模型量化编译
模型量化编译过程中,hb_compile工具会根据配置文件的具体信息,生成中间阶段onnx模型以及可用于上板部署的hbm模型。
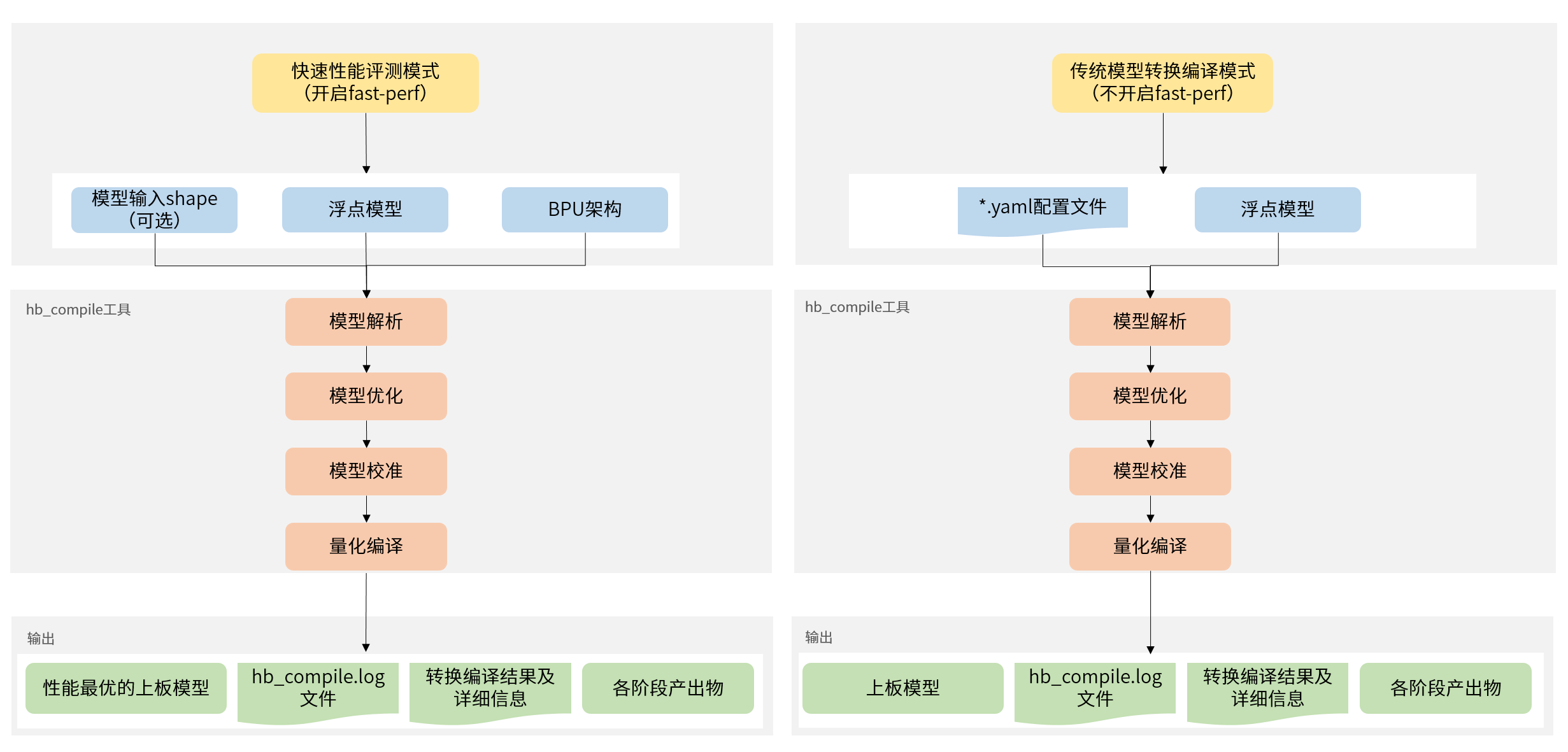
使用hb_compile工具对模型进行量化编译时,提供两种模式,快速性能评测模式(开启fast-perf)和传统模型转换编译模式(不开启fast-perf)。
注解
快速性能评测模式开启后,会在转换过程中生成可以在板端运行最高性能的hbm模型,工具内部主要进行以下操作:
- 将BPU可执行算子尽可能运行在BPU上。
- 删除模型首尾可删除的CPU算子,包括:Quantize/Dequantize、Transpose、Cast、Reshape等。
使用方法
Usage: hb_compile [OPTIONS]
A tool that maps floating-point models to quantized models and provides
some additional validation features
Options:
-h, --help Show this message and exit.
