模型修改
在模型转换编译过程中,可能会涉及到模型修改的场景,下方我们给出几种常见场景的示例代码及模型修改前后HBIR模型的对比作为示例。
请注意,如您是通过PTQ链路且使用API方式进行模型的转换编译,由于此链路默认不保存convert之前的HBIR模型(*.bc文件),如您需要基于此文件做可视化/做其他修改,可使用如下方式进行保存。
多batch拆分
场景
对于batch 1的输入模型,如您是通过PTQ链路进行的模型转换编译,我们支持您使用hb_compile工具配置yaml文件中的input_batch、separate_batch和separate_name参数来转换编译出可上板推理的模型。
参数的具体配置方式可参考 配置文件具体参数信息 章节的介绍。
而对于batch n的输入模型,如您需要对batch进行按维度拆分,从而编译出正确的可上板推理的模型,这个过程我们需要通过调用编译器的insert_split接口来实现。
insert_split参数:dim,用于指定输入batch的某一维度,数据类型为int,可以为负数(倒序拆分)。
方法
-
batch n的输入模型,且通过PTQ链路进行模型的转换编译,您需要先通过hb_compile工具或者HMCT API方式对原始浮点模型进行转换,生成ptq.onnx后,可以参考如下命令进行多batch的拆分:
-
batch n的输入模型,通过QAT链路进行模型的转换编译,可以参考如下命令进行多batch的拆分:
操作前后HBIR模型结构
此处展示的操作前后的HBIR文件为convert前后的HBIR文件(ptq_model.bc和quantized.bc),通过save命令保存。
| 操作前 | 操作后 |
|---|---|
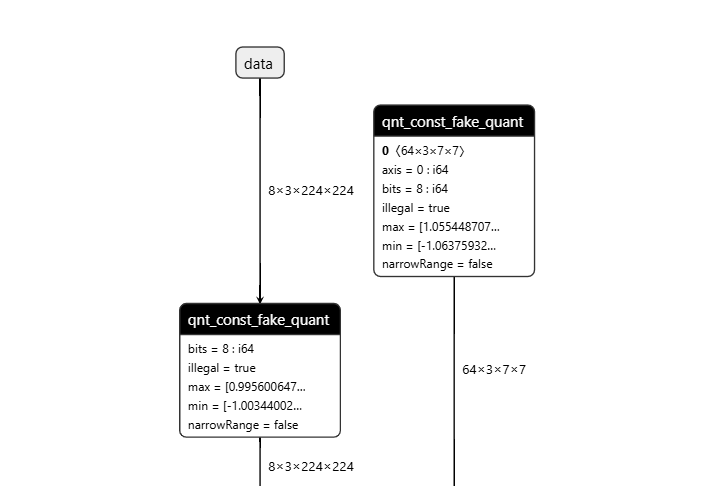 | 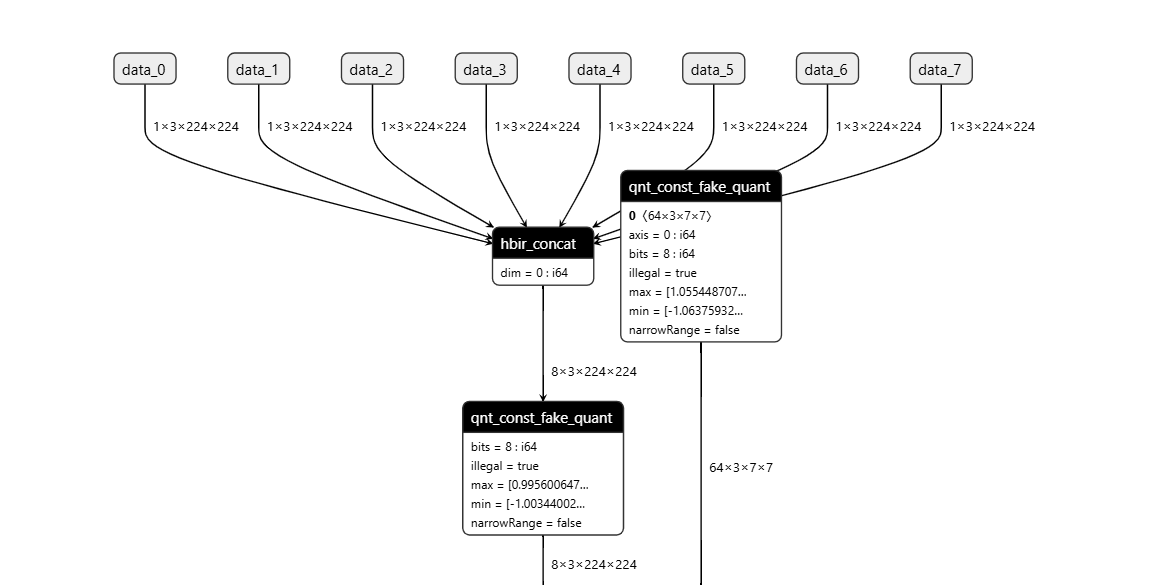 |
预处理节点插入
场景
在模型转换编译过程中生成HBIR模型(*.bc)时,若需要在HBIR模型内进行色彩转换、mean/scale/std处理的数据准备工作,这个过程我们通过插入预处理节点来实现。
如您是通过PTQ链路进行模型的转换编译,我们的hb_compile工具进行了封装,支持您通过配置yaml中相关的参数完成这些准备工作。
而如果您是通过PTQ链路API方式或者通过QAT链路进行模型的转换编译,这个数据准备工作则需要调用编译器insert_image_preprocess接口来进行。
