PTQ转换原理及流程
概览
模型从训练到转换再到在开发板运行的过程如下图所示:
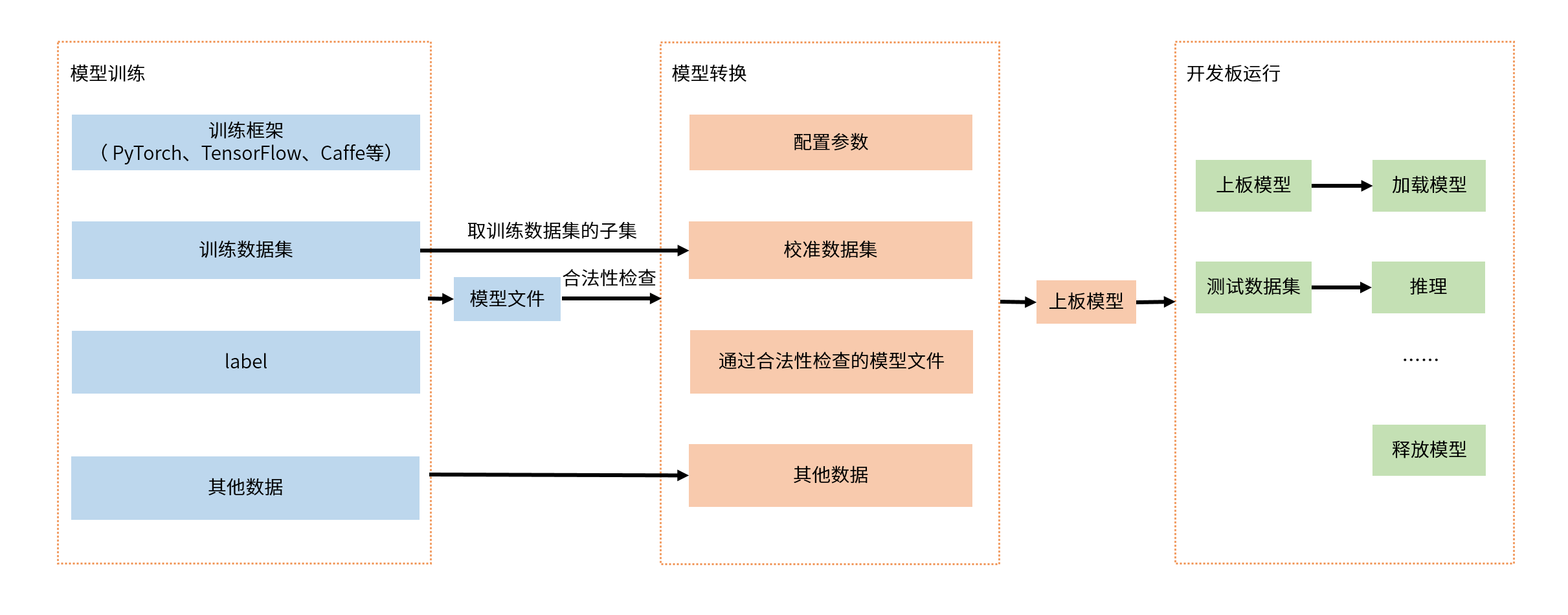
模型训练,指使用TensorFlow、PyTorch、Caffe等公开深度学习框架得到可用模型的过程,通过训练得到的可用模型将作为模型转换阶段的输入。 工具链本身不会提供训练相关的库或工具,具体支持的公开学习框架可以参考 浮点模型准备 章节中的说明。
模型转换,本阶段以模型训练得到的浮点模型为输入,通过模型结构优化、模型校准量化、模型编译等重要步骤,将浮点模型转换为可以在地平线计算平台高效运行的模型。 具体使用请参考 模型量化和编译 章节中的说明。
嵌入式应用开发,工具链支持了在X86仿真环境和真实嵌入式环境的应用开发能力,在不方便使用开发板的情况下,您在仿真环境完成程序的调试和计算结果的验证。 为了降低仿真验证的代价,工具链提供的仿真库接口与嵌入式接口完全一致,只是采用了不同的编译配置。 具体使用方式请参考 模型推理应用开发指导 章节中的说明。
下面为您详细介绍PTQ转换的流程与步骤相关内容。
PTQ转换流程说明
配合地平线工具链的模型完整开发过程,需要经过 浮点模型准备 、 模型检查 、 模型转换 、 性能评估 和 精度评估 共五个重要阶段,如下图所示。
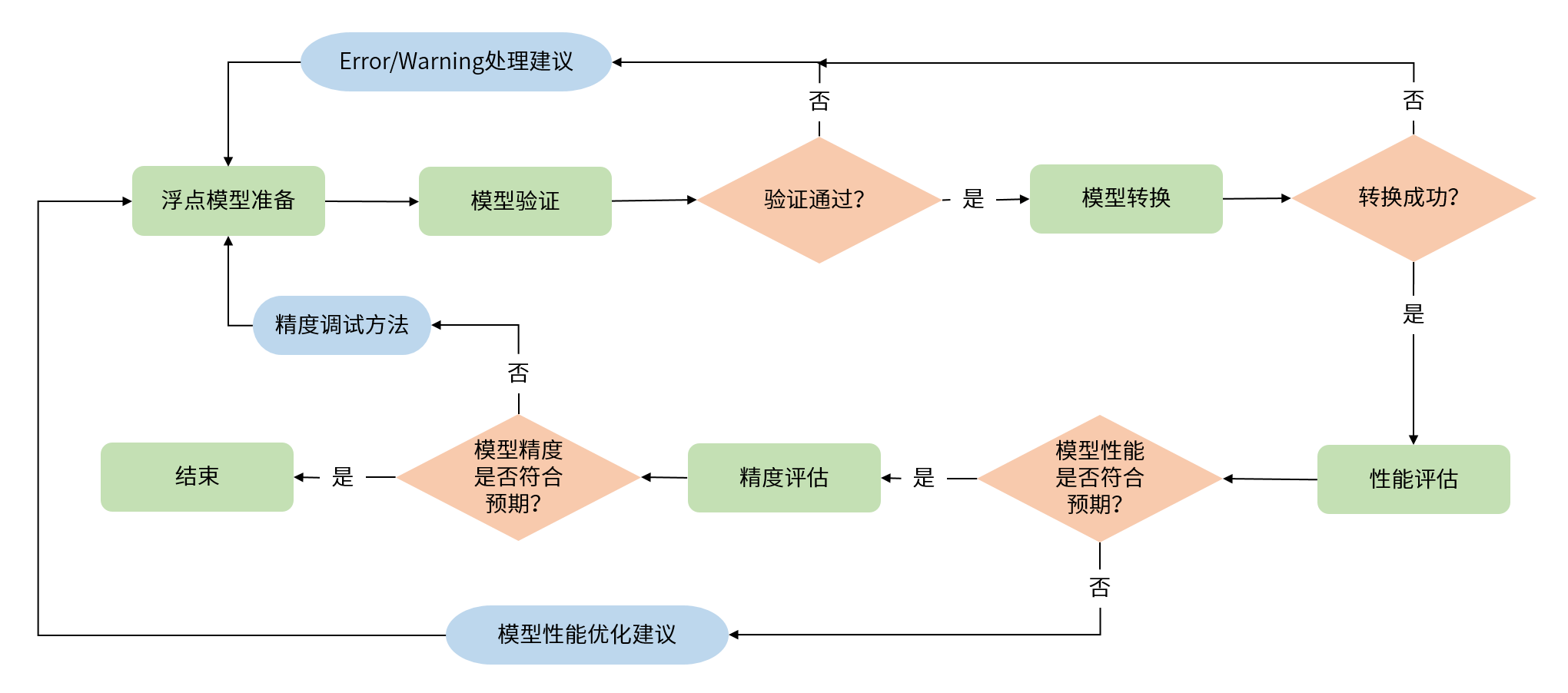
浮点模型准备 阶段的产出是输入到模型转换工具的浮点模型,这些模型一般都是基于公开DL训练框架得到的,需要您注意的是将模型导出为地平线工具支持的格式。 具体要求与建议请参考 浮点模型准备 章节。
模型检查 阶段用来确保算法模型是符合计算平台要求的。地平线提供了指定工具完成此阶段检查,对于不符合要求的情况, 检查工具会明确给出不符合要求的具体算子信息,方便您结合算子约束的说明将模型调整过来。具体使用请参考 验证模型 章节。
模型转换 阶段将完成浮点模型到地平线板端可部署模型的转换。为了模型能在地平线计算平台上高效运行,地平线转换工具内部会完成模型优化、量化和编译等关键步骤,地平线的量化方法经过了长期的技术与生产验证,在大部分典型模型上可以保证精度损失在1%左右。 具体使用请参考 数据准备 及 模型量化与编译 章节。
性能评估 阶段提供了系列评估模型性能的工具。在应用部署前,您可以使用这些工具验证模型性能是否达到应用要求。 对于部分性能不及预期的情况,也可以参考地平线提供的性能优化建议进行调优。 具体评估请参考 模型性能分析 章节。
