算法模型PTQ量化+上板 快速上手
本章节中,我们将为您介绍训练后量化PTQ方案的基本使用流程,便于您实现快速上手。 这里我们以ResNet50模型为例,为您进行使用演示,详细内容将在后续章节为您展开介绍,基本工作流程如下图所示。
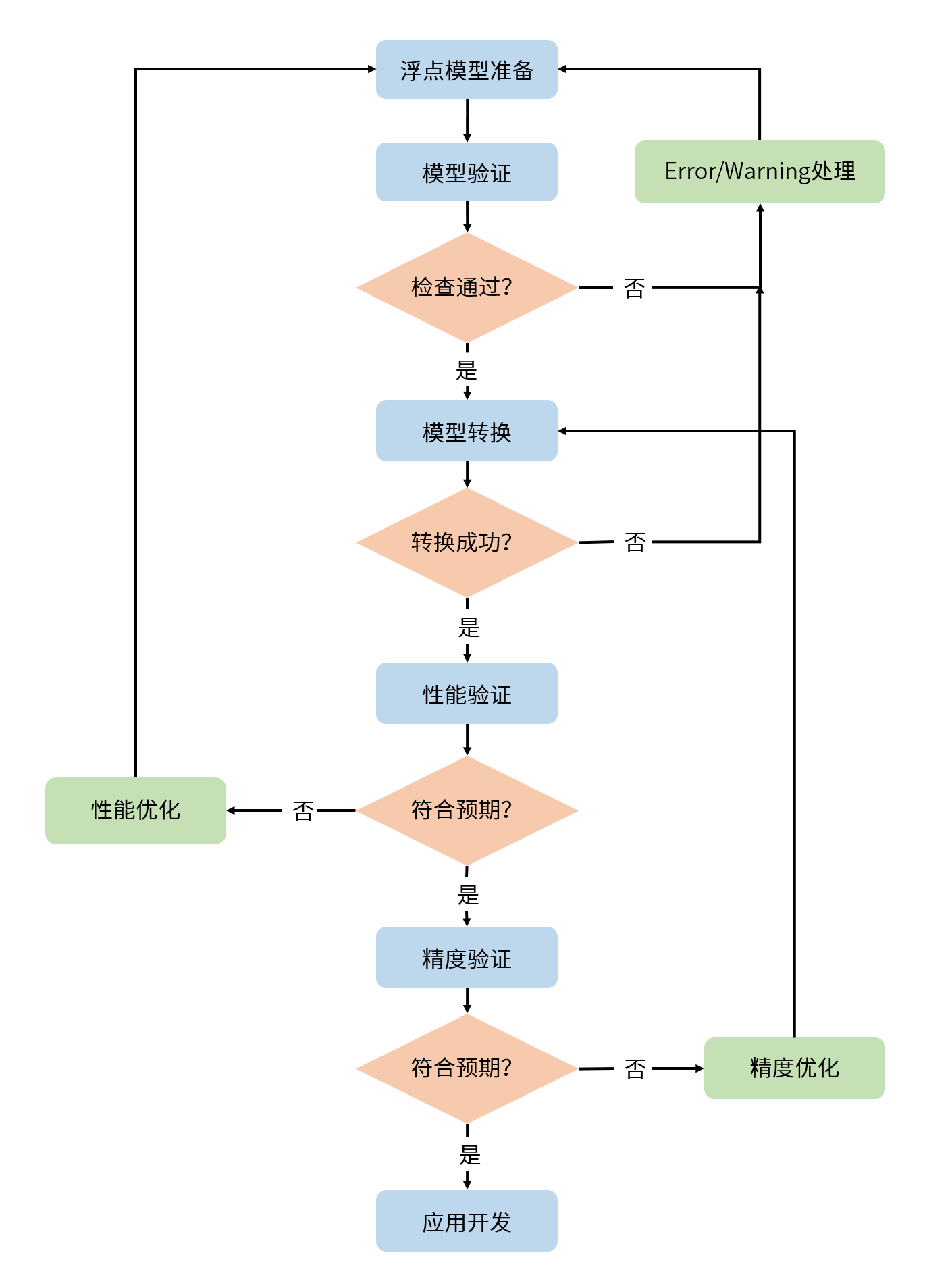
请注意,在您进行以下操作前,请确保您已经参考 环境部署 章节完成了开发机和开发板上的环境安装。
浮点模型准备
OE包在 samples/ai_toolchain/horizon_model_convert_sample 路径下为您提供了丰富的PTQ模型示例, 其中ResNet50模型示例位于 03_classification/03_resnet50 路径下。
请先执行其中的 00_init.sh 脚本来获取示例对应的校准数据集和原始模型。
如您需要转换私有模型,请参考 浮点模型准备 章节内容提前准备好 opset=10-19的onnx模型。 下表为不同框架到ONNX模型格式转换的参考方案:
| 训练框架 | 参考方案 |
| Pytorch | 使用 官方API 导出。 |
| Tensorflow | 使用ONNX社区的 onnx/tensorflow-onnx工具 进行转换。 |
| PaddlePaddle | 使用 官方API 导出。 |
| MXNet2Onnx | 使用 官方API 导出。 |
| 其他框架 | 使用 参考方案 进行转换。 |
模型验证
在浮点模型准备好之后,我们建议先进行快速的模型验证,以确保其符合计算平台的支持约束。 对于ONNX格式的ResNet50模型,我们可以在命令行中键入以下命令完成模型验证:
如您的模型为多输入模型,可参考如下指令:
hb_compile 工具在验证模型时需要使用到的主要参数如下,更多参数说明还请参考 验证模型 章节。
| 参数 | 说明 |
--march | 用于指定需要适配的处理器类型,S100处理器请设置为 nash-e,S100P处理器需设置为 nash-m,S600处理器需设置为 nash-p。 |
