关键概念
-
原始浮点模型
指您通过TensorFlow/PyTorch等等DL框架训练得到的可用模型,这个模型的计算精度为float32。
-
板端部署HBM模型
是一种适合在地平线计算平台上运行的模型格式,能够支持模型同时在ARM CPU和BPU上执行。 由于在BPU上的运算速度会远大于CPU上的速度,因此会尽可能的将算子放在BPU上运算。对于BPU上暂时不支持的算子,则会放在CPU上进行运算。
-
算子
深度学习算法由计算单元组成,我们称这些计算单元为算子(Operator,也称op)。 算子是一个函数空间到函数空间上的映射,同一模型中算子名称是唯一的,但是同一类型的算子可以存在多个。 如:Conv1、Conv2,是两个算子类型相同的不同算子。
-
模型转换
指的是将原始浮点模型或符合要求的onnx模型转换为地平线板端可部署模型的过程。
-
模型量化
目前工业界最有效的模型优化方法之一,量化是指定点与浮点等数据之间建立一种数据映射关系,使得以较小的精度损失代价获得了推理性能收益,可简单理解为用"低比特"数字表示FP32等数值,如FP32-->INT8可以实现4倍的参数压缩,在压缩内存的同时可以实现更快速的计算。
-
Quantize节点用于将模型float类型的输入数据量化至int8类型,其计算公式如下:
round(x)实现浮点数的四舍五入。clamp(x)函数实现将数据钳位在-128~127之间的整数数值。scale为量化比例因子。zero_point为非对称量化零点偏移值,对称量化时zero_point = 0。
C++的参考实现如下:
-
Dequantize节点则用于将模型int8或int32类型的输出数据反量化回float或double类型,其计算公式如下:
C++的参考实现如下:
-
-
PTQ
即训练后量化方案,先训练浮点模型,然后使用校准图片计算量化参数,将浮点模型转为量化模型的量化方法。更详细的介绍可参考 PTQ、QAT简介 章节。
-
QAT
即量化感知训练方案,在浮点训练的时候,就先对浮点模型结构进行干预,使得模型能够感知到量化带来的损失,减少量化损失精度的方案。更详细的介绍可参考 PTQ、QAT简介 章节。
-
张量
张量,也称Tensor,具备统一数据类型的多维数组,作为算子计算数据的容器,包含输入输出数据。 张量具体信息的载体,包含张量数据的名称、shape、数据排布、数据类型等内容。
-
数据排布
深度学习中,多维数据通过多维数组(张量)进行存储,通用的神经网络特征图通常使用四维数组(即4D)格式进行保存,即以下四个维度:
- N:Batch数量,如图片的数量。
- H:Height,图片的高度。
- W:Width,图片的宽度。
- C:Channel,图片的通道数。
