数据准备
在对模型进行校准和推理之前,需要对数据进行预处理操作,以满足模型的要求。这就需要我们做一些数据准备,下方我们分别为您详细介绍模型校准集和推理准备的步骤。
模型校准集准备:由于模型校准过程的准确性与输入数据的正确性紧密相关,为了得到正确校准结果,确保校准后模型的精度效果,我们需要对模型校准集进行准备, 此过程需要使用与训练或验证集相似的样本,确保校准样本经过与原始浮点模型一致的数据预处理,从而保证数据类型、尺寸和layout的一致性。
模型推理准备:HBRuntime支持多种模型推理场景(ONNX模型、HBIR模型、HBM模型),为了保证正确的推理结果,在推理过程中使用的输入数据需要进行必要的预处理和转换,以满足模型要求。 例如,Pyramid输入,Resizer输入以及多Batch拆分等场景,都会导致模型结构发生改变,需要进行相应的处理及数据准备。
接下来,我们将从这两个方面,分别介绍模型在校准/推理前所需的处理及数据准备工作。
模型校准集准备
如果本过程,您需在示例文件夹内进行,那么您需要先执行文件夹中的 00_init.sh 脚本以获取对应的原始模型和数据集。
在进行模型校准时,需要20~100份的标定样本输入,每一份样本都是一个独立的数据文件。为了确保校准后模型的精度效果,我们希望这些校准样本来自于您训练模型使用的训练集或验证集,不要使用非常少见的异常样本,例如纯色图片、不含任何检测或分类目标的图片等。
您需要把取自训练集/验证集的样本进行前处理(前处理过程与原始浮点模型数据前处理过程一致),处理完后的校准样本会与原始浮点模型具备一样的数据类型(input_type_train)、尺寸(input_shape) 和 layout(input_layout_train),
您可以通过 numpy.save 命令将数据保存为npy文件,工具链校准时会基于 numpy.load 命令进行读取。数据前处理的运行流程,如图所示:
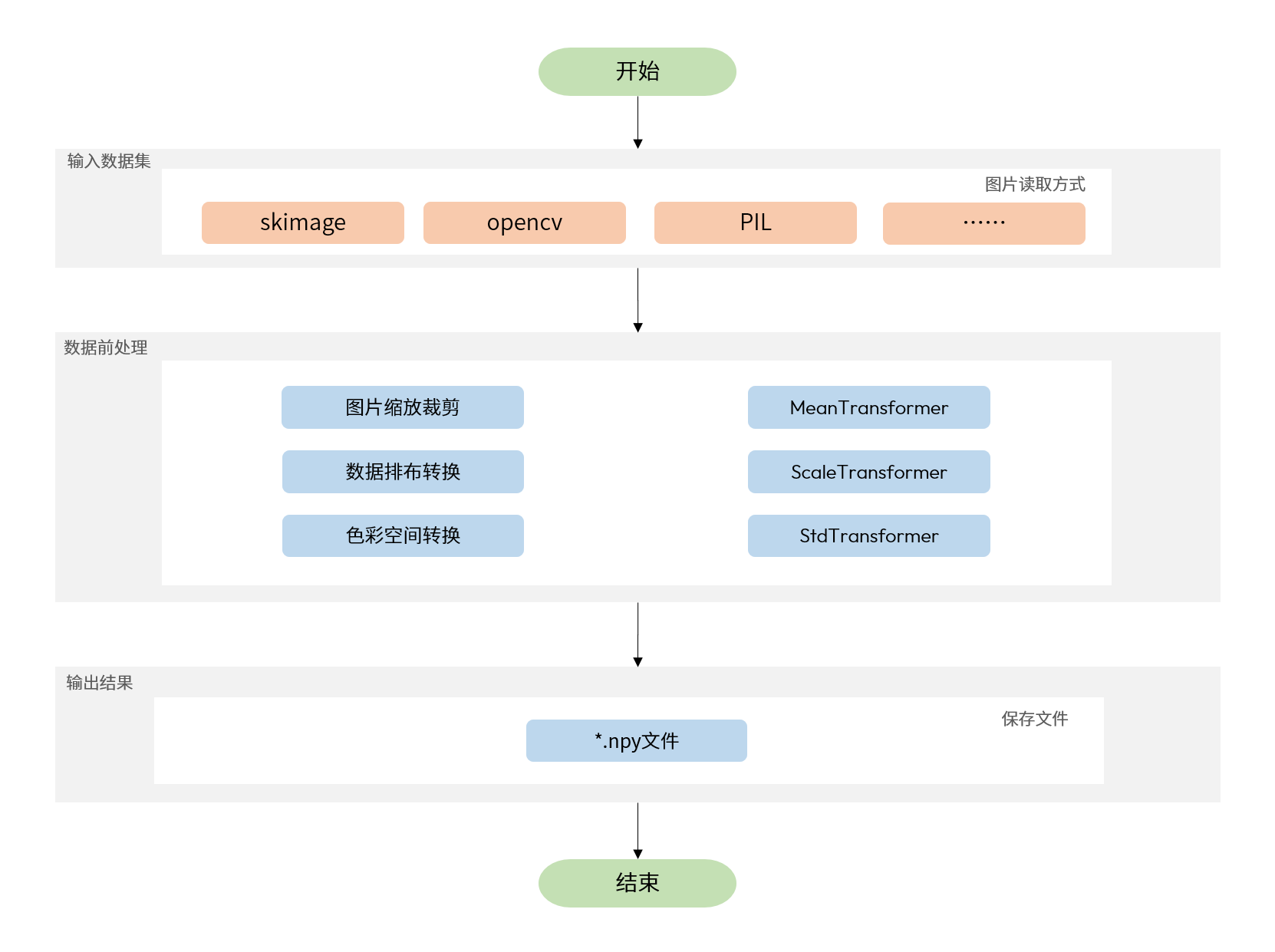
例如,有一个使用ImageNet训练的用于分类的原始浮点模型,它只有一个输入节点,输入信息描述如下:
-
输入类型:
BGR。 -
输入layout:
NCHW。 -
输入尺寸:
1x3x224x224。
原始浮点模型进行数据前处理时的步骤如下:
-
图像长宽等比scale,短边缩放到256。
-
center_crop方法获取224x224大小图像。 -
对齐输入layout为模型所需的
NCHW。 -
转换色彩空间为模型所需的
BGR。 -
图像数值范围调整为模型所需的[0, 255]。
-
按通道减mean。
-
数据乘以scale系数。
针对上述举例模型的样本处理代码如下(为避免过长代码篇幅,各种简单transformer实现代码未贴出,transformer使用方法可参考 图片处理transformer说明 ):
