AI Benchmark User Guide
AI Benchmark Sample Package contains the most frequently used performance and accuracy evaluation samples of classification, detection, segmentation, optical-flow, tracking estimation, lidar multitask, bev, depth estimation and online map construction models. The performance evaluation samples include single-frame latency evaluation and multithreading evaluation samples, which make full use of the speed of invoking the BPU for evaluation. The pre-build source code, executable programs and evaluation scripts in the AI Benchmark Sample Package allow you to experience the samples, and develop their own applications, which makes development easier.
Release Description
The AI Benchmark sample package is located in the samples/ucp_tutorial/dnn/ai_benchmark/ path of the release package and consists the following main contents:
| No. | Name | Description |
|---|---|---|
| 1 | code | This folder contains sample source code and compilation scripts. |
| 2 | runtime | Dev board operating environment of the AI Benchmark Sample Package. |
Sample Code Package
Directory of the sample code package is shown as below:
- The code directory contains the source code of the evaluation program, used to evaluate model performance and accuracy.
- The runtime directory contains various pre-compiled application programs and evaluation scripts, used to evaluate the accuracy and performance of different models in Horizon's BPU (Brain Processing Unit).
Sample Models
Model releases for the AI Benchmark sample package include PTQ model and QAT model releases:
- You can get the model_zoo of the PTQ model by executing the script
resolve_ai_benchmark_ptq.shof thesamples/ai_toolchain/model_zoo/runtime/${march}/ai_benchmark/path. The${march}in the path can be set tonash-eornash-p, corresponding respectively to theS100/S100PandS600platforms. You can choose the appropriate one based on your needs. - You can get the model_zoo of the QAT model by executing the script
resolve_ai_benchmark_qat.shof thesamples/ai_toolchain/model_zoo/runtime/${march}/ai_benchmark/path. The${march}in the path can be set tonash-eornash-p, corresponding respectively to theS100/S100PandS600platforms. You can choose the appropriate one based on your needs. - The
ptq/modelfolder contains the model files, and the runtime folder is a symbolic link that by default points to../../../../../../model_zoo/runtime/nash-e/ai_benchmark/ptq. If you need to run a model with an architecture other thannash-e, you can manually changenash-ein the link path tonash-bornash-p. - The
qat/modelfolder contains the model files, and the runtime folder is a symbolic link that by default points to../../../../../../model_zoo/runtime/nash-e/ai_benchmark/qat. If you need to run a model with an architecture other thannash-e, you can manually changenash-ein the link path tonash-bornash-p.
Among them, which contain the commonly used classification, detection, segmentation and optical flow prediction models, and the naming rules of the models is {model_name}_{backbone}_{input_size}_{input_type}.
Both the PTQ and QAT models in model_zoo are compiled by the original model.
The performance data of the model in the AI Benchmark sample package can be found in the section Benchmark of Model Performance depending on your platform.
Public Datasets
The dataset will be used in the sample, you can download the corresponding dataset in section Dataset Download. If you have any questions during the data preparation process, please contact Horizon.
Environment Configuration
Before using the AI Benchmark sample package, you need to ensure that the development board environment and compilation environment are available:
-
Prepare the Development Board
-
After getting the development board, upgrade the system image file to the version recommended by the sample package.
-
Make sure the remote connection between local dev machine and the dev board.
-
-
Prepare the compilation environment
Install the aarch64-none-linux-gnu-gcc and aarch64-none-linux-gnu-g++ cross-compilation tool in current environment. Then execute the build_ptq_runtime.sh and build_qat_runtime.sh scripts in the code directory to compile the executable program in the real machine environment with one click. The executable programs and corresponding dependencies will be copied into the aarch64 sub-folders of the runtime/ptq/script and runtime/qat/script folders automatically.
The cross-compilation tool specified by the build.sh script is located in the /opt folder.
If you want to install it into some other locations, please modify the script.
How to Use
Evaluation Scripts
Evaluation sample scripts are in the script and tools folders.
The script folder contains the scripts used for evaluating frequently used classification, detection, segmentation, optical-flow, tracking estimation, lidar multitask, bev and depth estimation models in dev board. There are three scripts under each model:
| Script | Description |
|---|---|
| fps.sh | The script implements FPS statistics (multi-threading scheduling. You can freely specify number of threads as needed) . |
| latency.sh | The script implements statistics of single-frame latency (one thread, single-frame). |
| accuracy.sh | The script is used for evaluating model accuracy. |
The (PTQ)tools folder contains the precision calculation scripts under python_tools, which used for accuracy evaluation.