-c, --config PATH Model convert config file
-m, --model PATH Model to be compiled or modified
--proto PATH Caffe prototxt file
--march [nash-e|nash-m] BPU's micro architectures
-i, --input-shape <TEXT TEXT>...
Specify the model input shape, e.g. --input-
shape input1 1x3x224x224
--fast-perf Build with fast perf mode
命令行参数
| 参数名称 | 参数说明 |
-h, --help | 显示帮助信息并退出。 |
-c, --config | 模型编译的配置文件,为yaml格式,文件名使用.yaml后缀。 |
--fast-perf | 开启fast-perf,开启后,会在转换过程中生成可以在板端运行最高性能的hbm模型,方便您用于后续的模型性能评测。
如您开启了fast-perf,还需要进行如下配置:
-m, --model,Caffe或ONNX浮点模型文件。
--proto,用于指定Caffe模型prototxt文件。
--march,BPU的微架构。
- 使用S100处理器需设置为
nash-e。
- 使用S100P处理器需设置为
nash-m。
- 使用S600处理器需设置为
nash-p。
-i, --input-shape,可选参数,指定模型的输入节点的shape信息。
使用方式为:
- 指定单个输入节点的shape信息,使用方式为
--input-shape input_1 1x3x224x224。
- 指定多个输入节点的shape信息,使用方式为
--input-shape input_1 1x3x224x224 --input-shape input_2 1x3x224x224。
注意:
模型为非动态输入时,--input-shape可以不做配置,工具会自动读取模型文件中的尺寸信息。
模型为动态输入时:
- 如模型为单输入模型且未指定
--input-shape时,工具会将输入节点第一维为[-1, 0, ?]的模型的第一维默认设置为1。
- 如模型为多输入模型,必须配置此参数以指定每个输入的shape信息。
|
--skip | 如您在精度调试阶段,不关注compile流程及产出,可使用此参数配置为 compile,跳过编译阶段。 |
编译产生的log文件会储存在命令执行路径下面,名称为 hb_compile.log。
使用示例
快速性能评测模式
如您想使用快速性能评测模式(开启fast-perf),使用方式如下:
hb_compile --fast-perf --model ${caffe_model/onnx_model} \
--proto ${caffe_proto} \
--march ${march} \
--input-shape ${input_node_name} ${input_shape}
注意
- 请注意,如您开启快速性能评测模式,由于该模式下,工具会使用内置的高性能配置,请勿对
--config 参数进行配置。
- 在使用hb_compile做模型量化编译时,
--input-shape 参数配置仅在快速性能评测模式(即开启fast-perf)时生效。
传统模型转换编译模式
如您想使用传统模型转换编译模式(不开启fast-perf),使用方式如下:
hb_compile --config ${config_file}
配置文件具体参数信息
配置文件主要包含模型参数组、输入信息参数组、校准参数组、编译参数组。在您的配置文件中,每个参数组位置都需要存在,具体参数分为可选和必选,可选参数可以不配置。
以下是具体参数信息,参数会比较多,我们依照参数组次序介绍。可选/必选表示该参数项在配置文件中是否必须进行配置。
模型参数组
| 参数名称 | 参数配置说明 | 可选/必选 |
prototxt | 参数作用:指定Caffe浮点模型的prototxt文件名称。
参数类型:String。
取值范围:模型路径。
默认配置:无。
参数说明:模型为Caffe模型时必须配置。
参考示例: prototxt: 'mobilenet_deploy.prototxt'
| Caffe模型必选 |
caffe_model | 参数作用:指定Caffe浮点模型的caffemodel文件名称。
参数类型:String。
取值范围:模型路径。
默认配置:无。
参数说明:模型为Caffe模型时必须配置。
参考示例: caffe_model: 'mobilenet.caffemodel'
| Caffe模型必选 |
onnx_model | 参数作用:指定ONNX浮点模型的onnx文件名称。
参数类型:String。
取值范围:模型路径。
默认配置:无。
参数说明:模型为ONNX模型时必须配置。
参考示例: onnx_model: 'resnet50.onnx'
| ONNX模型必选 |
march | 参数作用:指定产出上板模型需要支持的平台架构。
参数类型:String。
取值范围:'nash-e'或'nash-m'或'nash-p'。
默认配置:无。
参数说明:这些可选配置值依次对应S100/S100P/S600处理器,根据您使用的平台选择。
参考示例: | 必选 |
output_model_file_prefix | 参数作用:指定转换产出上板模型的名称前缀。