insert_image_preprocess包括如下参数:
-
mode可选值包含:-
"yuvbt601full2rgb":YUVBT601Full转RGB模式(默认)。 -
"yuvbt601full2bgr":YUVBT601Full转BGR模式。 -
"yuvbt601video2rgb":YUVBT601Video转RGB模式。 -
"yuvbt601video2bgr":YUVBT601Video转RGB模式。 -
"bgr2rgb":BGR转RGB模式。 -
"rgb2bgr":RGB转BGR模式。 -
"skip":不进行图像格式的转换,仅进行preprocess处理。
-
-
divisor:数据转换除数,数据类型为int,默认值为255。 -
mean:数据集均值,数据类型为double,长度与输入c方向对齐,默认为[0.485, 0.456, 0.406]。 -
std:数据集标准差值,数据类型为double,长度与输入c方向对齐,默认为[0.229, 0.224, 0.225]。 -
is_signed:输入是否为有符号数,数据类型为bool,表示输入是否经过-128的转换,默认为True,当前暂时不支持为False的情况。 -
bit_width:输入的位宽长度,数据类型为int,表示输入为int8或者int16,当前可选值为8或者16。 -
image_layout:指定输入数据排布,数据类型为str,可选值包含:-
"normal":默认值,代表yuv使用的bit数都占满整个C。 -
"yhuvl":可选值,代表Y使用高位的bit数,UV只用低位8bit,会将UV左移8bit后进行后续计算。
-
请注意,由于预处理节点仅支持NHWC输入,因此若原始输入模型数据排布为NCHW,插入预处理节点后,HBIR和HBM模型的数据排布会变为NHWC,此变化不影响模型性能和精度。
方法
-
通过PTQ链路进行模型的转换编译,对于图像类输入,可以通过配置yaml中
input_type_rt、input_type_train、mean_value、scale_value/std_value等参数进行,参数的具体配置方式可参考 配置文件具体参数信息 章节的介绍。 -
通过PTQ链路API方式进行模型的转换编译,您需要先对原始浮点模型进行转换,生成ptq.onnx后,可以参考如下命令进行预处理节点的插入:
-
通过QAT链路进行模型的转换编译,可以参考如下命令进行预处理节点的插入:
操作前后HBIR模型结构
此处展示的操作前后的HBIR文件为convert前后的HBIR文件(ptq_model.bc和quantized.bc),通过save命令保存。
| 操作前 | 操作后 |
|---|---|
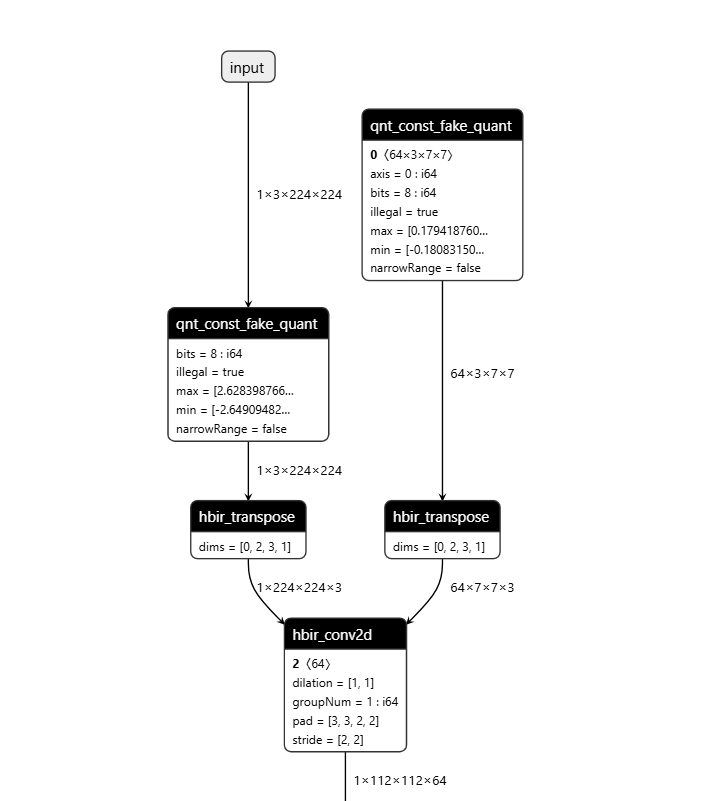 | 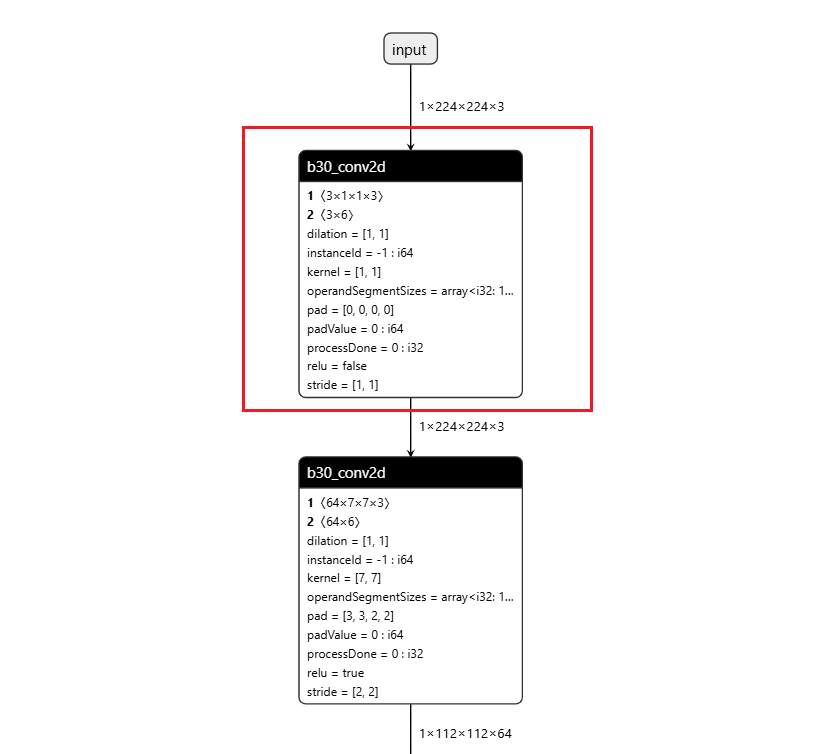 |
插入Pyramid输入
场景
Pyramid输入,即BPU上的模型以YUV420SP(NV12)的形式进行输入,在进行输入数据前处理准备时,需要设置Pyramid输入以设置输入数据来源。
如您是通过PTQ链路且使用命令行工具方式进行模型的转换编译,我们的hb_compile工具进行了封装,支持您通过配置yaml中相关的参数完成Pyramid输入的设置。
而如果您是通过PTQ链路API方式或者通过QAT链路进行模型的转换编译,Pyramid输入的设置则需要调用编译器insert_image_convert接口来进行。
insert_image_convert参数:
mode,指定转换模式,可选值包括:
-
"nv12":NV12模式(默认值),新的输入参数将变为二个(y分量和uv分量),c维度分别为1、2。 -
"gray":灰度图模式,新的输入参数将保持为一个,仅包含y分量,c维度为1。 -
"nv12_yh12":NV12模式,新的输入参数将变为二个(y分量和uv分量),c的维度分别为1、2。但其中,y分量会取16位的高12位为有效数据。 -
"nv12_yh10":NV12模式,新的输入参数将变为二个(y分量和uv分量),c的维度分别为1、2。但其中,y分量会取16位的高10位为有效数据。
请注意,由于硬件限制,插入Pyramid输入时,需保证W >=16。
方法
-
通过PTQ链路且使用命令行工具方式进行模型的转换编译,可以通过配置yaml中
input_type_rt、input_source参数进行Pyramid输入的设置,参数的具体配置方式可参考 配置文件具体参数信息 章节的介绍。 -
通过PTQ链路API方式进行模型的转换编译,您需要先对原始浮点模型进行转换,生成ptq.onnx后,可以参考如下命令进行Pyramid输入的设置:
-
通过QAT链路进行模型的转换编译,可以参考如下命令进行Pyramid输入的设置:
操作前后HBIR模型结构