--proto | 此参数仅在model-type指定caffe时有效,取值为caffe模型的 prototxt 文件名称; onnx模型无需配置该参数。 |
--model | 在模型为caffe模型时,取值为Caffe模型的caffemodel 文件名称;在模型为onnx模型时,取值为 ONNX模型 文件名称。 |
以ResNet50模型为例,您可以使用 01_check.sh 脚本快速完成模型验证。
01_check.sh 脚本文件中的主要内容如下所示:
如果模型验证不通过,请根据终端打印或在当前路径下生成的 hb_compile.log 日志文件确认报错信息和修改建议,更多说明请参考 验证模型 章节。
模型转换
模型验证通过后,就可以使用 hb_compile 工具进行模型转换,参考命令如下:
其中, resnet50_config.yaml 为模型转换对应的配置文件,配置文件模板请参考 配置文件模板 章节。
另外,PTQ方案的模型量化还需要依赖一定数量预处理后的样本进行校准,将在 校准数据预处理 中进行介绍。
Yaml配置文件
Yaml配置文件共包含4个必选参数组( model_parameters 、 input_parameters 、 calibration_parameters 、 compiler_parameters)。
每个参数组下也区分必选和可选参数(可选参数默认隐藏),具体要求和填写方式可以参考 配置文件具体参数信息 章节。
ONNX模型仅需配置 onnx_model 参数,无需配置 model_parameters 参数组中的 caffe_model 和 prototxt 参数。
-
input_parameters参数组中的input_type_rt和input_type_train参数分别用于指定模型在板端实际部署时会接收到的数据类型(如nv12)和本身训练时的数据类型(如rgb)。当两种数据类型不一致时,转换工具会自动在模型前端插入一个能BPU加速的预处理节点,以完成对应的颜色空间转换。同时,该参数组中的
