用 int8 / int16 混合精度调优。当全 int16 模型无论如何也不能达到精度要求时,需要在全 int16 模型中引入少量 fp16 算子。
造成全 int16 模型精度不达标的两种情况:
-
需要使用双 int16:表现为量化敏感度表中某些算子在 activation 和 weight sensitive_type 下的敏感度都较高,设置 weight 和 activation 为 int16 后精度可以达标。由于 S100P 不支持 activation 和 weight 同时使用 int16,所以只能通过调整浮点模型的方式使两者其一变得更加量化友好。常用的方法有增大 weight decay,添加 norm 类算子等。
-
不需要使用双 int16:表现为量化敏感度表中某些算子在 activation 或 weight sensitive_type 下的敏感度较高,一般是 plugin 使用问题,或部分算子需要设置 fixed scale,通过精度 debug 可以发现具体问题。
INT8 / INT16 / FP16 混合精度调优
在进行 int8 / int16 / fp16 混合精度调优之前,您应该已经完成了 int16 / fp16 混合精度调优。复用 int16 / fp16 混合精度调优中 fp16 的配置,在 int8 / fp16 混合校准模型的基础上进行精度 debug。参考上一节的精度 debug 方法,不断调整 int16 的比例,直到找到满足精度需求的最少 int16 比例即可。
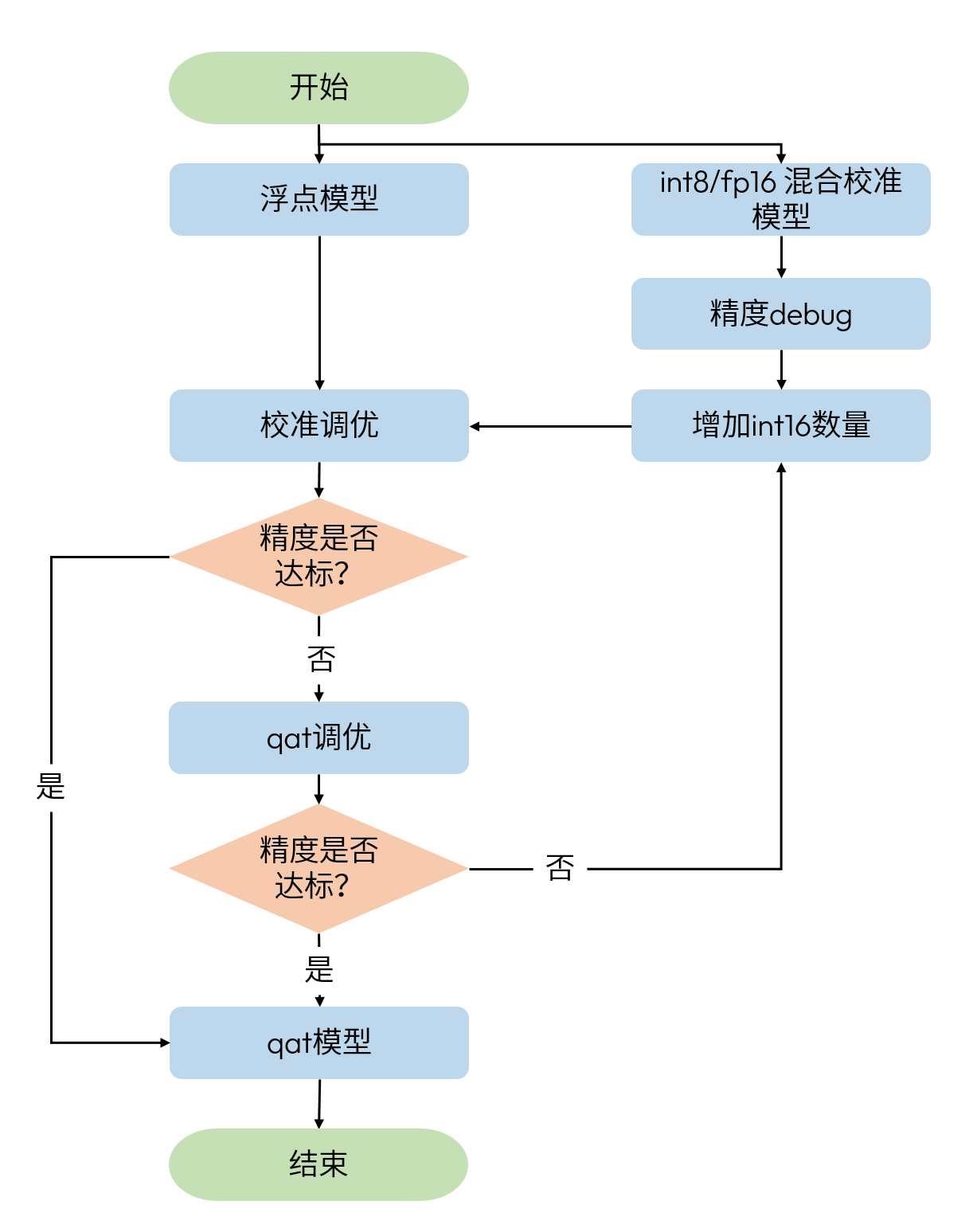
