模型量化与编译
转换模型阶段会完成浮点模型到地平线板端可部署模型的转换,经过这个阶段,您将得到一个可以在地平线计算平台上运行的模型。在进行转换之前,请确保已经顺利通过了 验证模型 小节的过程。
模型转换期间会完成模型优化和校准量化等重要过程,校准需要依照模型预处理要求准备校准数据,您可以参考 数据准备-模型校准集准备 章节内容对校准数据进行预先准备。
使用hb_compile工具转换模型
模型转换过程使用 hb_compile 工具完成,工具的使用方法及相关的具体配置、参数请参考 模型量化编译 章节。
转换内部过程解读
模型转换完成浮点模型到地平线板端可部署模型的转换。 为了使得这个模型能快速高效地在嵌入式端运行,模型转换重点作用于 输入数据处理 和 模型优化编译 两个阶段,本节会依次围绕这两个重点问题展开。
输入数据处理 方面地平线的边缘计算平台会为某些特定类型的输入通路提供硬件级的支撑方案,但是这些方案的输出不一定符合模型输入的要求。
例如视频通路方面就有视频处理子系统,为采集提供图像裁剪、缩放和其他图像质量优化功能,这些子系统的输出往往是yuv420格式图像,而我们的算法模型往往是基于bgr/rgb等一般常用图像格式训练得到的。
地平线针对此种情况提供的固定解决方案是,每个转换模型都提供两份输入信息描述,一份用于描述原始浮点模型输入(input_type_train 和input_layout_train),另一份则用于描述我们需要对接的边缘平台输入数据(input_type_rt)。
图像数据的mean/scale也是比较常见的操作,显然yuv420等边缘平台数据格式不再适合做这样的操作,因此,我们也将这些常见图像前处理固化到了模型中。经过以上两种处理后,转换产出的模型的输入部分将变成如下图状态。

上图中的数据排布就只有NCHW和NHWC两种数据排布格式,N代表数量、C代表channel、H代表高度、W代表宽度,两种不同的排布体现的是不同的内存访问特性。在TensorFlow模型中,NHWC格式较常用,而Caffe模型中就都使用NCHW格式,地平线平台不会限制使用的数据排布,但是有一条要求:input_layout_train 必须与原始模型的数据排布一致,正确的数据排布指定是顺利解析数据的基础。
模型优化编译 包括模型解析、模型优化、模型校准与量化、模型编译几个重要阶段,其内部工作过程如下图所示。
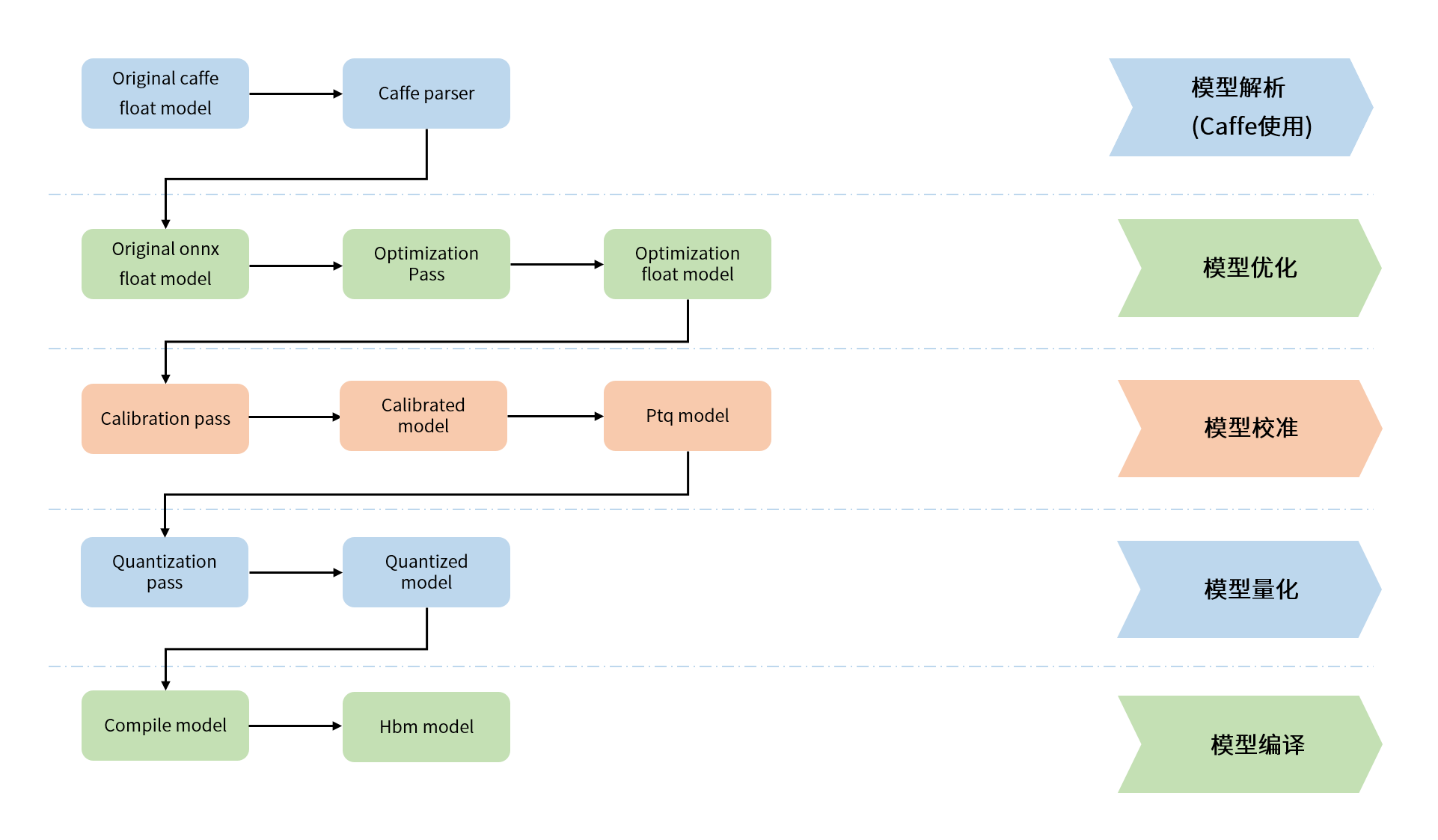
-
模型解析阶段 对于Caffe浮点模型会完成到ONNX浮点模型的转换,此阶段会对未命名的node/tensor进行算子命名(名称唯一), 产出一个
original_float_model.onnx,这个ONNX模型计算精度是float32。 -
模型优化阶段 实现模型的一些适用于地平线平台的算子优化策略,例如BN融合到Conv等。 此阶段的产出是一个
optimized_float_model.onnx,这个ONNX模型的计算精度仍然是float32,经过优化后不会影响模型的计算结果。 -
模型校准阶段 会使用您提供的校准数据来计算必要的量化参数,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中, 此阶段的产出是
calibrated_model.onnx,校准后还会进行一些操作,此过程的产出是ptq_model.onnx。 -
模型量化阶段 会使用地平线模型编译器,使用模型校准阶段生成的模型(ptq_model.onnx),根据您的前处理配置(包括input_type_rt到input_type_train的色彩转换,mean/scale的处理等)进行模型量化。 此阶段的产出是一个