精度评估 阶段提供了系列评估模型精度的工具。大部分情况下,地平线转换后模型可以保持与原始浮点模型基本一致的精度效果,在应用部署前,您可以使用地平线工具验证模型的精度是否符合预期。 对于部分精度不及预期的情况,也可以参考地平线提供的性能优化建议进行调优。 具体评估请参考 模型精度分析 章节。
-
通常在模型转换后就已经得到了可以上板的模型,但是为了确保您得到的模型性能和精度都是符合应用要求的,地平线强烈建议每次转换后都完成后续的性能评估与精度评估步骤。
-
模型转换过程会生成onnx模型,这些模型均为中间产物,只是便于验证模型精度情况,因此不保证其在版本间的兼容性。若使用示例中的评测脚本对onnx模型单张或在测试集上进行评测时,请使用当前版本工具生成的onnx模型进行操作。
模型转换过程详解
那么如何使用浮点模型转换工具将Caffe、TensorFlow、PyTorch等开源框架训练好的浮点模型转换成地平线硬件上支持的定点模型呢?
一般情况下,从官网下载或者自己训练得到的模型,其阈值、权重等均为浮点数(float32),每个数占用4个字节。 但在嵌入式端运行时,若能将其内部数值从浮点数转化为更低bit的计算,计算量可以大大减少, 因此,若能在不损失或损失较小的情况下将浮点模型转换为更低bit的计算,则其性能会有显著提升。
模型的转换通常可分为以下几个步骤:
-
检查待转换的模型中是否包含不支持的OP类型。
-
准备好20-100张校准使用的图片,用于转换阶段的校准操作。
-
使用浮点模型转换工具将原始浮点模型转换为定点模型。
-
对转换后的模型进行性能和精度的评估,确保转换后的定点模型精度与之前相差不大。
-
在模拟器/开发板上运行模型,对模型的性能和精度进行验证。
模型检查
如果本过程,您需在示例文件夹内进行,那么您需要先执行文件夹中的 00_init.sh 脚本以获取对应的原始模型和数据集。
模型在从浮点转换为定点模型之前,我们首先需要通过工具 hb_compile 检查一下,看看该模型是否包含不能在地平线硬件上运行的OP。
如果存在,则会在该阶段提示不认识该OP, 使用 hb_compile 验证模型的具体使用方式可参考 模型验证 一节内容。
有关地平线硬件可支持的OP信息,请参见 工具链算子支持约束列表-ONNX Operator Support List章节内容。
准备校准图片
如果本过程,您需在示例文件夹内进行,那么您需要先执行文件夹中的 00_init.sh 脚本以获取对应的原始模型和数据集。
