基础示例包使用说明
基础示例包旨在帮助您熟悉和学习模型推理相关的接口以及各种进阶功能。 基础示例包也可以作为新项目的起点,帮助您快速搭建起一个基本框架,并在此基础上进行进一步的开发和定制。
基础示例包提供了三个方面的示例:
-
提供了基于resnet50模型的快速入门示例。您可以体验并基于这个示例进行应用开发,降低开发门槛。
-
提供了模型推理接口的使用示例。您可以通过该示例更好的熟悉各种基础功能的使用。
-
提供了各种特色功能的进阶示例。您可以根据实际使用场景选择合适的功能进行模型推理。
发布物说明
基础示例包位于发布物的 samples/ucp_tutorial/dnn/basic_samples/ 路径下,主要包括以下内容:
| 名称 | 内容 |
|---|---|
| basic_samples | 包含示例源代码和运行脚本。 |
示例包结构如下所示:
-
code:该目录内是示例的源码。
-
code/00_quick_start:快速入门示例,基于模型推理接口,用resnet50进行单张图片模型推理和结果解析。
-
code/01_api_tutorial:模型推理接口使用示例,包括增加/去除padding的示例
padding、量化反量化示例quanti、内存使用示例mem、模型加载与信息获取示例model。 -
code/02_advanced_samples:模型推理进阶示例,包括裁剪图像作为模型输入的示例
crop、存在roi输入时的模型推理示例roi_infer以及多模型批量推理示例multi_model_batch。 -
code/build.sh:程序编译脚本,需要指定编译参数,被build_aarch64.sh和build_x86.sh调用。
-
code/build_aarch64.sh:程序一键编译脚本,编译产生的示例在aarch64环境linux操作系统下运行。
-
code/build_x86.sh:程序一键编译脚本,编译产生的示例在x86环境下运行。
-
code/resolve.sh:程序运行依赖获取脚本,在编译模型前需执行。
-
runtime:示例运行脚本,预置了数据和相关模型。
环境构建
开发板准备
-
拿到开发板后,升级系统镜像到示例包推荐的系统镜像版本。
-
确保本地开发机和开发板可以远程连接。
编译
编译需要的步骤如下:
-
根据 环境部署 章节的指引,安装好交叉编译工具。
-
在
ucp_tutorial/dnn/basic_samples/code目录下有预先配置好的编译脚本build.sh,您可以使用该脚本并指定编译选项进行编译。 -
执行编译脚本后,可执行程序和对应依赖会自动复制到 runtime/script 或者 runtime/script_x86目录下。
build.sh脚本里指定的交叉编译工具链的位置是 /usr/bin 目录下,您如果安装在其他位置,可以手动修改下build.sh。
示例使用(basic_samples示例)
若在x86环境下运行示例,请使用 runtime/script_x86 下的脚本。
示例脚本主要在 runtime/script 目录下,编译程序后目录结构如下:
运行前,把runtime目录部署到板端,执行对应脚本即可。
-
basic_samples示例包的模型发布物需要在OE包的samples/ai_toolchain/model_zoo/runtime/${march}/basic_samples目录下执行resolve_runtime_sample.sh脚本进行获取。路径中的${march}可选值有nash-e及nash-p,分别对应S100/S100P、及S600平台,您可根据需要自行选择。 -
basic_samples示例包的其他依赖需要在OE包的samples/ucp_tutorial/dnn/basic_samples/code目录下执行resolve.sh脚本进行获取。 -
model文件夹包含模型所在的路径,runtime文件夹为软链接,链接路径默认指向../../../model_zoo/runtime/nash-e/basic_samples。若您需要运行非nash-e架构的模型,可自行修改链接路径中的nash-e为nash-b或nash-p。
quick_start
00_quick_start 目录下,我们提供了一个快速上手的示例,旨在介绍模型推理的使用流程。这里以resnet50模型为例,分别展示了nv12输入和rgb输入两种模型推理的过程,包含了从准备数据到模型推理,再到执行后处理,生成分类结果的完整流程代码。
代码主要分为六个部分:
-
加载模型并获取模型指针:主要涉及到的接口有 hbDNNInitializeFromFiles、hbDNNGetModelNameList 以及 hbDNNGetModelHandle。
-