参数类型:String。
取值范围:无。
默认配置:'model'。
参数说明:输出的定点模型文件的名称前缀。
参考示例: output_model_file_prefix: 'resnet50_224x224_nv12'
| 可选 |
working_dir | 参数作用:指定模型转换输出的结果的存放目录。
参数类型:String。
取值范围:无。
默认配置:'model_output'。
参数说明:若该目录不存在,则工具会自动创建目录。
参考示例: working_dir: './model_output'
| 可选 |
output_nodes | 参数作用:指定模型的输出节点。
参数类型:String。
取值范围:模型中的节点名称 。
默认配置:无。
参数说明:此参数用于支持您指定节点作为模型输出,设置值需为模型中的具体节点名称。
多个值的配置方法请参考 param_value配置 小节的说明。
参考示例: | 可选 |
remove_node_type | 参数作用:设置删除节点的类型。
参数类型:String。
取值范围:"Quantize"、 "Transpose"、 "Dequantize"、 "Cast"、 "Reshape"、 "Softmax"。
不同类型用;分割。
默认配置:无。
参数说明:不设置或设置为空不影响模型转换过程。此参数用于支持您设置待删除节点的类型信息。
被删除的节点必须在模型的开头或者末尾,与模型的输入或输出连接。
多个值的配置方法请参考 param_value配置 小节的说明。
参考示例: remove_node_type: "Dequantize"
注意:设置此参数后,我们会根据您的设置对模型的可删除节点进行匹配,如果您配置的待删除节点类型符合删除条件,即会进行删除,并重复此操作,直到可删除节点不能与配置的节点类型匹配为止。 | 可选 |
remove_node_name | 参数作用:设置删除节点的名称。
参数类型:String。
取值范围:模型中待删除的节点名称,不同类型用;分割。
默认配置:无。
参数说明:不设置或设置为空不影响模型转换过程。此参数用于支持您设置待删除节点的名称。
被删除的节点必须在模型的开头或者末尾,与模型的输入或输出连接。
多个值的配置方法请参考 param_value配置 小节的说明。
参考示例: remove_node_name: "OP_name"
注意:设置此参数后,我们会根据您的设置对模型的可删除节点进行匹配,如果您配置的待删除节点名称符合删除条件,即会进行删除,并重复此操作,直到可删除节点不能与配置的节点名称匹配为止。 | 可选 |
debug_mode | 参数作用:设置调试参数用于精度分析。
参数类型:String。
取值范围:dump_all_layers_output、dump_calibration_data
默认配置:无。
参数说明: dump_all_layers_output参数指定保留上板模型中间层的输出值,输出中间层的值是调试需要用到的手段,常规状态下请不要开启。dump_calibration_data参数指定保存用于精度debug分析的校准数据,数据格式为.npy。该数据通过np.load()可直接送入模型进行推理。若不设置此参数,您也可自行保存数据并使用精度debug工具进行精度分析。
参考示例:debug_mode: 'dump_all_layers_output'
注意:设置dump_all_layers_output后,暂时不支持配置input_source为resizer。 | 可选 |
输入信息参数组
| 参数名称 | 参数配置说明 | 可选/必选 |
input_name | 参数作用:指定原始浮点模型的输入节点名称。
参数类型:String。
取值范围:单输入时 "" 或输入节点名称,多输入时 "input_name1; input_name2; input_name3..."。
默认配置:无。
参数说明:浮点模型只有一个输入节点情况时可选配置, 多于一个输入节点时必须配置以保证后续类型及校准数据输入顺序的准确性。
多个值的配置方法请参考 param_value配置。
参考示例: | 动态输入时必选
非动态输入时:
单输入时可选
多输入时必选 |
input_type_train | 参数作用:指定原始浮点模型的输入数据类型。
参数类型:String。
取值范围:'rgb'、'bgr'、'yuv444'、'gray'、'featuremap'。
默认配置:'featuremap'。
参数说明:每一个输入节点都需要配置一个确定的输入数据类型, 存在多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。
多个值的配置方法请参考 param_value配置。
数据类型的选择请参考:转换内部过程解读 部分的介绍。
参考示例: | 可选 |
input_type_rt | 参数作用:转换后上板模型需要适配的输入数据格式。
参数类型:String。
取值范围:'rgb'、'bgr'、'yuv444'、'nv12'、'gray'、'featuremap'。
默认配置:'featuremap'。
参数说明:这里是指明您需要使用的数据格式。
不要求与原始模型的数据格式一致。
但是需要注意在边缘平台喂给模型的数据是使用这个格式。
每一个输入节点都需要配置一个确定的输入数据类型,存在多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。