mean_value、scale_value、std_value参数还能用于配置图片输入模型的数据归一化操作,配置后转换工具也会将其集成进预处理节点实现BPU加速。数据归一化的计算公式为: -
calibration_parameters参数组中的cal_data_dir参数需要配置预处理好的校准数据文件夹路径,预处理方式的说明请参考 校准数据预处理。
校准数据预处理
- 请注意,在进行此步之前,请确保您已经通过执行对应示例目录下的
00_init.sh脚本完成了校准数据集的获取。 - 如果当前只关注模型性能,那么无需配置
cal_data_dir参数,并跳过本小节,工具会在模型转换时进行伪校准方便您快速验证。
PTQ方案的校准数据一般是从训练集或验证集中筛选100份左右(可适当增减)的典型数据,并应避免非常少见的异常样本,如纯色图片、不含任何检测或分类目标的图片等。筛选出的校准数据还需进行与模型inference前一致的预处理操作,处理后保持与原始模型一样的数据类型( input_type_train )、layout ( input_layout_train )和尺寸( input_shape )。
对于校准数据的预处理,地平线建议直接参考示例代码进行修改使用。以ResNet50模型为例,preprocess.py文件中的calibration_transformers函数的包含了其校准数据的前处理transformers,处理完的校准数据与其 yaml 配置文件保持一致,即:
-
input_type_train : 'rgb'
-
input_layout_train :'NCHW'
其中,transformers都定义在 ../../../01_common/python/data/transformer.py 文件中, 具体说明请参考 图片处理transformer说明,您可以按需选用或者自定义修改及扩展。
修改完preprocess.py文件后,即可修改02_preprocess.sh脚本并执行,以完成校准数据的预处理。