准备输入以及输出张量,同时补全输入的动态信息:主要涉及到的接口有 hbDNNGetInputCount、hbDNNGetOutputCount、hbDNNGetInputTensorProperties、hbDNNGetOutputTensorProperties、hbDNNGetInputName、hbDNNGetOutputName 以及 hbUCPMallocCached。
-
准备输入数据:对于nv12输入,需要将图片进行颜色空间转换,而对于rgb输入,需要做U8转换到S8的前处理,这里涉及到的接口为 hbUCPMemFlush。
-
模型推理:主要涉及到的接口有 hbDNNInferV2、hbUCPSubmitTask 以及 hbUCPWaitTaskDone。
-
输出数据后处理:resnet50模型是分类模型,可以通过后处理获取置信度较高的分类结果,在处理输出前需要调用 hbUCPMemFlush 接口进行数据同步。
-
释放任务、内存以及模型:主要涉及到的接口有 hbUCPReleaseTask、hbUCPFree 以及 hbDNNRelease。
脚本的目录结构如下:
使用的时候,进入 00_quick_start 目录,然后直接执行sh run_resnet_rgb.sh和sh run_resnet_nv12.sh即可,脚本执行成功后会打印模型输入输出的名称以及置信度最高的5个分类结果,分类结果置信度最高的编号 340 表明是斑马。
api_tutorial
该示例是指 01_api_tutorial 目录内的示例,旨在介绍模型推理API的使用。其目录包含以下脚本:
padding
该示例主要帮助您熟悉模型输入如何增加padding,模型输出如何去除padding。主要涉及到的数据类型为 hbDNNTensorProperties 中的 validShape 与 stride。
为了加速计算,模型对于输入数据有对齐要求,详见 对齐规则。该示例分为两个部分:
-
对于模型输入,当需要额外对数据进行对齐操作时,使用示例中提供的
add_padding方法增加padding。 -
对于模型输出,当输出中含有padding时,使用示例中提供的
remove_padding方法去除padding以获取有效数据。
使用的时候,直接进入 01_api_tutorial 目录,然后直接执行 sh padding.sh 即可,脚本执行成功后会打印原始输入和增加padding后的输入数据、原始输出和去除padding后的输出数据。
quanti
该示例主要帮助您熟悉模型输入输出的量化、反量化处理。涉及到的的数据类型为 hbDNNTensorProperties 中的 quantiType、scale 以及 quantizeAxis。
当模型的输入中记录有量化信息时,需要将输入的浮点数按指定规则进行量化处理;当模型的输出中记录有量化信息时,需要对输出进行反量化处理后再对数据进行后处理。 处理方式可参考 hbDNNQuantiScale。
该示例主要分为四个部分:
-
输入per tensor的量化处理
-
输入per axis的量化处理
-
输出per tensor的反量化处理
-
输出per axis的反量化处理
使用的时候,直接进入 01_api_tutorial 目录,然后直接执行 sh quanti.sh 即可,脚本执行成功后每个部分会打印原始的输入/输出和量化/反量化后的结果。
model
该示例主要帮助您熟悉模型加载以及模型信息获取相关的接口使用。
涉及到的接口主要包括 hbDNNInitializeFromFiles、hbDNNGetModelNameList、hbDNNGetModelHandle、hbDNNGetInputCount、hbDNNGetOutputCount、hbDNNGetInputTensorProperties、hbDNNGetOutputTensorProperties 以及 hbDNNRelease。
使用的时候,直接进入 01_api_tutorial 目录,然后直接执行 sh model.sh 即可,脚本执行成功后会打印出模型的基本信息。
sys_mem
该示例主要帮助您熟悉内存接口的使用。主要涉及的接口有 hbUCPMalloc、 hbUCPMallocCached、hbUCPMemFlush 和 hbUCPFree。
针对于可缓存的内存,使用步骤如下:
-
申请可缓存的内存。
-
将数据写入内存。
-
调用 hbUCPMemFlush 接口使用
HB_SYS_MEM_CACHE_CLEAN参数将数据同步到DDR。 -
经过模型推理或算子计算后,调用 hbUCPMemFlush 接口使用
HB_SYS_MEM_CACHE_INVALIDATE参数将数据同步至缓存。 -
读取数据进行处理。
-
释放内存。
使用的时候,直接进入 01_api_tutorial 目录,执行 sh sys_mem.sh 即可。
advanced_samples
该示例是指 02_advanced_samples 目录内的示例,旨在介绍进阶示例的使用。其目录包含以下脚本:
crop