多个值的配置方法请参考 param_value配置。
数据类型的选择请参考: 转换内部过程解读 部分的介绍。
参考示例: 注意: 当 input_type_rt 配置为featuremap非四维输入时,请勿配置 mean_value 、 scale_value 及 std_value 参数。 | 可选 |
input_layout_train | 参数作用:指定原始浮点模型的输入数据排布。
参数类型:String。
取值范围:'NHWC'、'NCHW'。
默认配置:无。
参数说明:每一个输入节点都需要配置一个确定的输入数据排布,这个排布必须与原始浮点模型所采用的数据排布相同。存在多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。
多个值的配置方法请参考 param_value配置。
什么是数据排布请参考: 转换内部过程解读 部分的介绍。
参考示例: input_layout_train: 'NCHW'
| 模型输入类型非featuremap时必选
模型输入类型为featuremap时配置不生效,无需配置 |
input_space_and_range | 参数作用:指定输入数据格式的特殊制式。
参数类型:String。
取值范围:'regular'、'bt601_video'。
默认配置:'regular'。
参数说明:这个参数是为了适配不同ISP输出的yuv420格式, 在相应 input_type_rt 为 nv12 时,该配置才有效,非 nv12 时会报错并退出。
regular 是常见的yuv420格式,数值范围为 [0,255];bt601_video 是另一种视频制式yuv420,数值范围为 [16,235]。 更多关于bt601的信息可以通过网络资料进行了解。
bt601_video 仅在 input_type_train 配置为bgr或rgb时支持指定。
参考示例:input_space_and_range: 'regular'
注意:在没有明确需要的情况下,您不要配置此参数。 | 可选 |
input_shape | 参数作用:指定原始浮点模型的输入数据尺寸。
参数类型:String。
取值范围:无。
默认配置:无。
参数说明:shape的几个维度以 x 连接,例如 '1x3x224x224'。
原始浮点模型为非动态输入时可以不配置,工具会自动读取模型文件中的尺寸信息。
如需配置多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。
多个值的配置方法请参考 param_value配置。
参考示例: input_shape: '1x3x224x224'
| 动态输入时必选
非动态输入时可选 |
input_batch | 参数作用:指定转换后上板模型需要适配的输入batch数量。
参数类型:Int。
取值范围:1-4096。
默认配置:1。
参数说明:这里input_batch为转换后上板hbm模型输入batch数量。该参数仅支持配置一个数值,模型为多输入时,配置后该值将作用于模型的所有输入。
此参数不配置时默认为1。
参考示例: 注意:- 此参数仅在
input_shape 第一维为1的时候可以使用;模型为多输入时,需要所有输入的 input_shape 第一维均为1。
- input_type_rt配置为nv12或gray或input_source配置为pyramid或resizer时,即模型输入为pyramid/resizer时,仅支持图像输入,此时如您对input_batch进行配置,需要将separate_batch设置为True开启独立batch模式或者在separate_name中配置对应输入节点进行拆分。
- 此参数仅在原始onnx模型本身支持多batch推理时才能生效。 但是由于算子情况复杂,若在模型转换过程中, 遇到提示模型不支持配置input_batch参数的转换失败log,请您尝试直接导出一个多batch的onnx模型并正确配置校准数据大小重新进行转换 (此时不再需要配置此参数)。
| 可选 |
separate_batch | 参数作用:设置是否开启独立batch模式。
参数类型:Bool。
取值范围:True、False。
默认配置:False。
参数说明:在配置了input_batch参数时,该参数配置才有效。
此参数不配置时,默认为False,即不开启独立batch模式。
独立batch模式不开启的情况下,输入需要被分配到一个连续的内存区域内。例如,模型输入为1x3x224x224,input_batch设置为N,则您需要准备的上板模型输入为Nx3x224x224。
而独立batch模式开启的情况下,内部会对开启此模式的输入节点做拆分,拆分数量为您通过input_batch指定的数值,您可以针对每个batch单独准备输入,此模式下不再要求输入必须被分配在连续的内存区域内。
例如,模型输入为1x3x224x224,input_batch设置为N, 此时您需要准备的上板模型输入则为N个1x3x224x224。
参考示例: | 可选 |
separate_name | 参数作用:不开启独立batch模式时,用于指定拆分的节点名称。
参数类型:String。
取值范围:单输入时 "" 或输入节点名称,多输入时 "separate_name1; separate_name2; separate_name3..."。
默认配置:无。