02_preprocess.sh脚本文件的主要内容如下:
data_preprocess.py文件的传参说明如下:
-
src_dir为原始校准数据路径。
-
dst_dir为处理后数据的存放路径,可自定义。
-
pic_ext为处理后数据的文件后缀,主要用于帮助记忆数据类型,可不配置。
-
read_mode为图片读取方式,可配置为skimage、opencv或PIL。 需要注意的是,skimage读取的图片类型为RGB,数据范围为0-1,opencv读取的图片类型为BGR,数据范围为0-255,PIL读取的图片类型为RGB,数据范围为0-255。
-
saved_data_type为处理后数据的保存类型。
如果您选择自行编写python代码实现校准数据预处理,那么可以使用 numpy.save 命令将其保存为npy文件,工具链校准时会基于 numpy.load 命令进行读取。
转换模型
准备完校准数据和yaml配置文件后,即可一步命令完成模型解析、图优化、校准、量化、编译的全流程转换,内部过程详解请参考 转换内部过程解读章节。
转换完成后,会在yaml文件配置的 working_dir 路径下保存如下文件,详细说明请参考 转换产出物解读 章节。
如果模型转换过程中存在移除输入/输出端的节点的情况,生成物中还会保存 *_quantized_removed_model.bc, 此种场景下,如后续需进行一致性对比,我们建议您使用此HBIR模型与最终生成的hbm模型进行对比。
性能快速验证
针对转换生成的 xxx.hbm 模型文件,地平线既支持先在开发机端预估模型BPU部分的的静态性能,也在板端提供给了无需任何代码开发的可执行工具快速评测动态性能,以下将分别进行介绍。
更详细的说明和性能调优建议请参考 模型性能分析 与 模型性能调优 章节。
静态性能评估
如 转换模型 所述,模型成功转换后会在 working_dir 路径下生成包含模型静态性能预估的html和json文件,html文件的可读性更好。
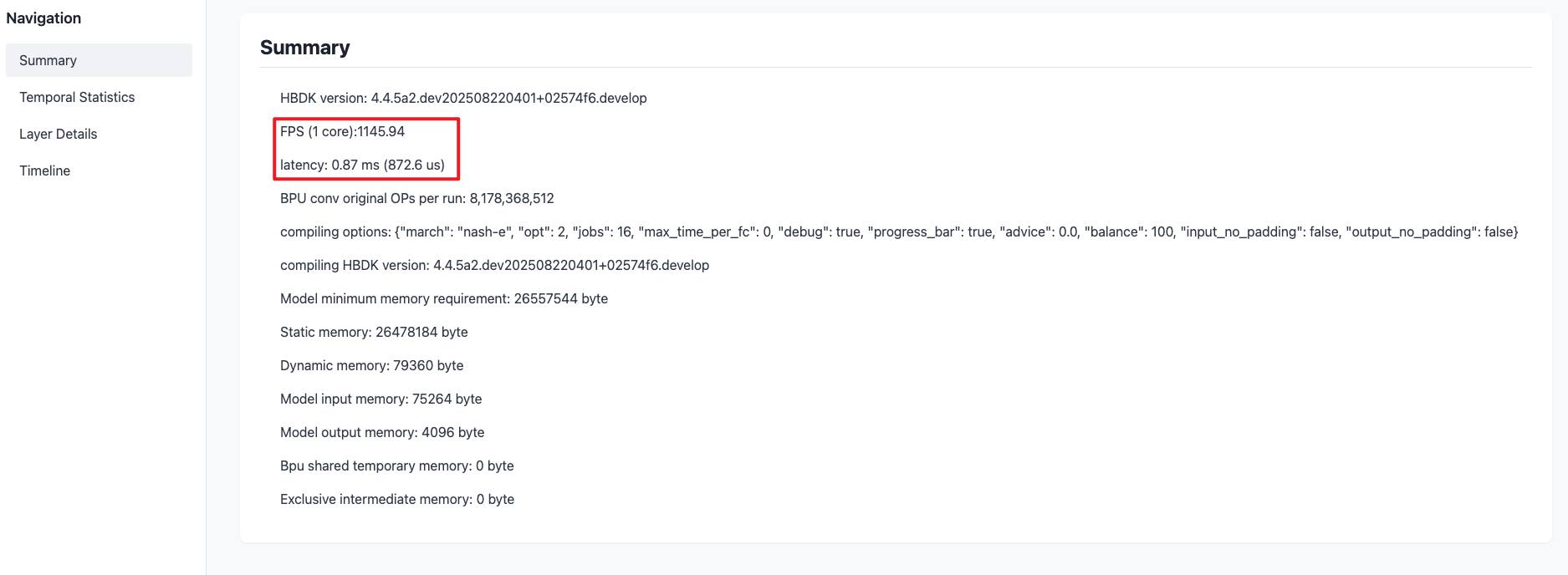