在进行模型转换时,校准阶段需要20-100张图片输入进行校准操作。由于模型的输入类型及layout的不同,输入的图片格式可以多种多样。 该阶段既可以输入原始图片(*.jpg等),也可以输入处理过的,满足模型输入要求的图片。您可以直接从模型训练时的数据集中获取相应的校准图片,也可以自行处理图片生成校准数据集。
校准数据集需为npy格式。
推荐您自行对校准图片进行前处理,将图片的通道(BGR/RGB),数据排布(NHWC/NCHW),图像大小及填充(Resize&Padding)等操作调整好后,工具会通过npy文件的方式将图片读入后送入校准阶段。
以Resnet50为例,则需要进行如下transformer的操作:
模型转换
当通过上述模型检查过程,确定了模型能够被转换成功后,接下来可以使用 hb_compile 工具来将浮点模型转换为一个可以在地平线硬件上运行的定点模型。
该过程需要传入一个包含转换要求的配置文件(*.yaml)。具体的配置文件设置及各参数的含义,请参考 配置文件模板 和 配置文件具体参数信息 章节的介绍。
模型转换过程结束后,还会将原始模型与转换后的定点模型的相似程度打印在log中,可根据 Quantized Cosine 字段来判断模型转换前后的相似度。
如模型转换后的 Quantized Cosine 非常接近1,即代表模型转换后的模型表现会与转换前的浮点模型非常相近。
Log中的相似度为校准图片中的第一张的相似度情况,并不完全代表模型转换前后的精度。
在模型转换成功后,会在生成的文件夹 (默认为 model_output )中生成各阶段的模型产出物、信息文件以及模型静态评估文件,其中的模型产出物文件会在后续阶段使用到。
-
可调用
03_classification/03_resnet50/03_build.sh脚本,来体验hb_compile对模型做量化编译时的使用效果。 -
如果希望了解更多模型转换的工作流程,请阅读 模型量化与编译 一节内容。
单张图片的模型推理
在运行浮点模型转换之后,得到了定点模型,还需对其自身的正确性进行验证。
您需要对模型的输入/输出结构比较了解,并能够正确地对模型输入图片做前处理以及模型输出的后处理解析,并自行编写模型运行脚本。在此过程中可参照交付包中各示例文件夹下 04_inference.sh 中的示例代码。代码的主要逻辑如下:
使用该脚本后,便可通过输入单张图片验证其自身的准确性。例如,该脚本的输入为一张斑马的图片,在经过前处理将图片数据从rgb处理到input_type_rt配置的数据类型后(关于中间类型的介绍可参考
转换过程内部解读 , 通过 HBRuntime 命令传入模型进行推理,推理后进行后处理,最后打印出其最可能的5个种类。
运行后的输出如下所示,最可能的类别是 label: 340。
label 的类别使用的是ImageNet的类别, 340 正是对应着斑马,因此该图片推理正确。
模型精度验证
光对单张图片进行验证还不足以说明模型的精度,因此还有脚本对模型转换后的精度进行评测。
您需要编写代码使模型能够循环推理图片,并将结果与标准结果进行比较,得到精度结果。
因为精度评测时,需要对图片进行 前处理,对模型数据进行 后处理,所以我们提供了一个示例Python脚本。
其原理与单张推理一致,但需要在整个数据集上面运行。使用该脚本后,便可通过读取数据集,对模型的输出结果进行评判,并输出评测结果。
运行该脚本耗费时间较长,但可以通过设置 PARALLEL_PROCESS_NUM 环境变量来设置运行评测的线程数量。
在该脚本执行结束后,即可得到转换后的定点模型精度。
- 在不同的系统下,由于依赖库版本不同,转换得到的模型精度可能会略有差别。
- 同时由于版本更迭,得到的定点模型精度可能也会略有差别。
[参考]支持的校准方法
目前我们支持了以下的校准方法:
- default
default 是一个自动搜索的策略,会尝试从系列校准量化参数中获得一个相对效果较好的组合。
- mix
mix 是一个集成多种校准方法的搜索策略,能够自动确定量化敏感节点,并在节点粒度上从不同的校准方法中挑选出最佳方法,最终构建一个融合了多种校准方法优势的组合校准方式。
- KL
KL校准方法是借鉴了 TensorRT提出的解决方案 , 使用KL熵值来遍历每个量化层的数据分布,通过寻找最低的KL熵值,来确定阈值。这种方法会导致较多的数据饱和和更小的数据量化粒度,在一些数据分布比较集中的模型中拥有着比max校准方法更好的效果。
- max
max校准方法是在校准过程中,自动选择量化层中的最大值作为阈值。这种方法会导致数据量化粒度较大,但也会带来比KL方法更少的饱和点数量,适用于那些数据分布比较离散的神经网络模型。
[参考]OP列表
若想了解更多关于当前工具链支持的算子及对应约束条件,请参见 工具链算子支持约束列表-ONNX Operator Support List 章节内容。