请注意,yaml文件中input_shape参数作用为指定原始浮点模型的输入数据尺寸。若为动态输入模型则可通过这个参数设置转换后的输入大小,而校准数据的shape大小应与input_shape保持一致。
例如:若原始浮点模型输入节点shape为?x3x224x224("?"号代表占位符,即该模型第一维为动态输入),转换配置文件中设置input_shape: 8x3x224x224,则需要准备的每份校准数据大小为8x3x224x224。(请知悉,此类输入shape第一维不等于1的模型,不支持通过input_batch参数修改模型batch信息。)
模型推理准备
如上文所述,为确保输入数据符合模型要求,在模型推理前需要对输入数据进行相应的处理。下面将分别针对ONNX模型推理以及HBIR/HBM模型推理,为您介绍模型推理前的数据准备。
ONNX模型推理准备
在经过图优化、校准过程后,生成的ONNX模型(*_optimized_float_model.onnx、*_calibrated_model.onnx和*_ptq_model.onnx)的输入数据与原始浮点模型的输入保持一致。
若您在yaml文件中未配置input_batch参数,只需确保输入数据与原始浮点模型相同即可。
若您在yaml文件中将input_batch设置为8,原始模型输入尺寸为1x3x224x224,那么在编译转换过程中生成的ptq_model.onnx模型的输入shape为8x3x224x224,
此时,您需要按照8x3x224x224的输入shape进行准备。
HBIR/HBM模型推理准备
由于在转换和编译过程中可能对HBIR/HBM模型进行修改,这些修改可能导致模型对输入数据的要求也发生变化。 因此在模型推理前,需要对模型所需的输入数据进行处理,下面我们给出几种常见场景下的输入数据准备。
数据预处理场景
如果您在yaml文件中配置了input_type_rt(与input_type_train不一致时)、mean_value和scale_value/std_value参数,模型将进行色彩转换和归一化处理,
您只需要按照input_type_rt的数据类型去做数据准备,且无需进行归一化处理。
Pyramid输入场景
如果您在yaml文件中,将input_type_rt设置为nv12或gray,或者将input_source设置为pyramid,则视为Pyramid输入场景。
Pyramid输入场景,即以YUV420SP(NV12)的形式进行输入的场景,数据准备步骤如下:
-
(如需)调整图片到适当尺寸。
-
需将原始输入类型转换为模型所需的NV12数据类型。
如果您在yaml配置文件中,配置了mean_value和scale_value/std_value等参数,则在数据准备阶段无需再进行归一化处理。
在使用Pyramid输入时,为了更好的处理图像数据,将会拆分成Y和UV通道进行shape输入。例如,若原始模型输入尺寸为1x3x224x224,
