精度调优工具使用指南
由于浮点转定点过程中存在误差,当您在使用量化训练工具时,难免会碰到量化模型精度掉点问题。通常来说,造成掉点的原因有:
-
原有浮点模型不利于量化,如存在共享 op 或共享结构。
-
QAT 网络结构或配置异常,如模型中存在没有 fuse 的 pattern,没有设置高精度输出等。
-
某些算子对量化比较敏感,该算子的量化误差在前向传播过程中逐层累积,最终导致模型输出误差较大。
针对上述情况,量化训练工具提供了精度调优工具来帮助您快速定位并解决精度问题,主要包括如下:
-
模型结构检查:检查模型中是否存在共享 op、没有 fuse 的 pattern 或者不符合预期的量化配置。
-
使用 QuantAnalysis 类 自动比对分析两个模型:通过对比定位到量化模型中异常算子或者量化敏感 op。
-
使用ModelProfiler 类 和 HbirModelProfiler 类 获得模型中每一个 op 的数值特征信息:获取的信息包括输入输出的最大最小值等。这两个类的功能完全一致,区别在于 HbirModelProfiler 仅接受 qat hbir 模型作为输入。通常您无需手动调用该模块,可以直接通过 QuantAnalysis.run 来获得两个模型的数值信息。
快速上手
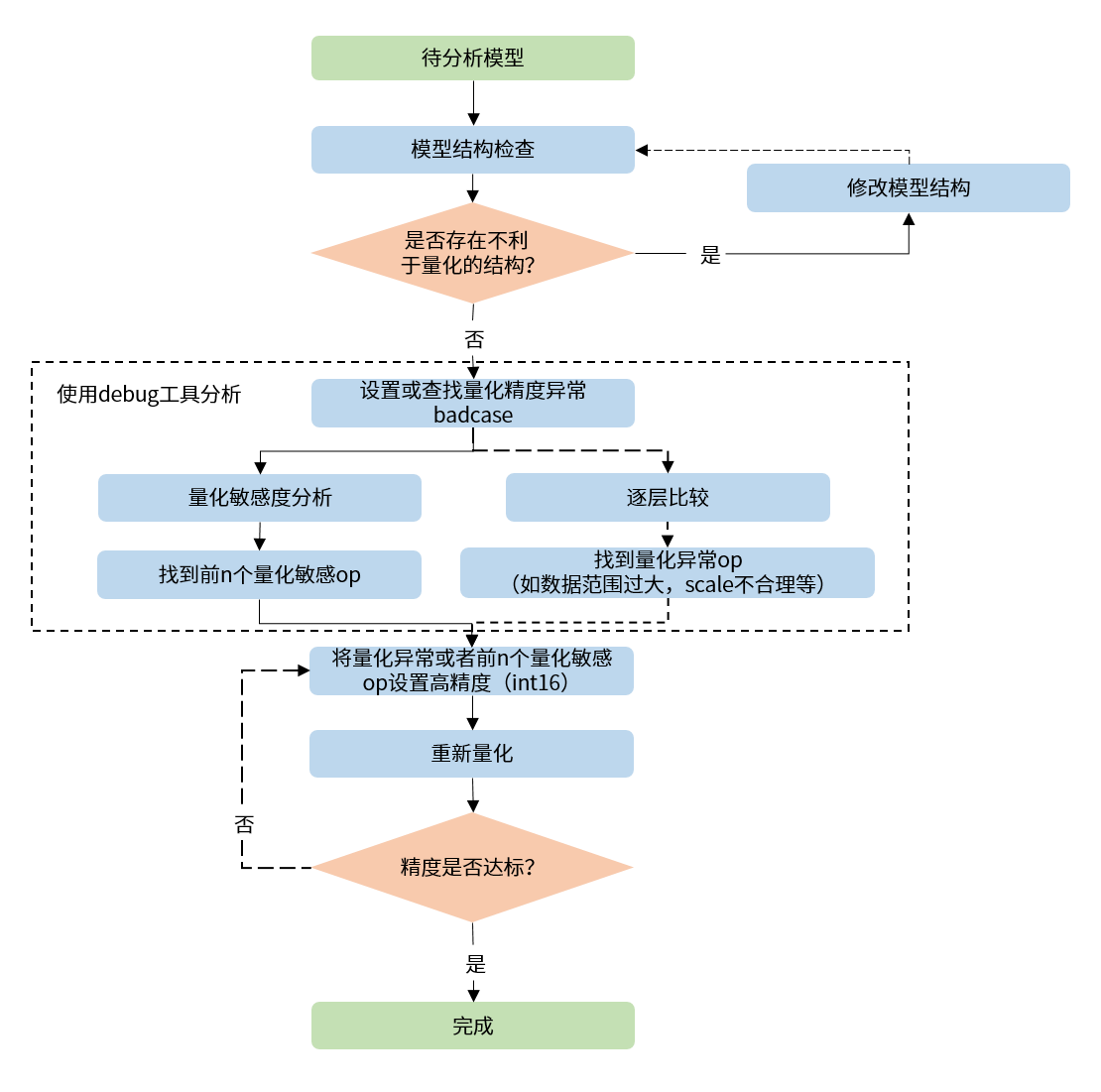
当碰到量化模型精度掉点问题时,我们推荐按照如下的流程使用精度调优工具。
-
检查模型中是否存在不利于量化的结构或者异常配置。
-
使用 QuantAnalysis 模块进行分析,具体步骤如下:
1). 找到一个基准模型和待分析模型输出相差最大的那个输入(即bad case)作为模型的输入。
2). 进行量化敏感度分析,目前的经验是 L1 敏感度排序前 n 个通常为量化敏感 op(不同的模型 n 的数值不一样,因此暂无自动确定的方法,需要手动尝试,如前 10 个,20 个...)。将量化敏感 op 设置高精度量化(如 int16 量化),重新进行量化流程。
3). 或者逐层比较两个模型的输入输出等信息,检查是否存在数据范围过大或者 scale 不合理等量化异常的 op,如某些具有物理含义的 op 应设置固定 scale。
整体的流程图如下:
一个完整的例子如下:
分析统计信息
在 QuantAnalysis 的 run() 接口被调用后,baseline_model 和 analysis_model 会使用 badcase 进行推理,并将模型每一层的输入输出保存在输出路径的 op_infos 文件夹下。
使用 torch.load 加载 opinfo 文件,可以得到算子的输入输出。使用 matplotlib 可以绘制对应的数值分布图。
在分析单算子误差时,可以构造只包含一个算子的模型,将 opinfo 中的输入送入模型,对比模型输出和 opinfo 输出的差异,绘制散点图或直方图。
多机多卡
QuantAnalysis 工具已支持多机多卡。若您已有 torch.nn.parallel.DistributedDataParallel 构建的训练环境,您只需将 train 函数替换成示例中的 quant_analysis 函数即可。
API Reference
模型结构检查
检查 calibration/qat 模型中是否存在不利于量化的结构以及量化 qconfig 配置是否符合预期。
参数
-
model: 待检查模型。
-
example_inputs: 模型输入。
-
save_results: 是否将检查结果保存到 txt 文件。默认 False。
-
