常见问题
通用问题
任务创建或提交后返回HB_UCP_INVALID_ARGUMENT错误码是什么原因?
可根据UCP的错误日志来判断可能的问题,可能存在如下情况:
- 算子约束问题:大部分加速算子在创建时应满足使用约束,否则会返回错误码。
- 如果遇到日志打印
op $1 of task has no proper backend, user expect $2,表示没有合适的后端可执行;其中$1表示任务的类型,$2是任务提交时的backend参数,以二进制形式打印,需要按照每种backend可支持的core数量进行配置。
如何理解hbUCPSysMem的物理地址和虚拟地址?
在计算平台架构中,所有硬件的DDR内存共享,通过 hbUCPMallocCached 和 hbUCPMalloc 接口可以申请到一段物理空间连续的内存,其函数返回值被包装在 hbUCPSysMem 数据结构体中,phyAddr 和 virAddr 两个字段分别对应其内存空间的物理地址和虚拟地址,虚拟地址可直接被CPU访问,物理地址不可访问。
如何理解cacheable和非cacheable的hbmem?
ucp的内存管理接口提供了hbUCPMallocCached 和 hbUCPMalloc 来分配DDR读写内存,这种内存都是物理地址连续,可被bpu/dsp等ip访问使用的,其中 hbUCPMallocCached表示分配cacheable属性的内存,并配套了 hbUCPMemFlush 函数来对Cache进行刷新。
Cache机制是由计算平台的内存架构来决定的,可参考如下图所示。CPU与主存之间存在的Cache会缓存数据,而BPU/DSP/JPU/VPU(Video Processing Unit)/PYRAMID/STITCH/GDC等其他后端硬件与主存之间则没有cache。此时若错误使用Cache将会直接影响最终数据读写的准确性和效率。
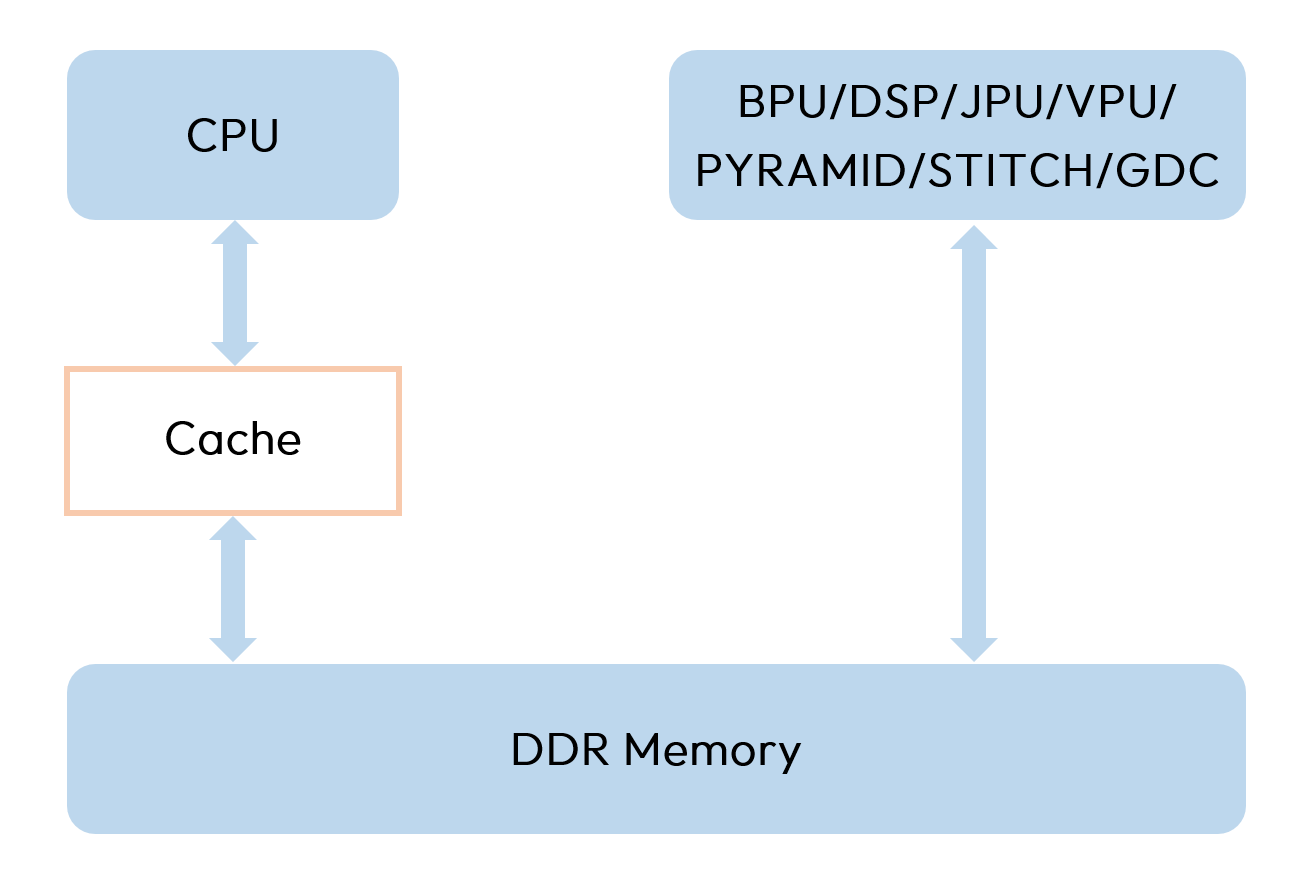
- 当CPU写完数据后,需要主动将Cache中的数据flush到memory中,否则其他硬件访问同一块内存空间时可能会读取到之前的旧数据。
- 而当其他后端硬件写完数据后,CPU在访问之前也需要主动将Cache中的数据invalidate掉,否则CPU可能会优先读取到之前缓存在cache中的旧数据。
- 在模型连续推理过程中,需要cpu读的,比如模型输出,建议申请带cacheable的内存,以加速CPU反复读写的效率,而不需要读的,只写的,比如模型输入,可以申请非cacheable的内存。
模型推理
导致模型推理hbUCPWaitTaskDone接口timeout超时的原因可能有哪些?
-
模型本身执行的时间较长,而异步等待接口设置的超时时间不足,或者当前计算资源负载较高导致任务排队时间较长,可能引发接口超时。
-
存在内存泄露情况。在系统内存不足的情况下,分配内存慢,可能会导致推理超时。
-
CPU负载过高。调度线程获取不到CPU,此时即使任务完成也无法及时同步到用户接口,导致推理超时情况。
模型推理卡住的原因
模型问题:模型指令原因导致的底层运行错误,错误没有上报,导致hang住。此时,可通过cat /sys/devices/system/bpu/bpu0/task_running对bpu任务情况进行查看,如下图所示:
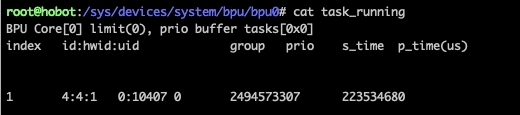
s_time不为空表示任务已经正常开始,而p_time如果为空则表示没有正常返回,即可认为BPU任务hang住了,可联系sr或者编译器团队解决。
ROI输入模型约束有哪些?
您可参考 ROI简介及约束 中对ROI限制的介绍。