quantized_model.bc。使用这个模型可以评估到模型量化带来的精度损失情况。 如果模型量化过程中存在移除输入/输出端的节点的情况,生成物中还会保存quantized_removed_model.bc。 此种场景下,如后续需进行一致性对比,我们建议您使用此HBIR模型与最终生成的hbm模型进行对比。
请注意,当input_type_rt为nv12时,对应 quantized.bc 的输入layout为NHWC。
- 模型编译阶段 会使用地平线模型编译器,将量化模型转换为地平线平台支持的计算指令和数据,这个阶段的产出一个*.hbm模型,这个hbm模型是后续将在地平线边缘嵌入式平台运行的模型,也就是模型转换的最终产出结果。
转换结果解读
本节将依次介绍模型转换成功状态的解读、转换不成功的分析方式。
确认模型转换成功,需要您从节点和输出Tensor的相似度信息、 compile 状态信息和 working_dir 中存储的转换产出物三个方面确认。
相似度信息
相似度信息存在于 compile 的控制台输出内容中,转换成功后也会同步保存至compile命令执行路径下面的log文件内,名称为 hb_compile.log,其内容形式如下:
上面列举的输出内容中:
-
Node、NodeType表示节点名称、类型。
-
ON表示节点执行的device。
-
TensorName表示输出Tensor名称。
-
Threshold是每个层次的校准阈值,用于异常状态下向地平线技术支持反馈信息,正常状况下不需要关注。
-
Calibrated Cosine表示优化后模型(optimized_float_model.onnx)与校准后模型(calibrated_model.onnx)对应节点(Node)/输出Tensor(Output Tensor)的余弦相似度结果。
-
Quantized Cosine表示优化后模型(optimized_float_model.onnx)与模型量化后生成的定点模型(quantized_model.bc)对应节点(Node)/输出Tensor(Output Tensor)的余弦相似度结果。
-
Output Data Type表示节点的输出数据类型,取值范围为['si8', 'si16', 'si32', 'si64', 'ui8', 'ui16', 'ui32', 'ui64', 'f32']。
需要您特别注意的是,余弦相似度只是指明量化后数据稳定性的一种参考方式,对于模型精度的影响不存在明显的直接关联关系。一般情况下,输出节点的相似度低于0.8就有了较明显的精度损失,当然由于与精度不存在绝对的直接关联,完全准确的精度情况还需要您参考 模型精度分析 的介绍。
compile状态信息
compile 状态信息方面,转换成功后将在控制台输出模型的依赖及参数信息,包括:
-
model deps info:模型编译过程中所依赖的工具版本。
-
model_parameters info:模型编译配置文件中的模型参数组信息。
-
input_parameters info:模型编译配置文件中的输入信息参数组信息。
-
calibration_parameters info:模型编译配置文件中的校准参数组信息。
-
compiler_parameters info:模型编译配置文件中的编译参数组信息。
-
memory info:模型编译过程各个过程中的内存占用相关信息。
转换产出物
转换产出存放在转换配置参数 working_dir 指定的路径中,成功完成模型转换后,您可以在该目录下得到以下文件(*部分是您通过转换配置参数 output_model_file_prefix 指定的内容):
-
*_original_float_model.onnx
-
*_optimized_float_model.onnx
-
*_calibrated_model.onnx
-
*_ptq_model.onnx
-
*_quantized_model.bc