参数说明:在separate_batch为False且配置了input_batch时,该参数配置才有效,内部会按照指定的输入节点名称做拆分。
确保需拆分的节点在input_name输入范围内,如需拆分多个输入节点时,多个值的配置方法请参考 param_value配置。
参考示例: | 可选 |
mean_value | 参数作用:指定预处理方法的图像减去的均值。
参数类型:Float。
取值范围:无。
默认配置:无。
参数说明:对于每一个输入节点而言,存在两种配置方式:
第一种是仅配置一个数值,表示所有通道都减去这个均值。
第二种是提供与通道数量一致的数值(这些数值以空格分隔开),表示每个通道都会减去不同的均值。
如果存在某个节点不需要 mean 处理,则为该节点配置 'None'。
参数的设置形式为:mean_value: 'value',参数存在多个值时使用 ';' 符号分隔:mean_value: 'value1;value_2;value3'。
而若'value'存在多个值时,可使用空格或 ',' 进行分隔: mean_value: 'value11 value12 value13;value21 value22 value23;...' 或 mean_value: 'value11,value12,value13;value21,value22,value23;...'。
参考示例: mean_value: '103.94 116.78 123.68'
| 可选 |
scale_value | 参数作用:指定预处理方法的数值scale系数。
参数类型:Float。
取值范围:无。
默认配置:无。
参数说明:指定预处理方法的数值系数时,此参数与 std_value 参数仅需指定一项,scale_value = 1/std_value。
对于每一个输入节点而言,存在两种配置方式:
第一种是仅配置一个数值,表示所有通道都乘以这个系数。
第二种是提供与通道数量一致的数值(这些数值以空格分隔开), 表示每个通道都会乘以不同的系数。
如果存在某个节点不需要 scale 处理,则为该节点配置 'None'。
参数的设置形式为:scale_value: 'value',参数存在多个值时使用 ';' 符号分隔:scale_value: 'value1;value_2;value3'。
而若'value'存在多个值时,可使用空格或 ',' 进行分隔:scale_value: 'value11 value12 value13;value21 value22 value23;...' 或 scale_value: 'value11,value12,value13;value21,value22,value23;...'。
参考示例: | 可选 |
std_value | 参数作用:指定预处理方法的数值std系数。
参数类型:Float。
取值范围:无。
默认配置:无。
参数说明:指定预处理方法的数值系数时,此参数与 scale_value 参数仅需指定一项,std_value = 1/scale_value。
对于每一个输入节点而言,存在两种配置方式:
第一种是仅配置一个数值,表示所有通道都除以这个系数。
第二种是提供与通道数量一致的数值(这些数值以空格分隔开), 表示每个通道都会除以不同的系数。
如果存在某个节点不需要 std 处理,则为该节点配置 'None'。
参数的设置形式为:std_value: 'value',参数存在多个值时使用 ';' 符号分隔:std_value: 'value1;value_2;value3'。
而若'value'存在多个值时,可使用空格或 ',' 进行分隔: std_value: 'value11 value12 value13;value21 value22 value23;...' 或 std_value: 'value11,value12,value13;value21,value22,value23;...'。
参考示例: | 可选 |
input_type_rt/ input_type_train补充说明
由于摄像头获取到的数据类型通常是nv12。
因此,如果您在模型训练时使用rgb(NCHW)输入格式,但是想使这个模型能够高效处理nv12数据,只需要在模型转换时做如下配置:
input_parameters:
input_type_rt: 'nv12'
input_type_train: 'rgb'
input_layout_train: 'NCHW'
除了将输入数据转换为nv12,我们还支持您在训练和runtime infer时使用不同的rgb-order。工具会根据 input_type_rt 和 input_type_train 指定的数据格式自动添加数据转换节点,
根据地平线的实际生产经验,并不是任意type组合都是需要的,为了避免您误用,我们只开放了一些固定的type组合如下表(Y为已支持类型,N为暂不支持类型,
表格中第一行是 input_type_rt 中支持的类型,第一列是 input_type_train 支持的类型):
| input_type_train \ input_type_rt | nv12 | yuv444 | rgb | bgr | gray | featuremap |
|---|
| yuv444 | Y | Y | N | N | N | N |
| rgb | Y | Y | Y | Y | N | N |
| bgr | Y | Y | Y | Y | N | N |