此处展示的操作前后的HBIR文件为convert前后的HBIR文件(ptq_model.bc和quantized.bc),通过save命令保存。
| 操作前 | 操作后 |
|---|---|
| 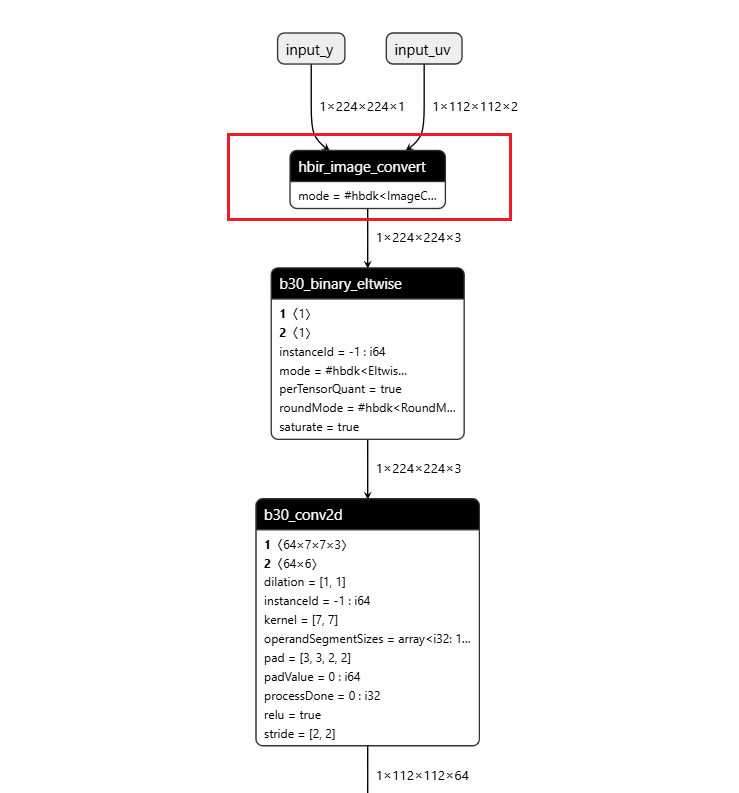 |
插入Resizer输入
场景
Resizer输入,即BPU上的模型以YUV420SP(NV12)加上一个矩形ROI的形式进行输入,在进行输入数据前处理准备时,需要插入Resizer输入节点以设置输入数据来源。
如您是通过PTQ链路且使用命令行工具方式进行模型的转换编译,我们的hb_compile工具进行了封装,支持您通过配置yaml中相关的参数完成Resizer输入节点的插入。
而如果您是通过PTQ链路API方式或者通过QAT链路进行模型的转换编译,Resizer输入的插入则需要调用编译器insert_roi_resize接口来进行。
insert_roi_resize参数:
-
mode,指定转换模式,可选值包括:-
"nv12":NV12模式(默认值),新的输入参数将变为三个,分别为y分量(c维度1)、uv分量(c维度2),以及用于指定roi的分量。 -
"gray":灰度图模式,新的输入参数将变为两个,y分量(c维度为1)以及用于指定roi的分量。 -
"nv12_yh12":NV12模式,新的输入参数将变为二个(y分量和uv分量),c的维度分别为1、2。但其中,y分量会取16位的高12位为有效数据。 -
"nv12_yh10":NV12模式,新的输入参数将变为二个(y分量和uv分量),c的维度分别为1、2。但其中,y分量会取16位的高10位为有效数据。
-
-
interpolation_mode,指定插值模式,可选值包括:-
"bilinear":双线性插值模式(默认值)。 -
"nearest":最近点插值模式。
-
-
在给定roi的坐标超出原输入的范围时,会对超出部分进行填充,填充可选参数包括:
-
pad_mode,在给定roi的坐标超出原输入的范围时,对超出部分进行填充的模式,在resize的可选值包括:-
"constant":常量值填充(默认值)。 -
"border":采用输入数据边缘值填充。
-
-
pad_value,指定常量填充值,默认值为 (0, -128),分别对应y与uv分量填充,仅当填充模式为pad_mode为constant时生效。
-
ROI简介及约束
ROI,即Region of Interest,感兴趣区域,共有四个区域边坐标:
-
left:ROI区域左边界的横坐标。 -
top:ROI区域上边界的纵坐标。 -
right:ROI区域右边界的横坐标。 -
bottom:ROI区域下边界的纵坐标。
ROI输入的模型限制及约束如下(Wout、Hout分别代表Resize后输出图像的W、H):
-
NV12输入的原图尺寸要求为:
-
S100&S100P:W方向的对齐要求
32 < = stride < = 262144, 且必须为32的倍数。 -
S600:W方向的对齐要求
64 < = stride < = 262144, 且必须为64的倍数。
-
-
ROI必须和图片有交集,
2 < = ROI_w < = 4096,2 < = ROI_h < = 4096。 -
ROI的坐标表示为
[w_begin, h_begin, w_end, h_end],左下、右下两个坐标点都包含在ROI范围内。 -
Resize后的输出图像尺寸要求是
2 < = Wout < = 4096,2 < = Hout < = 4096。 -
ROI和输出图像的大小约束要求为:
-
S100&S100P:
起始对齐:,。
大小对齐:,。
约束:
ROI_H * ROI_W + Hout * Wout < 1.5MB。 -
S600:
起始对齐:,。
大小对齐:,。
约束:
ROI_H * ROI_W + Hout * Wout < 2MB。
-
-
ROI缩放倍数限制:
1/3.5 < = Wout/ROI_w< 65536、1/3.5 < = Hout/ROI_h < 65536。
方法
-
通过PTQ链路且使用命令行工具方式进行模型的转换编译,可以通过配置yaml中
input_type_rt、input_source参数进行Resizer输入的设置,参数的具体配置方式可参考 配置文件具体参数信息 章节的介绍。 -
通过PTQ链路API方式进行模型的转换编译,您需要先对原始浮点模型进行转换,生成ptq.onnx后,可以参考如下命令进行Resizer输入的设置:
-
通过QAT链路进行模型的转换编译,可以参考如下命令进行Resizer输入的设置:
操作前后HBIR模型结构
此处展示的操作前后的HBIR文件为convert前后的HBIR文件(ptq_model.bc和quantized.bc),通过save命令保存。
| 操作前 | 操作后 |
|---|---|
| 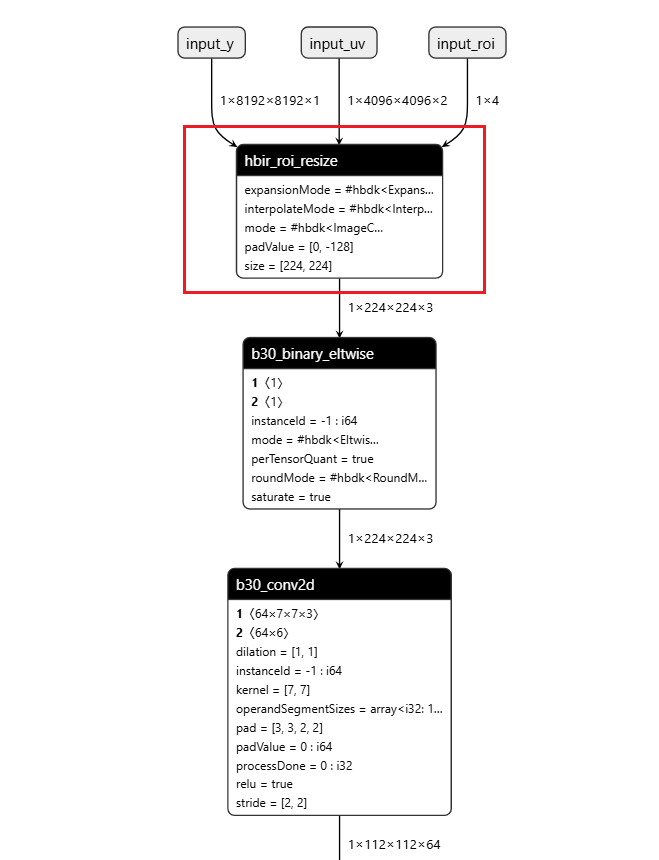 |