以下为 ResNet50 模型转换生成的html文件,其中:
-
Summary选项卡提供了编译器预估的模型BPU部分性能。
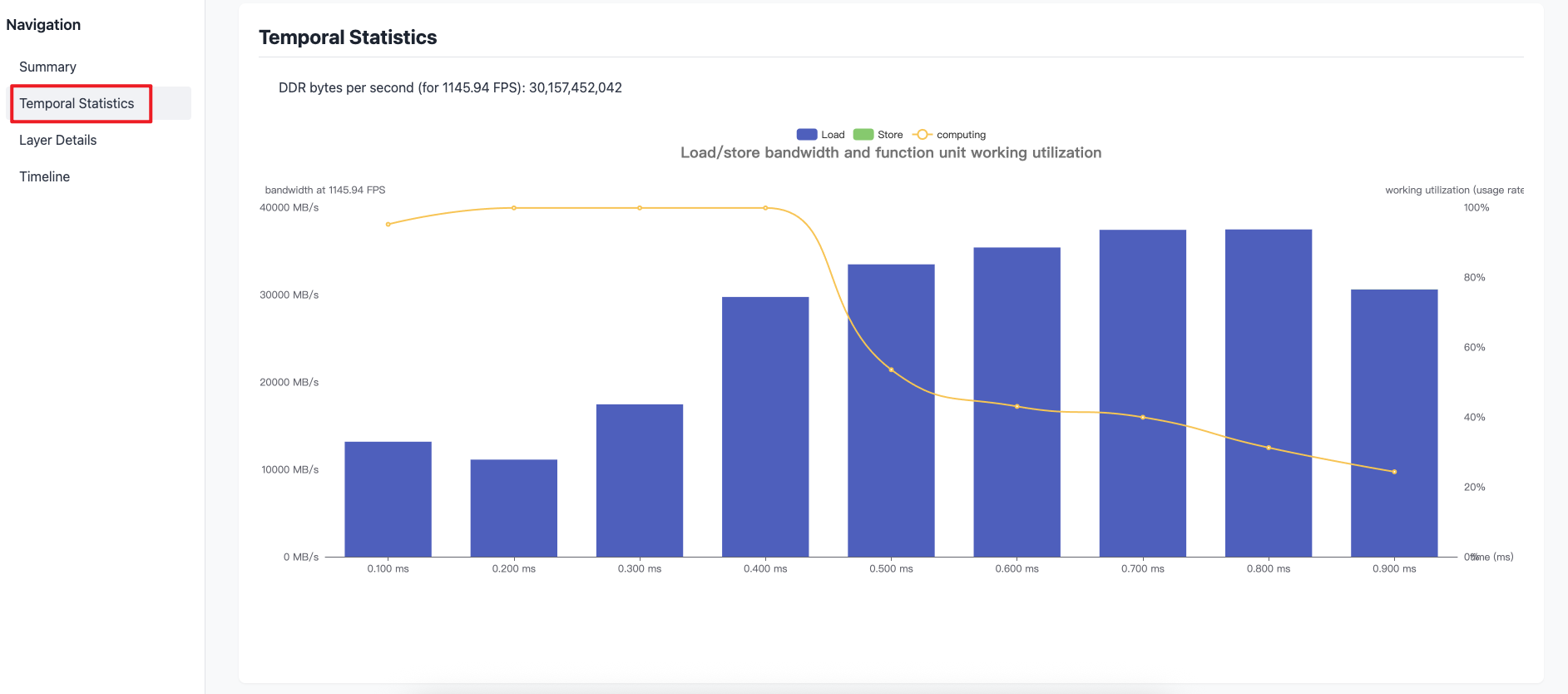
-
Temporal Statistics选项卡提供了模型一帧推理时间内的带宽占用情况。
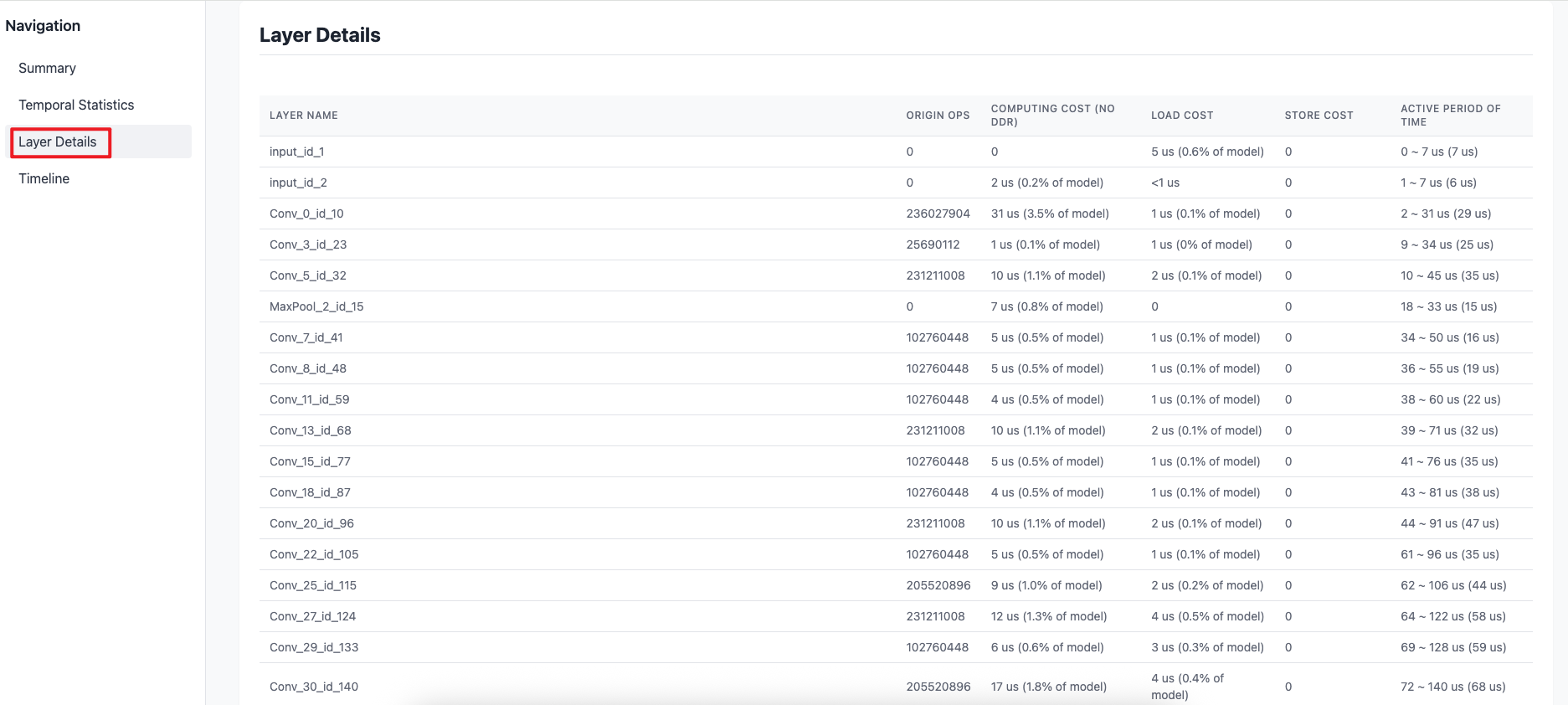
-
Layer Details选项卡提供了每一层BPU算子的计算量、计算耗时、数据搬运耗时的信息以及编译后layer活跃时间段(不代表该layer执行时间,通常为多个layer交替/并行执行)。
-
Timeline选项卡提供了模型一帧推理时间内指令集的预估耗时及对应的计算单元的信息。
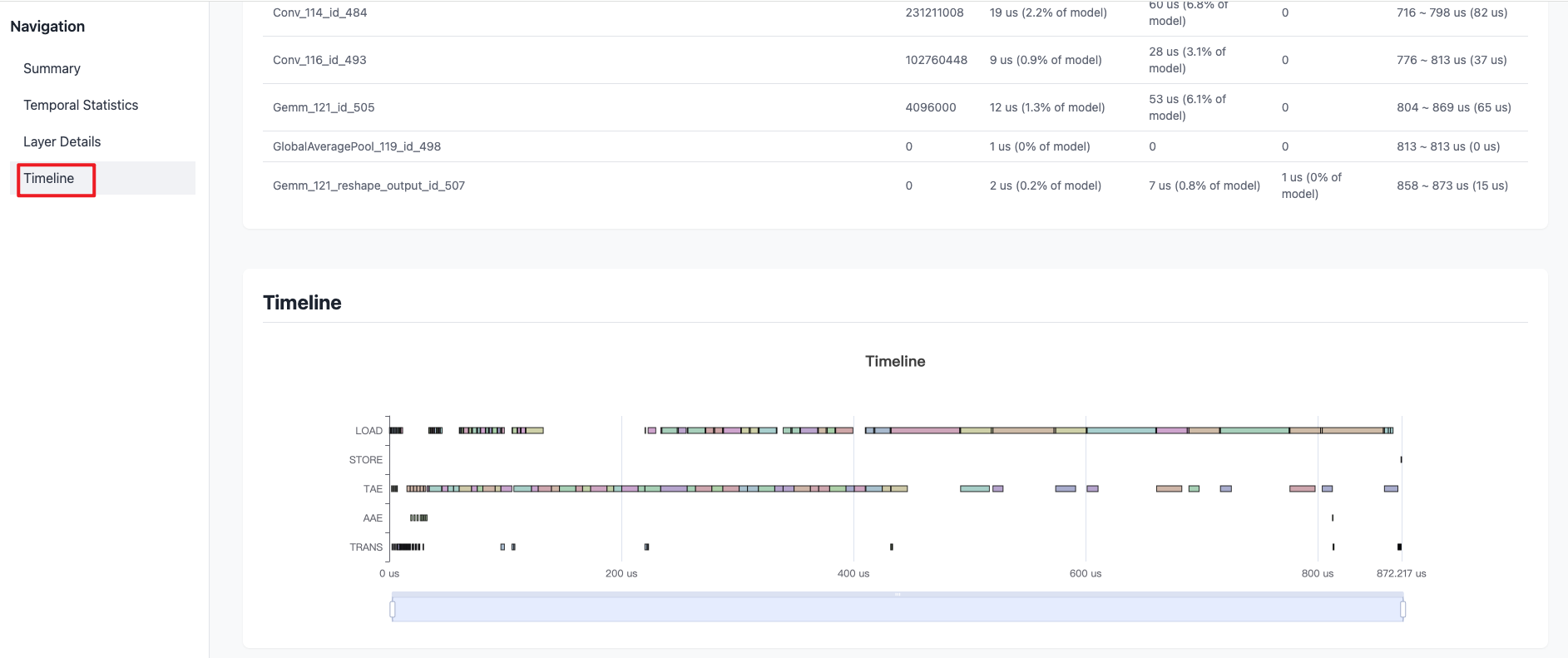
上方Timeline选项卡中包含的指标如下:
-
TAE:Tensor Acceleration Engine,是BPU中负责Tensor计算加速的引擎模块。主要负责各种conv计算,也能支持部分Matrix计算。
-
AAE:Auxiliary Acceleration Engine,是BPU中负责辅助计算加速的引擎模块。主要负责张量、向量、标量之外的辅助加速,例如Pooling、Resize、Warp等函数计算。
-
TRANS:是BPU中用于处理数据layout变换的计算单元。
-
STORE:表示将数据从内部缓存/寄存器写到内存中(或计算平台外)。
-
LOAD:表示从内存(可能是计算平台外)加载数据到计算平台缓存中。
-
动态性能评估
当模型的静态性能符合预期后,我们可以进一步上板实测模型的动态性能,其参考方式如下:
-
首先请确保已按照 环境部署 章节完成开发板环境部署。
-
将转换生成的
xxx.hbm模型拷贝至开发板/userdata文件夹下任意路径。 -
通过
hrt_model_exec perf工具快捷评估模型的耗时和帧率。
hrt_model_exec 工具的主要参数说明如下,更多说明请参考 hrt_model_exec工具介绍 章节。