下面是 int8 / int16 / fp16 混合精度调优中,设置 int16 敏感度 top 1 fp16,int8 敏感度 top 20% int16 的例子。
module_name_to_qconfig = {
"op_1": get_qconfig(in_dtype=torch.float16, weight_dtype=torch.float16, out_dtype=torch.float16),
}
qat_model = prepare(
model,
example_inputs=example_input,
qconfig_setter=(
ModuleNameQconfigSetter(module_name_to_qconfig),
sensitive_op_8bit_weight_16bit_act_calibration_setter(table, ratio=0.2),
default_calibration_qconfig_setter,
)
)
qat_model = prepare(
model,
example_inputs=example_input,
qconfig_setter=(
ModuleNameQconfigSetter(module_name_to_qconfig),
sensitive_op_8bit_weight_16bit_act_qat_setter(table, ratio=0.2),
default_qat_qconfig_setter,
)
)
S600 混合精度调优
S600 有更强的浮点算力,支持非 gemm 算子 FP16 运算。大部分情况下,您只需设置非 gemm 算子 FP16,仅调整 gemm 算子(conv/convtranspose/linear/matmul 等)的 int8/int16 比例,就能得到一个精度达标的量化模型。因此,精度调优流程也得到了简化。调优手段和精度调优工具使用和 S100/S100P 混合精度调优一样,不再赘述。
调优流程
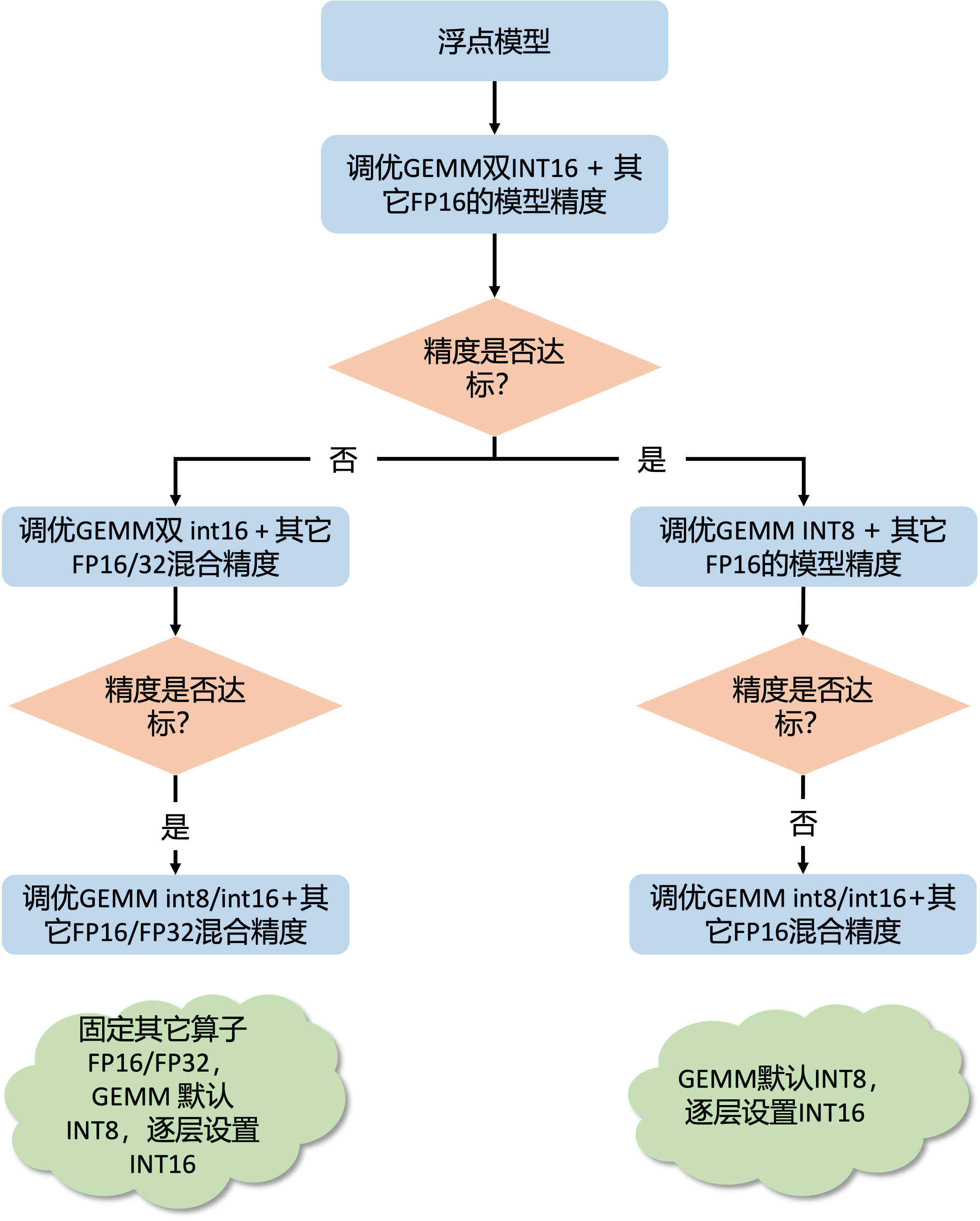
和 S100/S100P 混合精度调优流程类似,S600 混合精度调优流程也是从一个相对高精度的配置开始。我们推荐您从 gemm 算子输入双 int16 + 其它算子 FP16,开始混合精度调优。
-
确认 gemm 算子输入双 int16 + 其它算子 FP16 配置满足精度需求后,保持其它算子 FP16,进行 gemm 算子输入 int8 精度调优。如果精度不达标则进行 gemm 算子输入 int8 / int16 混合精度调优,在全 int8 的基础上逐步增加 int16 的比例,该阶段需要您在精度和性能间做权衡,在满足精度的前提下,找出性能尽可能好的量化配置。
-
如果 gemm 算子输入双 int16 + 其它算子 FP16 配置精度不满足需求,保持 gemm 算子输入双 int16,对非 gemm 类算子进行针对性处理,处理方式参考下方描述。然后在此基础上进行 gemm 算子输入 int8 精度调优,固定其它算子 fp16 和针对性处理的配置,按照 1 中 int8 / int16 混合精度调优的方法调整 gemm 算子输入 int16 的比例。
gemm 输入双 int16 + 其它算子 FP16 调优
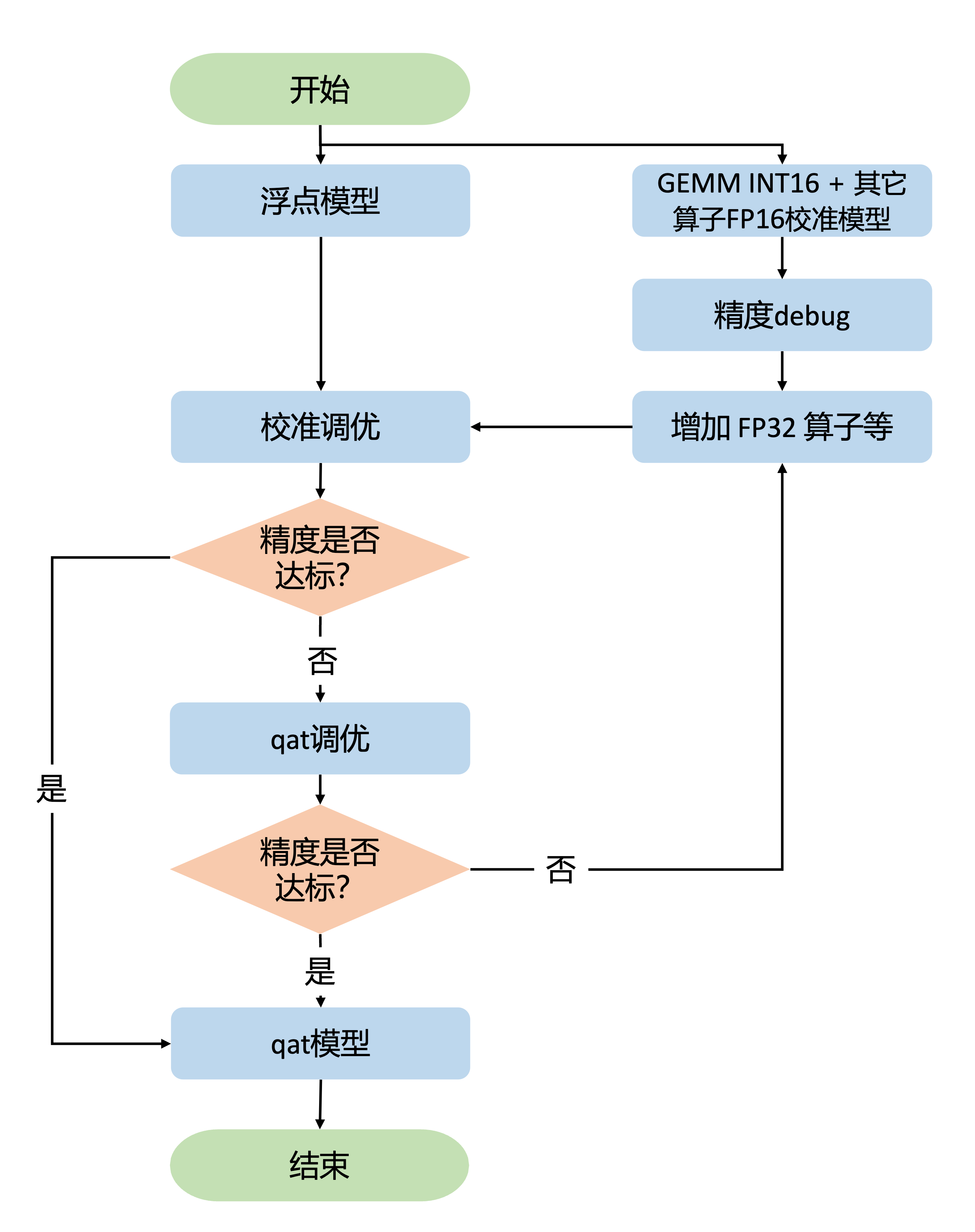
QconfigSetter 配置如下:
from horizon_plugin_pytorch.quantization import prepare, PrepareMethod, get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
setter = QconfigSetter(
reference_qconfig=get_qconfig(),
templates=[
ModuleNameTemplate({"": torch.float16}), # 全部算子配置为 float16 输出
ConvDtypeTemplate(input_dtype=qint16, weight_dtype=qint16), # conv 的 input 和 weight 配置为 int16
MatmulDtypeTemplate(input_dtypes=qint16), # matmul 两个输入均配置为 int16
],
)
qat_model = prepare(
model,
example_inputs=example_inputs,
qconfig_setter=setter,
method=PrepareMethod.JIT_STRIP,
)
当前配置不满足精度需求时,同样依赖精度调优工具产出的一系列 debug 结果。观察敏感度排序靠前的算子,有两种情况:
-
gemm 算子输入双 int16 精度不达标。对于 gemm 算子,输入双 int16 可以解决绝大部分 case。若存在 gemm 算子输入 int16 但是其输入敏感度依然靠前,优先考虑输入是否需要设置固定 scale。
-
非 gemm 算子 FP16 精度不达标。相比 int16,FP16 可表示的数值范围更大,相应的,牺牲了一些数值表示精度。目前识别到的 FP16 精度不够的 case 主要有
-
坐标相关的计算,如 gridsample 算子的 grid 输入。坐标的数值精度影响采样点的选择,采样点稍微偏一点,对最后的结果可能也有较大影响。因此,坐标相关的计算推荐使用 int16,如有必要,可以设置固定 scale;
-
线性变换的算子,如 mul 等,可以在变换前后放缩。典型的如 norm 类算子,中间的 mul 输出数值范围特别大,会超过 FP16 的数值范围导致截断。此时建议对算子输入做缩放,乘以一个系数缩小输入范围,框架中已经对 layernorm 算子 FP16 配置自动做了缩放处理。若碰到其他类似的 case,也能考虑使用缩放的方式进行处理;
-
非线性变换的算子,如 sigmoid 等。这类算子输入输出缩放后,无法等价恢复成缩放前数值。如 sigmoid 的输入缩放后,sigmoid 算子的输出无法恢复到输入缩放前对应的数值,此时我们建议您尝试使用 FP32。
注意
如果没有必须使用 fp32 的情况,我们建议您尽量使用 int8 / int16 / fp16 混合精度调优。
gemm 输入 int8/int16 + 其它算子 FP16 调优
在进行 gemm 输入 int8/int16 + 其它算子 FP16 调优之前,您应该已经完成了 gemm 输入双 int16 + 其它算子 FP16 的混合精度调优。复用 gemm 输入双 int16 + 其它算子 FP16 配置中的达标配置或改动,在 gemm 输入 int8 + 其它算子 FP16 的配置上进行精度 debug。参考上一节的精度 debug 方法,不断调整 gemm 算子 int16 的比例,直到找到满足精度需求的最少 int16 比例即可。