Run the following commands before the evaluation and copy the ptq (or the qat) directory to the dev board.
Parameters of json Configuration File
This section we provide you the brief introduction of the configuration for the workflow_fps.json, workflow_latency.json and workflow_accuracy.json. The configuration can be simply divided into input_config, output_config and the workflow configuration.
The configuration parameters given below are the general configuration, some sample models will have additional configuration due to the model specificity, please refer to the sample model json file for details.
input_config
| Parameter Name | Description | Involved json Files |
|---|---|---|
| input_type | Specify the input data format, support image or bin file. | fps.json, latency.json, accuracy.json |
| height | Specify the input data height. | fps.json, latency.json, accuracy.json |
| width | Specify the input data width. | fps.json, latency.json, accuracy.json |
| data_type | Specify the input data type. Supported type can refer to | fps.json, latency.json, accuracy.json |
| image_list_file | Specify the path of the lst file of the preprocessing dataset. | fps.json, latency.json, accuracy.json |
| need_pre_load | Specify whether to read the dataset using the preload method. | fps.json, latency.json, accuracy.json |
| limit | Specify the threshold for the difference between the amount of input data being processed and has been processed, which is used to control the processing threads for the input data. | fps.json, latency.json, accuracy.json |
| need_loop | Specify whether to use cyclic read data for evaluation. | fps.json, latency.json, accuracy.json |
| max_cache | When this parameter takes effect, the image will be pre-processed and read into memory. To ensure the stable running of your application, do not set too large a value, we recommend that you set a value of no more than 30. | fps.json, latency.json, accuracy.json |
output_config
| Parameter Name | Description | Involved json Files |
|---|---|---|
| output_type | Specify the output data type. | fps.json, latency.json and accuracy.json |
| in_order | Specify whether to output in order. | fps.json, latency.json and accuracy.json |
| enable_view_output | Specify whether to visualize the output. | fps.json and latency.json |
| image_list_enable | When visualizing, set to true to save the output as the image type. | fps.json and latency.json |
| view_output_dir | Specify the path of the visualization result output file. | fps.json and latency.json |
| eval_enable | Specify whether to evaluate the accuracy. | accuracy.json |
| output_file | Specify the model output result file. | accuracy.json |
Workflow Configuration
Model inference configurations:
| Parameter Name | Description | Involved json Files |
|---|---|---|
| method_type | Specify the model inference method, which here needs to be configured as InferMethod. | fps.json, latency.json, accuracy.json |
| method_config | Specify the model inference parameters.
| fps.json, latency.json, accuracy.json |
Post-processing configurations:
| Parameter Name | Description | Involved json Files |
|---|---|---|
| thread_count | Specify the post-processing thread count, in range 1-8. | fps.json, latency.json and accuracy.json |
| method_type | Specify the post-processing method. | fps.json, latency.json and accuracy.json |
| method_config | Specify the post-processing parameters. | fps.json, latency.json and accuracy.json |
Performance Evaluation
Performance evaluation is divided into latency and fps.
How to Use Performance Evaluation Scripts
latency:
In the directory of the to-be-evaluated model, run sh latency.sh to evaluate single frame latency, as shown below:
inferdenotes the time consumption of model inference.Post processdenotes the time consumption of post-processing.
fps:
This function uses multi-threaded concurrency and is designed to allow the model to reach the ultimate performance on BPU.
Due to the multi-thread concurrency and data sampling, the frame rate value will be low during the start-up phase, then the frame rate will increase and gradually stabilize, with the frame rate fluctuating within 0.5%.
To test the frame rate, go to the model directory and run sh fps.sh, as shown below.
About Command-line Parameters
The fps.sh script is shown as below:
The latency.sh script is shown as below:
Result Visualization
If you want to see the effect of a single inference of the model, you can modify workflow_latency.json and re-run the latency.sh script to generate the display effect in the output_dir directory.
When the display effect is generated, the script will run slowly due to the dump effect. Only the latency.sh script dump is supported.
The Visual operation steps are as follows:
-
Modify the latency configuration file
-
Execute the latency.sh script
The visualization of the bev model needs to specify the scene information and the path of the homography matrix. The homography matrix is used for the conversion of the camera perspective and the bird's-eye view. Different scenes have their own homography matrices. The visualization of the online map construction model needs to specify the perception range of local map.
The workflow_latency.json configuration file of the bev model is recommended to be modified as follows:
The workflow_latency.json configuration file of the online map construction model is recommended to be modified as follows:
QCNet integrates model visualization and accuracy evaluation.