out_dir: 结果文件 'model_check_result.txt' 的保存路径。默认空,保存到 .model_check_results/ 目录下。
输出
-
屏幕输出:检查出的异常层。
-
model_check_result.txt:在 save_results = True 时生成。主要由 5 部分组成:
1). 未 fuse 的 pattern。
2). 每个 module 的调用次数。正常每个 op 仅调用 1 次,0 表示未被调用,超过 1 次则表示被共享了多次。未调用或者共享多次的会有异常提示。
3). 每个 op 输出的 qconfig 配置。
4). 每个 op weight(如果有的话)的 qconfig 配置。
5). 异常 qconfig 提示(如果有的话)。
prepare接口已集成该检查。请您关注此接口输出的检查结果,并根据检查结果对模型做针对性的调整。
QuantAnalysis 类
QuantAnalysis 类可以自动寻找两个模型输出最大的 bad case,并以此作为输入,逐层比较两个模型的输出。此外,QuantAnalysis 类还提供计算敏感度功能,您可以尝试将敏感度排名 topk 的节点设置高精度,如 int16 量化,来提升量化模型精度。
参数
-
baseline_model: 基准模型(高精度)。
-
analysis_model:待分析的模型(精度掉点)。
-
analysis_model_type: 待分析的模型类型。支持输入:
-
fake_quant:待分析的模型可以是精度掉点的 calibration 模型,此时基准模型可以是原始浮点模型或者一个精度达标的 int8/int16 混合配置的 calibration 模型。
-
pre_export:待分析的模型是查表转定点的伪量化模型,基准模型是对应的原始伪量化模型。
-
export:待分析的模型是伪量化 hbir 模型,基准模型是对应的查表转定点的伪量化模型。
-
convert:待分析的模型是定点 hbir 模型,基准模型是对应的查表转定点的伪量化模型。
-
-
device_ids:对比分析时模型运行的 GPU 设备 index。
-
post_process:模型后处理。
-
out_dir:指定比较结果的输出目录。
由于 QAT 训练会改变模型 weight 分布,通常情况下,我们不建议您将浮点或 calibration 模型和 qat 模型做对比。
该类中各个 method 如下:
auto_find_bad_case
自动寻找导致两个模型输出最差的 badcase。
参数
-
data_generator:dataloader 或者一个自定义的迭代器,每次迭代产生一个数据。
-
num_steps:迭代 steps 次数。
-
metric:指定何种 metric 作为 badcase 的 metric。默认使用 ATOL 最差的结果。支持 COSINE/L1/ATOL。
-
device: 该参数已废弃。通过 QuantAnalysis 初始化时的
device_ids指定 GPU。 -
custom_metric_func:该参数已废弃。不再支持自定义 metric。
-
custom_metric_order_seq:该参数已废弃。不再支持自定义 metric。
-
cached_attrs:作为模型输入的某些属性。通常在时序模型中使用,如运行第二帧时,将第一帧的某些结果作为输入。
-
dump_in_run: 是否在运行过程中保存 badcase。