| gray | N | N | N | N | Y | N |
| featuremap | N | N | N | N | N | Y |
注解
为了配合计算平台对于输入数据类型的要求,减小推理开销,对于 input_type_rt 类型为 rgb(NHWC/NCHW)/bgr(NHWC/NCHW) 的配置,转换工具转换出的模型,
其输入数据类型均为 int8。也就是说,对于常规的图像数据,需要-128使用(该操作在API中已自动进行,无需再进行该操作)。
在转换得到的最终产出hbm模型中, input_type_rt 到 input_type_train 是一个内部的过程,您只需要关注 input_type_rt 的数据格式即可。
正确理解每种input_type_rt的要求,对于嵌入式应用准备推理数据很重要,以下是对input_type_rt每种格式的说明:
-
rgb、bgr和gray都是比较常见的图像格式,注意每个数值都采用UINT8表示。
-
yuv444是一种常见的图像格式,注意每个数值都采用UINT8表示。
-
nv12是常见的yuv420图像格式,每个数值都采用UINT8表示。
-
nv12有个比较特别的情况是 input_space_and_range 设置 bt601_video 时,较于常规nv12情况,它的数值范围由[0,255]变成了[16,235],每个数值仍然采用UINT8表示。
请注意, bt601_video 仅在 input_type_train 为 bgr 或 rgb 时支持通过 input_space_and_range 进行配置。
-
featuremap适用于以上列举格式不满足您需求的情况,此type每个数值采用float32表示。例如雷达和语音等模型处理就常用这个格式。
小技巧
以上 input_type_rt 与 input_type_train 是固化在工具链的处理流程中,如果您非常确定不需要转换,将两个 input_type 设置成一致即可,
一样的 input_type 会做直通处理,不会影响模型的实际执行性能。
同样的,数据前处理也是固化在流程中,如果您不需要做任何前处理,不对 mean_value 、scale_value 及 std_value 进行配置即可,不会影响模型的实际执行性能。
注意
如果您设置的 input_type_rt 和 input_type_train 不一致且为rgb/bgr/yuv444,或者对 mean_value 、scale_value 及 std_value 等前处理相关参数进行了设置,
工具在进行模型转换编译过程中,内部会插入预处理节点进行处理,而预处理节点仅支持NHWC输入,所以如果原始输入模型若数据排布为NCHW,HBIR和HBM模型的数据排布会变为NHWC,此变化不影响模型性能和精度。
校准参数组
| 参数名称 | 参数配置说明 | 可选/必选 |
cal_data_dir | 参数作用:指定模型校准使用的标定样本的存放目录。
参数类型:String。
取值范围:无。
默认配置:无。
参数说明:目录内校准数据需要符合输入配置的要求。
具体请参考 模型校准集准备 部分的介绍。配置多个输入节点时,设置的节点顺序需要与 input_name 里的顺序严格保持一致。
多个值的配置方法请参考 param_value配置。
参考示例: cal_data_dir: './calibration_data'
注意: 当您没有配置该参数时,系统会进行伪校准方便您快速验证,此时模型没有精度信息,仅供功能测试。 | 可选 |
quant_config | 参数作用:计算平台支持对多种与量化相关的参数进行灵活配置,您可以通过该参数配置模型算子的计算精度、校准方法以及校准参数搜索方法。
参数类型:String/Dict。
取值范围:json文件路径或者字典形式的配置参数。
默认配置:无。
参数说明:该参数能够从多个层面(model_config、op_config、node_config)对计算精度进行配置,
并且支持多种计算精度数据类型(int8/int16/float16),支持多种校准方法(kl/max)的配置,支持从不同粒度(modelwise/layerwise)搜索校准参数,
详细说明请参考quant_config说明。
参考示例:
quant_config: './quant_config.json'
quant_config: {
// 配置模型层面的参数
"model_config": {
// 一次性配置所有节点的输入数据类型
"all_node_type": "int16"/"float16",
// 配置模型输出的数据类型
"model_output_type": "int8"/"int16",
}
}
| 可选 |
编译参数组
| 参数名称 | 参数配置说明 | 可选/必选 |
compile_mode | 参数作用:编译策略选择。
参数类型:String。
取值范围:'latency'、'bandwidth'、'balance'。
默认配置:'latency'。
参数说明:latency 以优化推理时间为目标。
bandwidth 以优化ddr的访问带宽为目标。
balance 平衡优化目标latency和bandwidth,设置为此项需指定balance_factor。
如果模型没有严重超过预期的带宽占用,建议您使用 latency 策略。
参考示例: | 可选 |
balance_factor | 参数作用:当compile_mode被指定为balance时,用于指定balance比率。