该示例主要帮助您熟悉如何对图像进行裁剪并作为模型的输入进行推理。示例代码的整体流程与 00_quick_start 相同,差异主要在于输入数据的准备。
该示例裁剪的原理是通过已存在图像的内存地址进行偏移到ROI左上角点,通过控制stride的大小将图像多余的部分进行屏蔽从而准备好模型的输入。
示例使用的限制:
-
图像:要求图像分辨率较大,至少要大于模型的输入,并且提前将图像读入到BPU内存中。
-
模型:要求模型的输入validShape为固定的,stride为动态的,这样能通过控制stride的大小对图像进行裁剪。
-
裁剪位置:由于裁剪是对图像内存进行偏移,而对于输入内存的首地址要求
32对齐,因此对偏移的大小有限制。
输入数据的准备:
-
图像:斑马图片的大小为376x376,我们将图片读入转化为Y和UV输入并进行
32对齐后分别存在两块BPU内存中。32对齐后斑马图片的宽image_width_stride = 384。 -
模型:模型有两个输入
-
y: validShape = (1,224,224,1), stride = (-1,-1, 1,1)
-
uv: validShape = (1,112,112,2), stride = (-1,-1,2,1)
-
-
裁剪:我们需要在图像中裁剪出一块224x224大小的区域作为模型的输入,选择(64,50)作为左上角点正好可以获取到大部分斑马图像,并且偏移后的内存地址正好
32对齐,满足要求。如下图所示。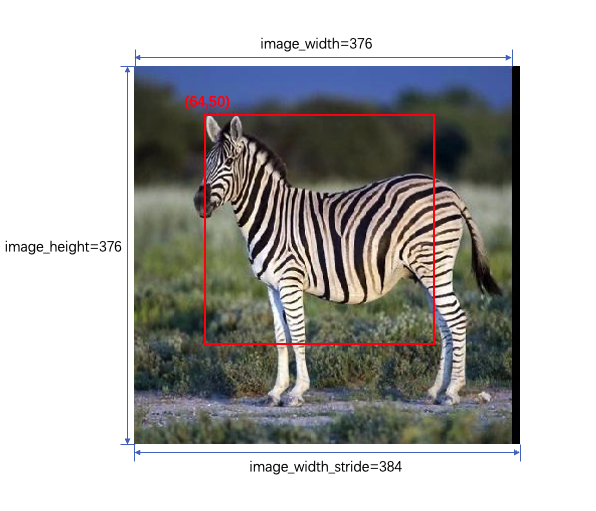
-
输入张量准备:
-
Y输入的stride为[224 * image_width_stride,image_width_stride,1,1],裁剪图像左上角点对应的坐标为[0,50,64,0],则地址偏移为
50 * image_width_stride + 64 * 1; -
UV输入的stride为[112 * image_width_stride,image_width_stride,2,1],裁剪图像左上角点对应的坐标为[0,25,32,0],则地址偏移为
25 * image_width_stride + 32 * 2;
-
使用的时候,直接进入 02_advanced_samples 目录,然后直接执行 sh run_crop.sh 即可,脚本执行成功后会打印置信度最高的5个分类结果,分类结果置信度最高的编号 340 表明是斑马。
multi_model_batch
该示例主要帮助您熟悉小模型批量处理的功能。
当有多个小模型运行时,如果一个个模型任务单独运行,整个框架的调度时间相对来说占比会较大,为了避免性能损失,您可以将多个小模型任务合成一个任务进行推理,减小框架调度时间的占比。
该示例以两个小模型 googlenet 和 resnet50 为例,通过多次调用 hbDNNInferV2 接口来创建/添加任务。
使用的时候,直接进入 02_advanced_samples 目录,执行 sh run_multi_model_batch.sh 即可,脚本执行成功后会打印两个模型置信度最高的分类结果,分类编号 340 表明是斑马。
roi_infer
该示例主要帮助您理解当存在roi输入时,如何准备数据进行模型推理。
示例代码的整体流程与 00_quick_start 类似,差异主要在于输入数据的准备。该示例模型为 mobilenetv1,输入一共为3个,如下所示:
-
name: data_y;validShape: (1,-1,-1,1);stride: (-1,-1,1,1);
-
name: data_uv;validShape: (1,-1,-1,2);stride: (-1,-1,2,1);
-
name: data_roi;validShape: (1,4);stride: (16,4);
data_y 与 data_uv 为动态输入,通过读取图片并转化为Y和UV数据进行对齐后作为输入,并依照图片的大小对 validShape 与 stride 进行补全。动态输入相关可参考 动态输入介绍。
data_roi 为图片中ROI区域的左上、右下角点的坐标,顺序为:左、上、右、下。
使用的时候,直接进入 02_api_tutorial 目录,然后直接执行 sh roi_infer.sh 即可,脚本执行成功后会分别打印模型两组输入置信度最高的5个分类结果,分类结果置信度最高的编号 340 表明是斑马。
辅助工具(日志)
日志主要包括 示例日志 和 dnn日志 两部分。其中示例日志是指交付包示例代码中所应用的日志,dnn日志是指嵌入式dnn库中的日志。您可以根据不同的需求设置不同的日志。
示例日志
示例日志主要采用hlog,hlog的日志主要分为7个等级:
log等级可设置为0、1、2、3、4、5、6,分别对应trace、debug、info、warn、error、critical、never,默认为info。
dnn 日志
关于 dnn 日志的配置,请阅读模型推理API手册章节中的 配置信息 一节内容。