-
*_quantized_removed_model.bc(存在移除输入/输出端的节点的情况)
-
*.hbm
-
*_advice.json
-
*_quant_info.json
-
*_node_info.csv
-
*.html
-
*.json
-
hb_compile.log
转换产出物解读 介绍了每个模型产出物的用途。 不过在上板运行前,我们强烈建议您完成 模型性能分析 和 模型精度分析 章节介绍的性能&精度评测过程,避免将模型转换问题延伸到后续嵌入式端。
如果以上验证模型转换成功的三个方面中,有任一个出现缺失都说明模型转换出现了错误。一般情况下,compile 工具会在出现错误时将错误信息输出至控制台,例如我们在Caffe模型转换时不配置 prototxt 和 caffe_model 参数,工具给出如下提示。
如果以上步骤不能帮助您发现问题,欢迎在 地平线开发者社区 提出您的问题,我们将为您提供支持。
转换产出物解读
上文提到模型成功转换的产出物,本节将介绍每个产出物的用途:
-
*_original_float_model.onnx:产出过程可以参考 转换内部过程解读 的介绍,这个模型计算精度与转换输入的原始浮点模型是一模一样的。一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
-
*_optimized_float_model.onnx:产出过程可以参考 转换内部过程解读 的介绍,这个模型经过一些算子级别的优化操作,常见的就是算子融合。通过与original_float模型的可视化对比,您可以明显看到一些算子结构级别的变化,不过这些都不影响模型的计算精度。一般情况下,您不需要使用这个模型,在转换结果出现异常时,如果能把这个模型提供给地平线的技术支持,将有助于帮助您快速解决问题。
-
*_calibrated_model.onnx:产出过程可以参考 转换内部过程解读 的介绍,这个模型是模型转换工具链将浮点模型经过结构优化后,通过校准数据计算得到的每个节点对应的量化参数并将其保存在校准节点中得到的中间产物。
-
*_ptq_model.onnx:产出过程可以参考 转换内部过程阶段 的介绍,这个模型是模型转换工具链对校准得到的模型进行预量化后的产物。
-
*_quantized_model.bc:产出过程可以参考 转换内部过程解读 的介绍,这个模型已经完成了校准和量化过程,量化后的精度损失情况可以从这里查看。这个模型是精度验证过程中必须要使用的模型,具体使用方式请参考 模型精度分析 部分的介绍。
-
*_quantized_removed_model.bc:产出过程可以参考 转换内部过程解读 的介绍,模型量化过程中如存在移除输入/输出端的节点的情况,会自动保存此移除节点的HBIR模型。此种场景下,如后续需进行一致性对比,我们建议您使用此HBIR模型与最终生成的hbm模型进行对比。
-
*.hbm:可以用于在地平线计算平台上加载运行的模型, 配合 模型推理应用开发指导 部分介绍的内容,您就可以将模型快速在计算平台上部署运行。不过为了确保模型的性能与精度效果是符合您的预期的,我们强烈建议完成 模型性能分析 和 模型精度分析 介绍的性能和精度分析过程后再进入到应用开发和部署。
-
*_advice.json:文件内保存了模型编译过程中,地平线模型编译器op checker打印的结果。
-
*_quant_info.json:文件内记录了算子的校准量化信息。
-
*_node_info.csv:文件内保存了成功后算子的余弦相似度等信息的结果,与hb_compile成功执行后控制台输出的相似度信息相同。
-
*.json:模型的静态性能评估文件。
-
*.html:模型的静态性能评估文件(可读性更好)。
-
hb_compile.log:编译产生的log文件。