The visualization method of qcnet is as follows:
The visualization results that can be achieved by different types of models are different, refer to the table below:
| Model Category | Visualization |
|---|---|
| classification |  |
| detection 2d |  |
| detection 3d |  |
| segmentation |  |
| keypoint |  |
| lane line |  |
| optical flow |  |
| lidar |  |
| lidar multitask |
|
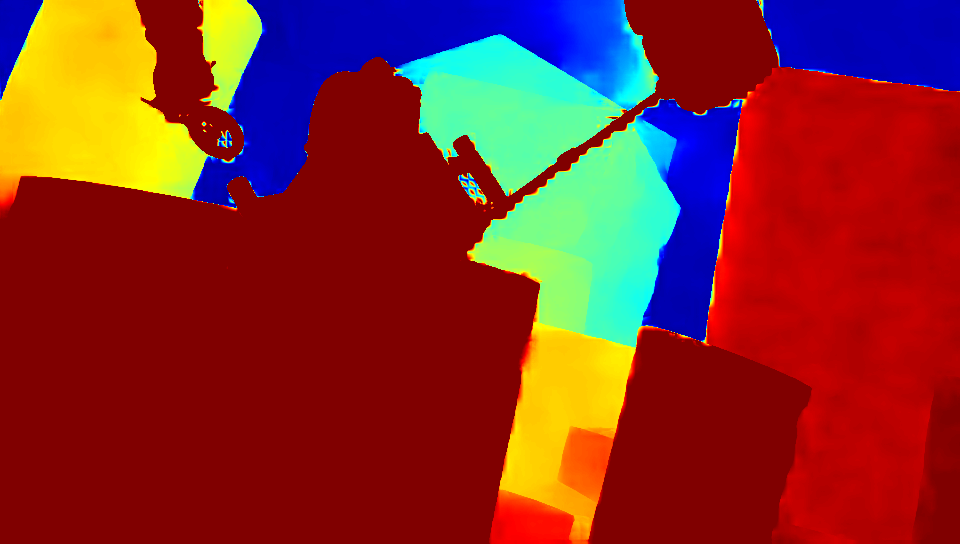
| bev |
|
| raj_pred |  |
| disparity_pred |
|
| online map construction |  |
| occ_pred | 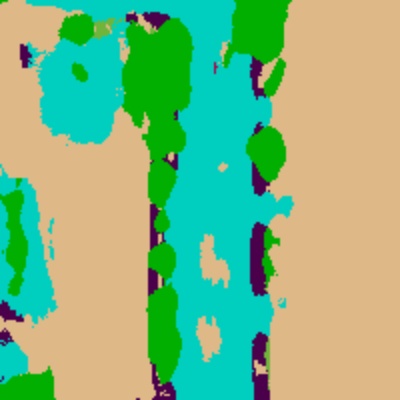 |











If you need to visualize images other than minidata during trajectory prediction visualization, you need to configure additional road information and trajectory information files in minidata/argoverse1/visualization. You can use the densent_process.py preprocessing script to generate configuration files, and set --is-gen-visual-config parameter to true.
Model Accuracy Evaluation
Take the following 5 steps to perform the model evaluation:
-
Data pre-process.
-
Data mounting.
-
The lst file generation.
-
Model inference.
-
Model accuracy computing.
Data Pre-processing
The following section will provide the description of the PTQ and QAT model data preprocessing methods.
PTQ Model Data Pre-processing:
To the PTQ model data pre-processing, run the hb_eval_preprocess tool in x86 to pre-process data.
The so-called pre-processing refers to the special processing operations before images are fed into the model.
For example: resize, crop and padding, etc. The tool is integrated into the horizon_tc_ui tool and it will be available after the tool is installed using the install script.
After the raw dataset is pre-processed by the tool, the corresponding pre-processed binary file .bin file set of the model will be generated.
About the hb_eval_preprocess tool command line parameters and usage, you can type hb_eval_preprocess -h, or see the hb_eval_preprocess Tool in the PTQ tools guide.
The datasets corresponding to each model in the sample package are described in detail below, as well as the pre-processing operations for the corresponding datasets.