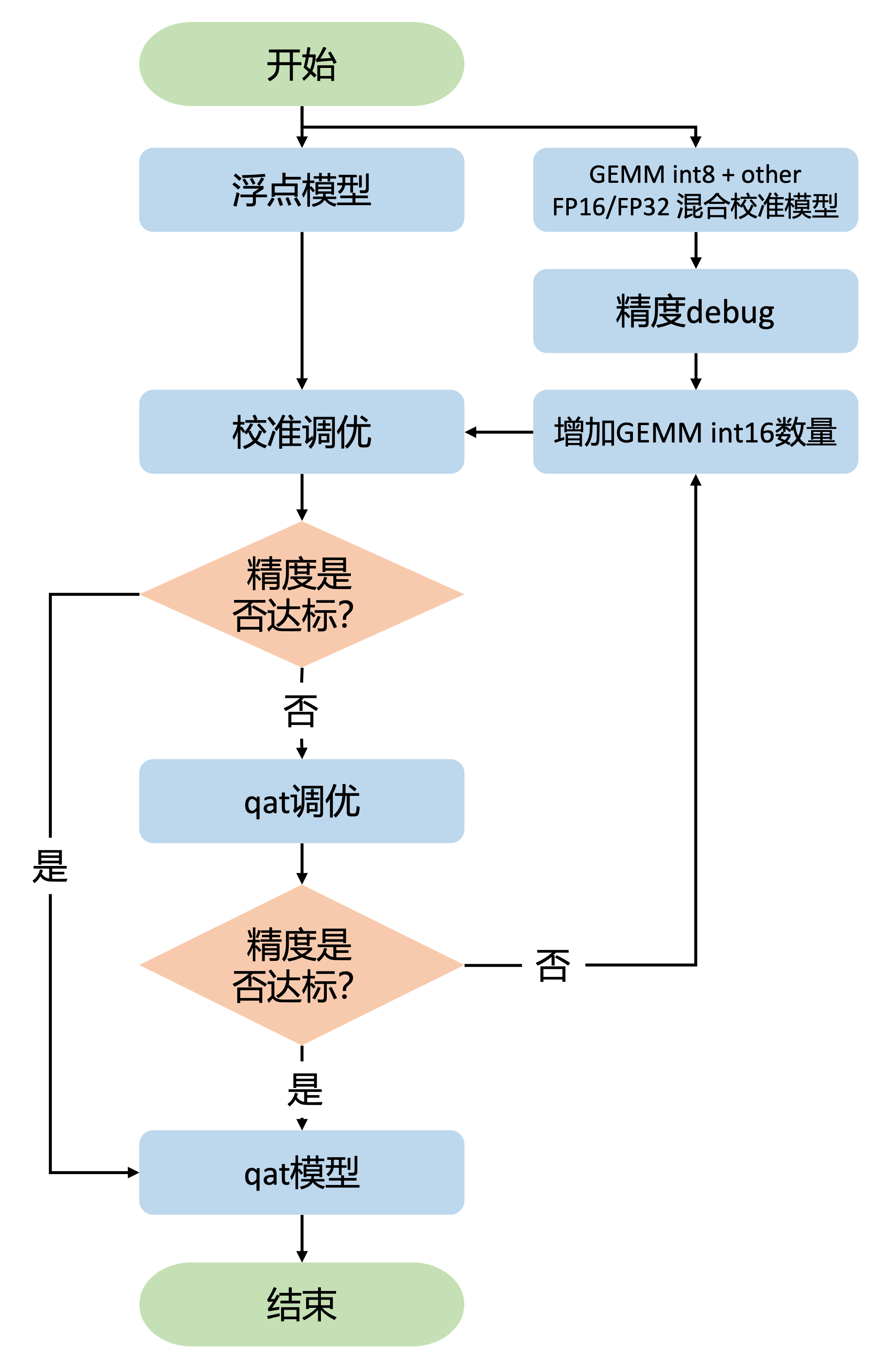
QconfigSetter 配置如下:
from horizon_plugin_pytorch.quantization import prepare, PrepareMethod, get_qconfig
from horizon_plugin_pytorch.quantization.qconfig_setter import *
setter = QconfigSetter(
reference_qconfig=get_qconfig(),
templates=[
ModuleNameTemplate({"": torch.float16}), # 全部算子配置为 float16 输出
ConvDtypeTemplate(input_dtype=qint8, weight_dtype=qint8), # conv 的 input 和 weight 配置为 int8
MatmulDtypeTemplate(input_dtypes=qint8), # matmul 两个输入均配置为 int8
SensitivityTemplate( # 若敏感度较高的 feat 或 weight 配置为 int8,则将其修改为 int16
sensitive_table=...,
topk_or_ratio=...,
),
],
)
qat_model = prepare(
model,
example_inputs=example_inputs,
qconfig_setter=setter,
method=PrepareMethod.JIT_STRIP,
)