参数类型:Int。
取值范围:0-100。
默认配置:无。
参数说明:该参数仅在compile_mode被指定为balance时配套使用, 其余模式下配置不生效。
- 配置为0表示带宽最优,对应compile_mode为bandwidth的编译策略。
- 配置为100表示性能最优,对应compile_mode为latency的编译策略。
参考示例: | compile_mode为balance时必选 |
core_num | 参数作用:模型运行核心数。
参数类型:Int。
取值范围:该参数对于不同平台,可配置取值不同:
- 对于S100/S100P平台仅可配置为
1。
- 对于S600平台可选配置为
[1,2]。
默认配置:1。
参数说明:用于配置模型运行在地平线平台的核心数,配置核心数大于1时,可对输入模型进行张量并行编译,在多个核心上完成对同一模型的推理。
参考示例: | 可选 |
optimize_level | 参数作用:模型编译的优化等级选择。
参数类型:String。
取值范围:'O0'、'O1'、'O2'。
默认配置:'O2'。
参数说明:优化等级可选范围为 O0 ~ O2。
O0 不做任何优化, 编译速度最快,优化程度最低。
O1 - O2 随着优化等级提高, 预期编译后的模型的执行速度会更快, 但是所需编译时间也会变长。
参考示例: | 可选 |
input_source | 参数作用:设置上板hbm模型的输入数据来源。
参数类型:Dict。
取值范围:ddr,pyramid,resizer。
默认配置:无,默认会根据input_type_rt的值从可选范围中自动选择:
- input_type_rt配置为nv12或gray时,input_source默认自动选择为pyramid。
- input_type_rt配置为其他值时,input_source默认自动选择为ddr。
- 该参数配置为resizer时,input_type_rt仅支持配置为nv12或gray。
参数说明:这个参数是适配工程环境的选项, 建议您已经全部完成模型检查后再配置。
ddr 表示数据来自内存,pyramid 和 resizer 表示来自处理器上的固定硬件。
此参数配置有些特殊,例如模型输入名称为 data,数据源为内存(ddr),则此处应该配置值为 {"data": "ddr"}。
参考示例:input_source: {"data": "pyramid"}
| 可选 |
max_time_per_fc | 参数作用:指定模型的每个function call的最大可连续执行时间(单位μs)。
参数类型:Int。
取值范围:0或1000-4294967295。
默认配置:0。
参数说明:编译后的数据指令模型在BPU上进行推理计算时, 它将表现为1个或者多个function-call(BPU的执行粒度)的调用。 取值为0代表不做限制。
该参数用来限制每个function-call最大的执行时间, 模型只有在单个function-call执行完时才有机会被抢占。
详情参见 模型优先级控制 部分的介绍。
参考示例: 注意:- 此参数仅用于实现模型抢占功能,如无需实现该功能则可以忽略。
- 模型抢占功能仅支持在板端实现,不支持模拟器实现。
| 可选 |
jobs | 参数作用:设置编译hbm模型时的进程数。
参数类型:Int。
取值范围:机器支持的最大核心数范围内。
默认配置:16。
参数说明:在编译hbm模型时,用于设置进程数。 一定程度上可提高编译速度。
参考示例: | 可选 |
advice | 参数作用:用于提示模型编译后预估的耗时增加的情况,单位是微秒。
参数类型:Int。
取值范围:自然数。
默认配置:0。
参数说明:模型在编译过程中,工具链内部会进行耗时分析。而实际过程中,如算子做数据对齐等操作时会导致耗时有所增加,设置该参数后,
当某个OP的实际计算耗时与理论计算耗时的偏差大于您指定的值时,会打印相关log,包括耗时变化的信息、数据对齐前后的shape以及padding比例等信息。
参考示例: | 可选 |
cache_path | 参数作用:用于配置编译缓存的路径。
参数类型:路径支持大小写字母(a-z,A-Z)、数字(0-9)、下划线(_)、短横线(-)、句点(.)以及组合使用。
取值范围:无。
默认配置:无。配置此路径后默认您开启编译缓存配置。
参数说明:通过配置编译缓存的路径可启用cache缓存加速,cache缓存加速能够有效减少二次编译时间,提升编译速度。
若您配置的编译缓存路径已存在且为有效路径,则该路径下将自动创建目标内容。
注意:请不要在您配置的缓存目录下再存放其他自有文件,以防在删除缓存目录时自有文件会被一并删除。
参考示例: | 可选 |
cache_mode | 参数作用:用于设置编译缓存模式。
参数类型:String。
取值范围:enable、force_overwrite、disable。
默认配置:disable。
参数说明:
enable:表示启用编译缓存。启用后,可以避免相同编译参数及算子参数的子图重复编译,从而提升编译速度。force_overwrite:表示启用算子编译缓存功能,区别于enable模式,force_overwrite模式下会强制刷新本次命中缓存,即先删除本次命中已有缓存,再重新编译并加入缓存。disable:表示禁用编译缓存,重新编译。
参考示例: | 可选 |
max_l2m_size | 参数作用:用于设置启用数据存储L2M。
参数类型:NoneType/Int。