auto_find_bad_case函数遍历传入的 data_generator,运行基准模型和待分析模型,计算每个输出在 COSINE/L1/ATOL 3 种 metric 上的比较结果,并找到在各个 metric 上比较结果最差的 badcase 输入。
输出
-
badcase.txt:包含 3 部分内容
-
各个输出在不同 metric 下找到的 badcase 输入。(在 data_generator 中的索引值)。
-
各个输出在不同 metric 下找到的 badcase 输入对应的 metric 最差值。
-
相同 metric 指标下,输出最差的 badcase 输入。
-
-
badcase.pt:保存的输入数据,为参数
metric指定的 metric 指标最差的输入。作为run函数的默认输入。
set_bad_case
手动设置 badcase。
通常情况下,我们建议您通过 auto_find_bad_case函数寻找 badcase。若手动设置的 badcase 非真正的 badcase,分析工具很难找出量化敏感层。
参数
-
data: badcase 输入。
-
baseline_model_cached_attr:基准模型的 cached_attrs。
-
analysis_model_cached_attr:待分析模型的 cached_attrs。
load_bad_case
从指定的文件中加载 badcase。
参数
- filename:指定的文件路径。默认从初始化时指定的
out_dir目录中加载auto_find_bad_case函数保存的 badcase 相关文件。
save_bad_case
将 badcase 保存到 {self.out_dir}/badcase.pt 文件。
和 set_bad_case搭配使用。通常情况下,您无需手动调用此函数。
set_model_profiler_dir
手动指定 model_profiler 的输出保存路径。
某些情况下,在 QuantAnalysis 初始化之前,ModelProfiler 就已定义并运行,此时可以直接指定已有的 ModelProfiler 路径,跳过 QuantAnalysis 的 run 步骤,直接比较两个模型的输出。
参数
-
baseline_model_profiler_path:基准模型的 profiler 路径。
-
analysis_model_profiler_path:待分析模型的 profiler 路径。
run
运行两个模型并分别保存模型中每一层的结果。
参数
-
device:该参数已废弃。通过 QuantAnalysis 初始化时的
device_ids指定 GPU。 -
index:输入数据在 data_generator 中的 index。
仅支持 auto_find_bad_case 函数找到并在 badcase.txt中显示的 index 作为参数输入。
compare_per_layer
比较两个模型中每一层的结果。
参数
-
prefixes:指定 op 名字的前缀。
-
types:op 类型。
通常您无需指定 prefixes 和 types参数。若您基于一些先验经验,想跳过某些确定的、量化影响较小 op 的比较,或想节省时间,您可以通过两个参数,指定比较某些 op 或者某类 op。
输出
-
abnormal_layer_advisor.txt: 所有异常层,包括数据范围过大/包含 inf 或 NaN/输出没有高精度等情况。
-
compare_per_layer_out.txt: 以表格的形式展示模型中每层 layer 的具体信息,包括各种指标、数据范围、量化 dtype 等。从左到右每一列分别表示:
-
Index:op index。
-
mod_name:该 op 名字,若 op 为 module 类型,则显示该 module 在模型中的 prefix name,若为 function 类型,则不显示。
-
base_op_type:基准模型中该 op 的 type,可能是 module 类型或者 function 名称。
-
analy_op_type:待分析模型中该 op 的 type,可能是 module 类型或者 function 名称。
-
Shape:该 op 输出的 shape。
-
quant_dtype:该 op 输出的量化类型。
-
Qscale:该 op 输出的量化 scale。
-
Cosine:该 op 在两个模型中输出的余弦相似度。
-
L1:该 op 在两个模型中输出的 L1 距离。
-
Atol:该 op 在两个模型中输出的绝对误差。
-
max_qscale_diff:该 op 在两个模型中输出最大相差了几个 scale。
-
base_model_min:基准模型中该 op 输出的最小值。
-
analy_model_min:待分析模型中该 op 输出的最小值。
-
base_model_max:基准模型中该 op 输出的最大值。
-
analy_model_max:待分析模型中该 op 输出的最大值。
-
base_model_mean:基准模型中该 op 输出的平均值。
-
analy_model_mean:待分析模型中该 op 输出的平均值。
-
-
compare_per_layer_out.csv: 以 csv 的格式展示每层的具体信息。内容和 compare_per_layer_out.txt 完全一致,csv 文件的存储格式方便您通过 excel 等软件打开分析。
sensitivity
模型中各个节点的敏感度排序。适用于 float 转 calibration 的精度掉点问题。
参数
-
device:该参数已废弃。通过 QuantAnalysis 初始化时的
device_ids指定 GPU。 -
metric:相似度排序的 metric,默认 ATOL,支持 COSINE/L1/ATOL。
-
reserve:是否反序打印敏感度节点,以支持将某些 int16 算子退回 int8 来提升上板性能。
输出
-
sensitive_ops.txt。文件中按照量化敏感度从高到低的顺序排列 op。从左到右每一列分别表示:
-
op_name:op 名字。
-
sensitive_type:计算量化敏感的类型,包括:
-
activation:仅量化该 op 输出的量化敏感度。
-
weight:仅量化该 op 权重的量化敏感度。
-
input-{n}:仅量化该 op 第 n 个输入的量化敏感度。
-
-
op_type:op 类型。
-
metric:计算敏感度的指标。按照敏感度从高到低的顺序排序。支持以下几种指标。默认使用 L1。
-
L1:取值范围 [0, ],数值越大则该 op 对量化越敏感(从大到小排序)。
-
Cosine:取值范围 [0,1],越接近 0 则该 op 对量化越敏感(从小到大排序)。
-
ATOL:取值范围 [0, ],数值越大则该 op 对量化越敏感(从大到小排序)。
-
-
quant_dtype:该 op 输出的量化 dtype。通常为 qint8/qint16。
-
flops:该 op 的计算量以及在整个模型计算量中的占比。
-
-