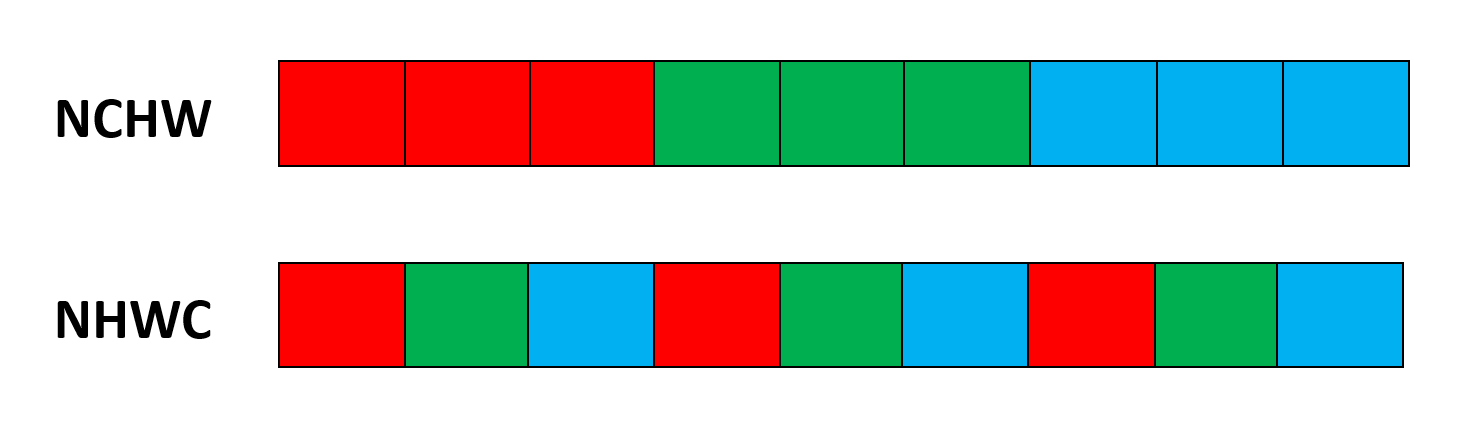
但是数据只能线性存储,因此四个维度有对应的顺序,不同的数据排布(format)方式,会显著影响计算性能。 常见的数据存储格式有NCHW和NHWC两种:
- NCHW:将同一通道的所有像素值按顺序进行存储。
- NHWC:将不同通道的同一位置的像素值按顺序进行存储。
如下图所示:
-
数据类型
下文常用到的图片数据类型包括rgb、bgr、gray、yuv444、nv12、featuremap。
- rgb、bgr和gray都是比较常见的图像格式,每个数值都采用UINT8表示。
- yuv444也是一种常见的图像格式,它的每个数值都采用UINT8表示。
- nv12是常见的yuv420图像格式,每个数值都采用UINT8表示。
- featuremap适用于以上列举格式不满足您需求的情况,此type每个数值采用float32表示。例如雷达和语音等模型处理就常用这个格式。
-
Batch和Batch Size
模型训练过程中每一轮迭代所使用的一批训练样本集,这个样本集我们称之为Batch,而Batch Size指的就是在每一轮迭代中,模型处理的样本数量。
-
余弦相似度
精度比对算法之一,计算结果取值范围为[-1,1],比对的结果如果越接近1,表示两者的值越相近,越接近-1意味着两者的值越相反。
-
Stride
跨距(Stride)是指图像储存在内存中时,每一行所占空间的实际大小。 计算机的处理器大都为32位或64位,因此处理器一次读取到的完整数据量最好为4字节或8字节的倍数,若为其他数值,则计算机需要进行专门处理,从而导致运行效率的降低。 为了能让计算机高效处理图像,通常会在原本数据的基础上,填充一些额外的数据以做到4字节或8字节对齐。对齐的操作又叫Padding,实际的对齐规则取决于具体的软硬件系统。
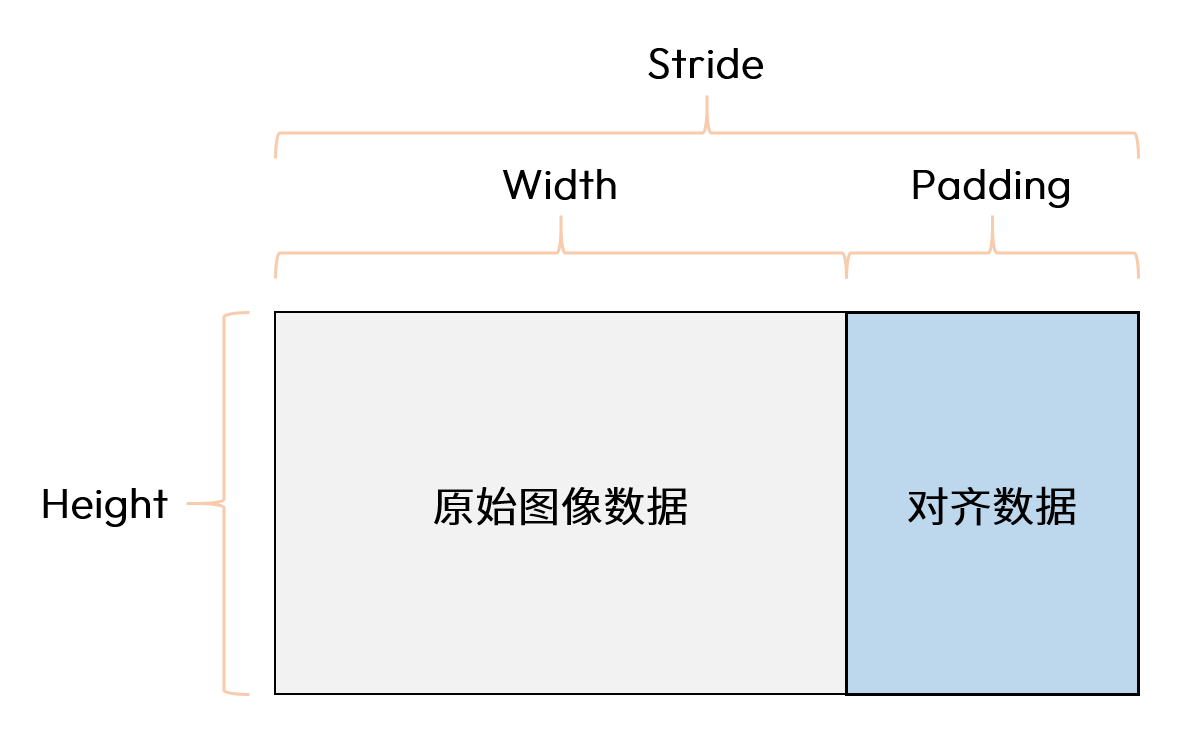
假设我们有一张8位深的灰度图,高(Height)为20像素,宽(Width)为30像素,那么该图像每行的有效数据为30字节,如果计算机的对齐规则是8字节,那么对齐后图像的跨距为32字节,此时每行需要Padding的数据量为2字节。
-
校准数据集
训练后量化(PTQ)场景中,做前向推理使用的数据集。该数据集的分布代表着所有数据集的分布,获取校准集时应该具有代表性。 如果数据集不是模型匹配的数据集或者代表性不够,则根据校准集计算得到的量化因子,在全数据集上表现较差,量化损失大,量化后精度低。
-
BPU架构与计算平台对应关系
计算平台 S100 S100P S600 BPU 架构 nash-e nash-m nash-p
还有更多针对文档中缩略词的介绍,请您参考 常用缩略语 章节的介绍。