取值范围:该参数对于不同平台,可配置取值不同:
- 对于S100/S100P平台,不支持L2M,仅可配置为
0。
- 对于S600平台可选配置为
None或[0,24x1024x1024]。
默认配置: 0。
参数说明:
0:表示不启用L2M。None:表示启用L2M,但不对L2M的大小进行指定,启用大小由工具内部自动分配。[1,24x1024x1024]:表示启用L2M并指定可用的L2M大小。
参考示例: | 可选 |
extra_params | 参数作用:通过此参数,可以额外对一些模型编译相关的参数进行灵活地配置。
参数类型:Dict。
取值范围:input_no_padding、output_no_padding。
默认配置:{}。
参数说明:参数支持用于配置以下功能(支持同时配置):
- input_no_padding:如果不配置,默认为False。配置为True,则会对模型所有非图像的输入进行去padding操作。
- output_no_padding:如果不配置,默认为False。配置为 True,则会对模型所有输出进行去padding操作。
注意:extra_params参数不可重复配置,若要同时配置,写法可见如下参考示例。
参考示例:- 单独配置 input_no_padding
extra_params: {"input_no_padding": True}
- 单独配置 output_no_padding
extra_params: {"output_no_padding": True}
- 同时配置
extra_params: {"input_no_padding": True, "output_no_padding": True}
| 可选 |
param_value配置
具体参数的设置形式为:param_name: 'param_value' ,参数存在多个值时使用 ';' 符号分隔:param_name: 'param_value1;param_value2;param_value3' 。
小技巧
当模型为多输入模型时,强烈建议您将 input_shape 等参数们显式的写出,以免造成参数对应顺序上的错误。
注意
请注意,如果设置 input_type_rt 为 nv12,则模型的输入尺寸中不能出现奇数。
配置文件模板
此处以Resnet50模型为例,一份完整的配置文件模板如下:
注解
此处配置文件仅作展示,在实际配置文件中,需要根据您传入的原始浮点模型类型进行判断,caffe_model 与 onnx_model 两种只存在其中之一。
若为Caffe模型,则需传入 caffe_model + prototxt;若为Onnx模型,则传入 onnx_model 即可。
即 caffe_model + prototxt 或者 onnx_model 二选一。
# 模型参数组
model_parameters:
# 原始Onnx浮点模型文件
onnx_model: '../../01_common/model_zoo/mapper/classification/resnet50/resnet50.onnx'
# 转换的目标处理器架构
march: 'nash-e'
# 模型转换输出的用于上板执行的模型文件的名称前缀
output_model_file_prefix: 'resnet50_224x224_nv12'
# 模型转换输出的结果的存放目录
working_dir: './model_output'
# 批量删除某一类型的节点
remove_node_type: "Dequantize"
# 输入信息参数组
input_parameters:
# 原始浮点模型的输入节点名称
input_name: ""
# 原始浮点模型的输入数据格式(数量/顺序与input_name一致)
input_type_train: 'rgb'
# 原始浮点模型的输入数据排布(数量/顺序与input_name一致)
input_layout_train: 'NCHW'
# 原始浮点模型的输入数据尺寸
input_shape: '1x3x224x224'
# 网络实际执行时,输入给网络的batch_size,默认值为1
input_batch: 1
# 预处理方法的图像减去的均值, 如果是通道均值,value之间必须用空格分隔
mean_value: '123.675 116.28 103.53'
# 预处理方法的图像缩放比例,如果是通道缩放比例,value之间必须用空格分隔
scale_value: '0.01712475 0.017507 0.01742919'
# 转换后上板模型需要适配的输入数据格式(数量/顺序与input_name一致)
input_type_rt: 'nv12'
# 输入数据格式的特殊制式
input_space_and_range: 'regular'
# 校准参数组
calibration_parameters:
# 模型校准使用的标定样本的存放目录
cal_data_dir: './calibration_data_rgb'
# 编译参数组
compiler_parameters:
# 编译策略选择
compile_mode: 'latency'
# 模型运行核心数
core_num: 1
# 模型编译的优化等级选择
optimize_level: 'O2'
# 指定模型的每个function call的最大可连续执行时间
max_time_per_fc: 1000
# 指定编译模型时的进程数
jobs: 8