插入Pyramid输入时,所需输入的input_y的shape为1x224x224x1,input_uv的shape为1x112x112x2。
下方代码以RGB数据类型转NV12数据类型为例,供您参考,在实际使用场景中,请按需进行替换。
Resizer输入场景
如果您在yaml文件中,将input_source设置为resizer,则视为Resizer输入场景。
Resizer输入场景,即BPU上的模型以YUV420SP(NV12)加上一个矩形ROI的形式进行输入的场景,数据准备步骤如下:
-
(如需)调整图片到适当尺寸。
-
将原始输入类型转换为模型所需的NV12数据类型。
-
定义一个输入ROI(Region of Interest,感兴趣区域),通过ROI tensor输入坐标左,上,右,下四个边界来定义ROI大小。 对于ROI的详细介绍可参考[模型部署实践指导-模型修改-插入resizer输入-ROI简介及约束]章节。
如果您在yaml配置文件中,配置了mean_value和scale_value/std_value等参数,则在数据准备阶段无需再进行归一化处理。
在使用Resizer输入时,为了更好的处理图像数据,将会拆分成Y和UV通道,以及将定义好的ROI一并进行shape输入。
例如,若原始模型输入尺寸为1x3x224x224,插入Resizer输入时,所需输入的input_y的动态shape为1xNonexNonex1,
input_uv的动态shape为1xNonexNonex2,input_roi的shape为1x4。
下方代码以RGB数据类型转NV12数据类型为例,同时包含对ROI坐标的定义,供您参考,在实际使用场景中,请按需进行替换。
多Batch拆分场景
如果原始模型是多batch模型或者您在yaml文件中配置input_batch参数,并将separate_batch设置为True或者配置separate_name指定拆分节点,内部会对相应的输入节点进行拆分。
对于多batch模型,模型按照batch维度拆分后,每一个拆分后的模型输入根据所需输入类型、数据排布,自行准备输入数据。
例如,原始模型输入尺寸为1x3x224x224,若在yaml文件中将input_batch设置为8,则校准处理后,该ptq_model.onnx模型的shape为8x3x224x224。
此时,若yaml文件中还配置了separate_batch或separate_name参数,则会对模型对应输入进行batch拆分,
拆分后模型的输入shape是8个1x3x224x224,此时,您需要按照1x3x224x224的shape为每个输入准备数据进行准备。
结语
以上内容为您介绍了模型的校准集准备和一些典型场景下的模型推理时所需的数据准备。实际使用中,您可以参考本章节内容,针对性对输入数据进行准备。