调整输入输出数据排布
场景
在一些特定场景中,我们需要对输入/输出数据进行数据排布的调整,例如,在进行数据前处理时,由于Pyramid/Resizer输入仅支持NHWC的输入,如您的原始浮点模型为NCHW的输入,此时就需要进行输入数据排布的重新调整,这个过程我们通过插入transpose节点来实现。
如您是通过PTQ链路且使用命令行工具方式进行模型的转换编译,我们的hb_compile工具进行了封装,支持您通过配置yaml中相关的参数进行指定,我们的工具内部会进行判断是否对数据排布作品调整。
而如果您是通过PTQ链路且使用API方式或者通过QAT链路进行模型的转换编译,调整数据排布则需要指定调用编译器insert_transpose接口来进行。
insert_tranpose参数:permutes,维度转换排列,数据类型为List,需要显式指定原输入的所有维度,从0开始。
-
insert_transpose插入输入参数(即调整输入数据排布)时,需要根据原始输入Tensor的维度和所需的输入参数维度进行permutes的推算,例如所需输入维度为NHWC,原始输入Tensor维度为NCHW,按照所需的NHWC推算,需要按照[0,3,1,2]的顺序能对应原始输入Tensor维度,则此时我们需要将permutes设置为[0,3,1,2]。
-
insert_transpose插入输出参数(即调整输出数据排布)时,则可以直接进行permutes的设置,例如,原始输出Tensor为[1,32,16,3],所需输出为[16,3,32,1],则原始输出Tensor按照[2,3,1,0]的顺序可以对应所需输出Tensor维度,则此时我们需要将permutes设置为[2,3,1,0]。
方法
-
通过PTQ链路且使用命令行工具方式进行模型的转换编译,可以在yaml文件中通过
input_layout_train参数对原始浮点模型的输入数据排布进行指定,我们的hb_compile工具内部会进行判断是否对是数据排布做调整,参数的具体配置方式可参考 配置文件具体参数信息 章节的介绍。 -
通过PTQ链路且使用API方式进行模型的转换编译,生成ptq.onnx后,可以参考如下命令进行输入数据排布的调整:
-
通过QAT链路进行模型的转换编译,可以参考如下命令进行输入数据排布的调整:
操作前后HBIR模型结构
此处展示的操作前后的HBIR文件为convert前后的HBIR文件(ptq_model.bc和quantized.bc),通过save命令保存。