| 参数 | 类型 | 说明 |
| model_file | string | [必选]模型文件路径 |
| core_id | string | [可选]用于指定BPU运行核心,默认值为0。当指定多个核运行时,用英文字符的逗号隔开,如 `"1,2"。 0:任意核,预测库会根据负载情况自动分配调度。 1:core0,2:core1,以此类推。 |
| thread_num | int | [可选]程序运行线程数,可选范围[1,32],默认值1。 |
| frame_count | int | [可选]模型运行总帧数,默认值200。 |
| profile_path | string | [可选]统计工具日志产生路径,运行产生profiler.log和profiler.csv,分析op耗时和调度耗时。 |
-
如果您在板端无法找到
hrt_model_exec工具,可以再执行一次OE包中package/board路径下的install_linux.sh或install_qnx.sh脚本(根据您实际的环境进行选择)。 -
评测Latency时一般采用单线程串行的推理方式,可以指定
thread_num为1。 -
评测FPS时一般采用多线程并发的推理方式来占满BPU资源,此时可以配置
core_id为 0,并配置thread_num为多线程。 -
模型的输入为动态输入时,请根据实际输入填写
input_valid_shape和input_stride参数。 -
如果您配置了
profile_path参数,程序需要正常运行结束才会生成profiler.log和profiler.csv日志文件,请勿使用Ctrl+C命令中断程序。
当模型的动态性能不符合预期时,请参考 模型性能调优 章节进行性能调优。
精度验证
当模型的性能验证符合预期后,即可进行后续的精度验证。请首先确保您已经准备好相关的评测数据集,并挂载在Docker容器中。 示例模型使用的数据集可以参考 数据集下载 章节的介绍进行获取。