The datasets used for PTQ models include the following:
| Dataset | Description |
|---|---|
VOC Dataset | For evaluation of detection models using the The dataset download and reference download structure can be found in section Preparing Datasets. The sample mainly use the val.txt file under the Main folder, the source images under the JPEGImages folder and the annotations under the Annotations folder. 2. Dataset preprocessing methods example: |
COCO Dataset | For evaluation of detection models using the 1. The dataset download and reference download structure can be found in section Preparing Datasets. The samples mainly use the instances_val2017.json annotation file under the annotations folder images under the images folder. 2. Dataset preprocessing methods example: |
ImageNet Dataset | For evaluation of classification models using the 1. The dataset download and reference download structure can be found in section Preparing Datasets. The samples mainly use the annotation file val.txt and the source images in the val directory. 2. Dataset preprocessing methods example: |
Cityscapes Dataset | For evaluation of segmentation models using the 1. The dataset download and reference download structure can be found in section Preparing Datasets. The samples mainly use the annotation files under the ./gtFine/val folder and the source images in the ./leftImg8bit/val folder. 2. Dataset preprocessing methods example: |
QAT Model Data Pre-processing:
HAT provides the tools to preprocess the LMDB dataset.
The datasets corresponding to each model are described in detail as below, as well as the pre-processing operations for the corresponding datasets.
Location of the data preprocessing scripts: oe package/samples/ai_toolchain/horizon_model_train_sample/scripts.
The data preprocessing scripts need to be run in a GPU environment.
Before use, please package the original dataset into LMDB data,then mount it to the tmp_data directory in the working path.
| Dataset | Description |
|---|---|
ImageNet Dataset | The ImageNet dataset is used for evaluating the mixvargenet_imagenet, mobilenetv1_imagenet, mobilenetv2_imagenet, resnet18_imagenet, resnet50_imagenet, horizon_swin_transformer_imagenet, vit_small_imagenet and vargnetv2_imagenet QAT models. Dataset preprocessing methods: 1. After running the script, an the specified save-path for precision calculation. 2. The data preprocessing logic for these models is consistent, so the data generated after running the script once can be reused for other models.
|
COCO Dataset | The COCO dataset is used for evaluating the fcos_efficientnetb0_mscoco, detr_resnet50_mscoco, detr_efficientnetb3_mscoco and deform_detr_resnet50_mscoco QAT models. Dataset preprocessing methods: 1. After running the script, a the specified save-path for precision calculation. 2. The data preprocessing logic for detr_resnet50_mscoco and detr_efficientnetb3_mscoco are consistent, so the data generated after running the script once can be reused for the another models.
|
Cityscapes Dataset | The Cityscapes dataset is used for the evaluation of the QAT segmentation model unet_mobilenetv1_cityscapes. Dataset preprocessing methods: After running the script, a directory named |
Kitti3D Dataset | The Kitti3D dataset is used for evaluating the pointpillars_kitti_car model. Dataset preprocessing methods: After running the script, a |
Culane Dataset | The Culane dataset is used for evaluating the ganet_mixvargenet_culane model. Dataset preprocessing methods: After running the script, a |
Nuscenes Dataset | The Nuscenes dataset is used for evaluating the fcos3d_efficientnetb0_nuscenes, centerpoint_pointpillar_nuscenes, centerpoint_mixvargnet_multitask_nuscenes, bev_gkt_mixvargenet_multitask_nuscenes, bev_lss_efficientnetb0_multitask_nuscenes, bev_ipm_efficientnetb0_multitask_nuscenes, bev_ipm_4d_efficientnetb0_multitask_nuscenes, bevformer_tiny_resnet50_detection_nuscenes, maptroe_henet_tinym_bevformer_nuscenes, detr3d_efficientnetb3_nuscenes, petr_efficientnetb3_nuscenes and flashocc_henet_lss_occ3d_nuscenes models. Dataset preprocessing methods: 1. For the following models: flashocc_henet_lss_occ3d_nuscenes, bevformer_tiny_resnet50_detection_nuscenes, bev_lss_efficientnetb0_multitask_nuscenes, petr_efficientnetb3_nuscenes, detr3d_efficientnetb3_nuscenes, bev_gkt_mixvargenet_multitask_nuscenes, bev_ipm_4d_efficientnetb0_multitask_nuscenes, bev_ipm_efficientnetb0_multitask_nuscenes and centerpoint_mixvargnet_multitask_nuscenes, running the script will generate a the specified save-path for precision calculation. 2. For the model maptroe_henet_tinym_bevformer_nuscenes, running the script will generate a the specified save-path for precision calculation. 3. According to the README in the reference model algorithm package, download the corresponding model's reference points and place them under
|
Mot17 Dataset | The Mot17 dataset is used for evaluating the motr_efficientnetb3_mot17 model. Dataset preprocessing methods: |
Carfusion Dataset | The Carfusion dataset is used for evaluating the keypoint_efficientnetb0_carfusion model. Dataset preprocessing methods: After running the script, a |
Argoverse1 Dataset | The Argoverse1 dataset is used for evaluating the densetnt_argoverse1 model. Dataset preprocessing methods: After running the script, a |
Argoverse2 Dataset | The Argoverse2 dataset is used for evaluating the qcnet_oe_argoverse2 model. Dataset preprocessing methods: After running the script, a |
SceneFlow Dataset | The SceneFlow dataset is used for evaluating the stereonetplus_mixvargenet_sceneflow model. Dataset preprocessing methods: After running the script, a |
Model Mounting
Because datasets are huge, it is recommended to mount them for dev board to load, rather than to copy them into the dev board, you need to do the following on the server PC terminal and the board terminal:
Server PC terminal:
Note that the root permission is required on the server pc terminal to perform the following actions.