| 操作前 | 操作后 |
|---|---|
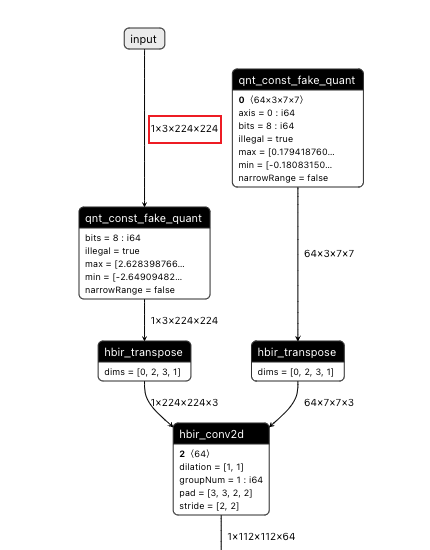 | 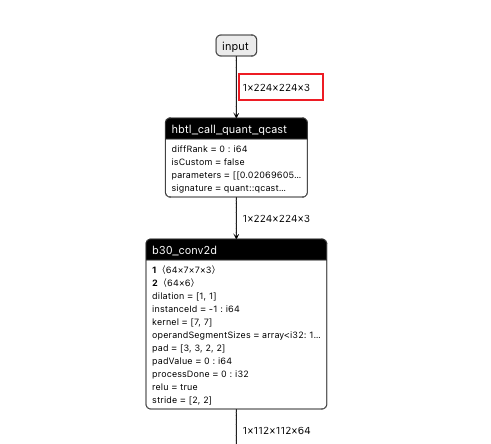 |
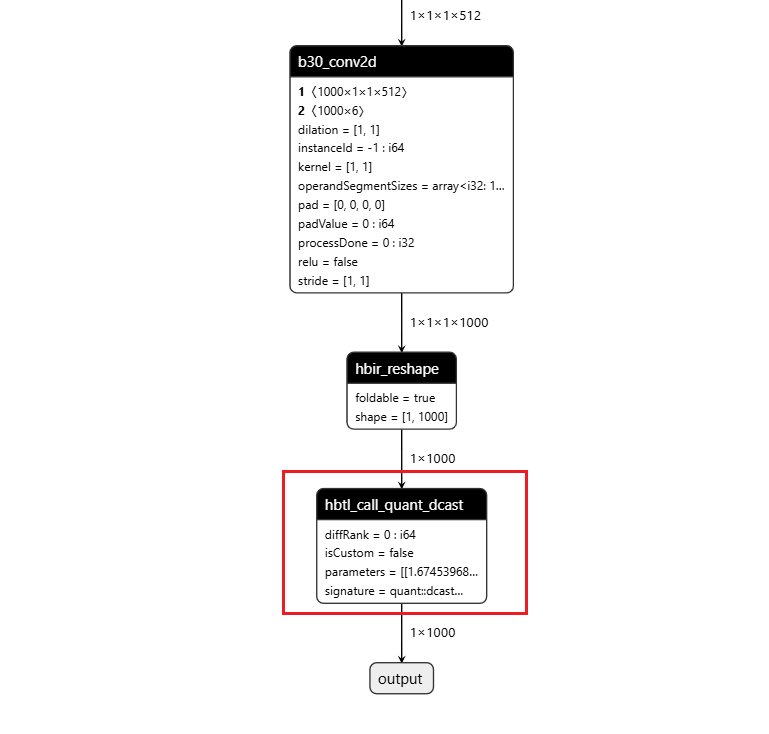
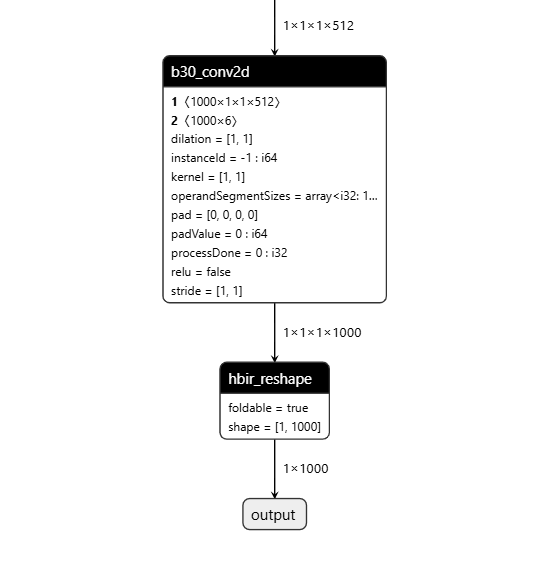
算子删除
场景
在模型convert后,我们支持您对模型首尾部的Dequantize、Quantize、Cast、Transpose、Softmax及Reshape算子进行删除。
如您是通过PTQ链路且使用命令行工具方式进行模型的转换编译,我们的hb_compile工具进行了封装,支持您通过配置yaml中相关的参数完成算子的删除。
而如果您是通过PTQ链路API方式或者通过QAT链路进行模型的转换编译,相关算子的删除则需要调用编译器remove_io_op接口来进行。
remove_io_op参数:
-
op_types:用于指定待删除算子类型,数据类型为List,指定后会遍历输入输出节点,删除您指定类型的算子,node type支持:["Quantize", "Dequantize", "Transpose", "Reshape", "Cast", "Softmax"]。
-
op_names:用于指定待删除算子名称,数据类型为List,指定后会删除您指定名称的算子,例如删除 ["transpose_1", "Reshape0"]。
op_types和op_names需要二选一,如同时指定两者,将只有op_names生效。
方法
-
通过PTQ链路且使用命令行工具方式进行模型的转换编译,可以在yaml文件中通过
remove_node_type、remove_node_name参数对需删除算子进行指定,参数的具体配置方式可参考 配置文件具体参数信息 章节的介绍。 -
通过PTQ链路且使用API方式进行模型的转换编译,生成ptq.onnx后,可以参考如下命令进行算子的删除:
-
通过QAT链路进行模型的转换编译,可以参考如下命令进行算子的删除:
操作前后HBIR模型结构
此处展示的操作前后HBIR文件为对convert之后的quantized.bc进行操作前后的模型(量化、反量化节点convert后才会插入),通过save命令保存。
| 操作前 | 操作后 |
|---|---|
 |  |