如 转换模型 所述,模型转换会生成 xxx_quantized_model.bc 和 xxx.hbm 两个量化模型,两者输出是保持数值一致的。
您也可以在开发机环境使用 hb_verifier 工具进行一致性验证,参考命令如下,详细说明请参考 hb_verifier 工具 章节。
相比于 xxx.hbm ,地平线更建议优先在开发机Python环境评测 xxx_quantized_model.bc 模型的量化精度,其评测方式更加简单快捷,
具体请见 开发机Python环境验证 。 xxx.hbm 在板端基于C++代码的评测说明请见 开发板C++环境验证,
更详细的精度验证和优化建议请参考 模型精度分析 与 模型精度优化 章节。
开发机Python环境验证
以ResNet50模型为例,resnet50_224x224_nv12_quantized_model.bc量化模型的单张推理和验证集精度评测示例请参考示例目录中的 04_inference.sh 和 05_evaluate.sh 脚本,参考命令如下:
两个脚本会分别调用 ../../cls_inference.py 和 ../../cls_evaluate.py 文件进行推理, 以 cls_inference.py文件为例,代码中的主要接口使用逻辑如下:
其中,infer_image_preprocess函数的前处理操作来源于 校准数据预处理 章节所述preprocess.py文件。
相比于calibration_transformers函数,会额外增加数据转换为 input_type_rt 的过程(参数说明请见 Yaml配置文件 章节),
HBIR模型在推理时的数据准备(包括 input_type_rt 到 input_type_train 的色彩转换,mean/scale的处理等)会在内部完成,所以无需额外在外部进行归一化等处理。
具体代码如下:
开发板C++环境验证
在开发板端,地平线提供了统一异构计算平台UCP,来帮助您快速完成模型的部署工作,并提供了相关示例。 您可以首先参考 模型部署 章节学习模型部署和模型推理接口的基础使用, 再参考 AI-Benchmark 章节学习示例模型精度评测的完整代码框架。