sensitive_ops.pt。使用 torch.save 保存的敏感度排序的列表,方便您后续加载使用。若存在多个输出,则每个输出都会生成一个敏感度表。列表格式见返回值部分说明。
返回值
敏感度 List,List 中每个元素都是记录一个 op 敏感度信息的子 list。子 List 中从左到右每一项分别为 [op_name, sensitive_type, op_type, metric, quant_dtype, flops]。
整个 List 示例如下:
您可以将量化敏感度排名前 n 的 op 配置高精度(如 int16)来尝试提升量化模型精度。
clean
清除中间结果。仅保留比较结果等文件。
ModelProfiler 类
统计模型 forward 过程中,每一层算子的输入输出等信息。
参数
-
model: 需要统计的模型。
-
out_dir: 相关文件保存的路径。
该类仅支持通过 with 语句的方式使用。
该类中其中各个 method 如下:
get_info_manager
获得管理每个 op 信息的结构体。
返回值
管理存储的每个 op 信息的结构体 OpRunningInfoManager。其中两个重要的接口如下:
table
在一个表格中展示单个模型统计量。存储到 statistic.txt 文件中。
参数
-
out_dir:statistic.txt 文件的存储路径,默认 None,存储到 self.out_dir。
-
prefixes:需要统计的模型中 op 的 prefixes。默认统计所有 op。
-
types:需要统计的模型中 op 的 type。默认统计所有 op。
-
with_stack: 是否显示每个 op 在代码中对应的位置。
输出
statistic.txt 文件,从左到右每一列分别为:
-
Index:op index。
-
Op Name:op type,module 类名或者 function 名。
-
Mod Name:若是 module 类,则显示该 module 在模型中的 prefix name;若是 function 类型,则显示该 function 所在的 module prefix name。
-
Attr:input/output/weight/bias。
-
Dtype:tensor 的数据类型。
-
Scale:tensor 的 scale。
-
Min:当前 tensor 的最小值。
-
Max:当前 tensor 的最大值。
-
Mean:当前 tensor 的平均值。
-
Var:当前 tensor 中数值的方差。
-
Shape:tensor shape。
tensorboard
在 tensorboard 中显示每一层输入输出直方图。
参数
-
out_dir:tensorboard 相关文件保目录。默认保存到 self.out_dir/tensorboard 目录下。
-
prefixes:需要统计的模型中 op 的 prefixes。默认统计所有。
-
types:需要统计的模型中 op 的 type。默认统计所有。
-
force_per_channel:是否以 per_channel 量化的方式展示直方图。
输出
tensorboard 文件,打开后截图如下:
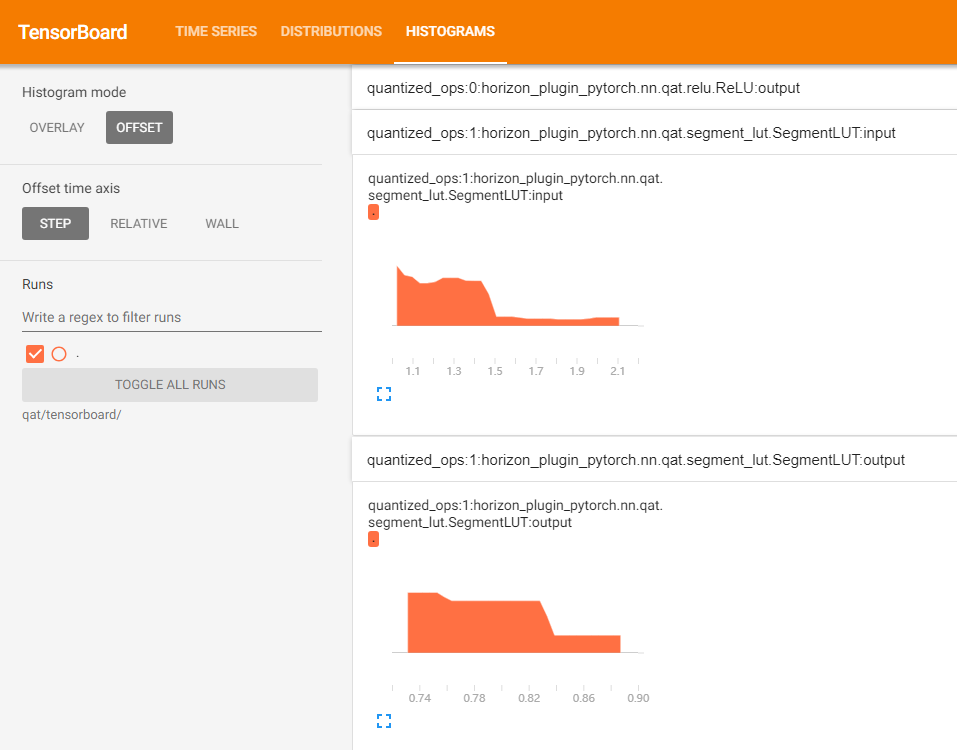
HbirModelProfiler 类
该类的功能和使用方式与 ModelProfiler 类完全一致。请参考 ModelProfiler 类 进行使用。
由于 hbir 模型的特殊格式,qat hbir 模型在 forward 时需添加索引 0。