模型部署
OE包提供了模型部署的基础示例,以便于您学习UCP模型推理API接口的使用方式, 示例的详细说明可以参考 基础示例包使用说明 章节。
请注意,在您进行模型部署前,需要先获取上板使用的模型:
- 在
samples/ai_toolchain/model_zoo/runtime/ai_benchmark目录下,执行resolve_ai_benchmark_ptq.sh、resolve_ai_benchmark_qat.sh脚本。 - 在
samples/ai_toolchain/model_zoo/runtime/basic_samples目录下,执行resolve_runtime_sample.sh脚本。
其中,示例目录下的 code/00_quick_start/src/main.cc 文件提供了resnet50模型从准备数据到模型推理,再执行后处理出分类结果的完整流程代码。
从摄像头输入的全链路示例可以参考 samples/ucp_tutorial/all-round 。
main.cc中的主要代码逻辑包括以下6个步骤,代码中所涉及的API接口的具体说明可以参考 模型推理API手册 章节。
-
加载模型,获取模型句柄。
-
准备模型输入输出tensor,申请对应的BPU内存空间。
-
读取模型输入数据,并放入申请好的输入tensor中。
-
推理模型,获取模型输出。
-
基于输出tensor中的数据实现模型后处理。
-
释放相关资源。
该示例运行的参考方式如下:
AI-Benchmark
OE包在 samples/ai_toolchain/ucp_tutorial/dnn/ai_benchmark 路径下还提供了典型分类、检测、分割、光流示例模型板端性能和精度评测的示例包,您可以基于这些示例进行进一步的应用开发。
更多说明您可参考 AI-Benchmark使用说明 章节。
应用开发
当模型的性能和精度验证都符合预期后,即可参考 模型推理应用开发指导 章节实现上层应用的具体开发。