-
Edit one line into
/etc/exports:/nfs *(insecure,rw,sync,all_squash,anonuid=1000,anongid=1000,no_subtree_check). Wherein,/nfsdenotes mounting path of local machine, it can be replaced by the directory you specify. -
Run
exportfs -a -rto bring /etc/exports into effect.
Board terminal:
-
Create the directory to be mounted:
mkdir -p /mnt. -
Mount:
mount -t nfs {PC terminal IP}:/nfs /mnt -o nolock.
Mount the /nfs folder at PC terminal to the /mnt folder in dev board. In this way, mount the folder in which contains preprocessed folder to dev board and create a soft link of /data folder in the /ptq or /qat folder (at the same directory level as /script) in dev board.
Generate lst Files
The running process of precision calculation script in the sample is:
-
According to the value of
image_list_fileinworkflow_accuracy.json, find thelstfile of the corresponding dataset. -
Load each preprocessing file according to the path information of preprocessing file stored in
lstfile, and then perform the inference.
Therefore, after generating the preprocessing file, you need to generate the corresponding LST file, and write the path of each preprocessing file into the lst file, which is related to the storage location of the dataset at the board end.
Here, we recommend that its storage location shall be the same level as the ./data/dataset_name/pre_model_name folder.
The structure of the PTQ pre-processed dataset is as follows:
The structure of the QAT pre-processed data set is as follows:
The corresponding lst file is generated by reference as follows:
Except for the densetnt_argoverse1, qcnet_oe_argoverse2, bev, motr_efficientnetb3_mot17, stereonetplus_mixvargenet_sceneflow and maptroe_henet_tinym_bevformer_nuscenes models, the reference generation method of the lst files for the other models:
The parameters after -name need to be adjusted according to the format of the preprocessed dataset, such as bin, png.
The path stored in the generated lst file is a relative path: ../../../data/coco/pre_centernet_resnet101/ , which can match the workflow_accuracy.json default configuration path.
If you need to change the storage location of the preprocessing dataset, you need to ensure that the corresponding lst file can be used by workflow_accuracy.json.
Secondly, it is necessary to ensure that the program can read the corresponding preprocessing file according to the path information in lst file.
For the densetnt_argoverse1, qcnet_oe_argoverse2, bev, motr_efficientnetb3_mot17, stereonetplus_mixvargenet_sceneflow and maptroe_henet_tinym_bevformer_nuscenes models, the reference generation method of the lst files:
| Model Name | Reference Generation Method and Description of lst File |
|---|---|
| densetnt_argoverse1 | Reference generation method: The path stored in the generated |
| qcnet_oe_argoverse2 | We provide a dedicated script, This script requires two input parameters: |
Bev maptroe_henet_tinym_bevformer_nuscenes | Take the bev_ipm_efficientnetb0_multitask_nuscenes as an example. This model has two types of input: images and reference points.
The input image and reference point of the same frame have the same name.
In order to ensure that the input corresponds, you need to add In addition, bev_ipm_4d_efficientnetb0_multitask_nuscenes is a timing model, which requires input order. Therefore, we provide a script
The path stored in the generated If you need to change the storage location of the preprocessing dataset, you need to ensure that the corresponding |
| motr_efficientnetb3_mot17 | Reference generation method: The path stored in the generated If you need to change the storage location of the preprocessing dataset, you need to ensure that the corresponding Secondly, it is necessary to ensure that the program can read the corresponding preprocessing file according to the path information in
|
| stereonetplus_mixvargenet_sceneflow | Take the stereonetplus_mixvargenet_sceneflow as an example. The input left image and right the same frame have the same name. In order to ensure that the input corresponds, you need to add |
Model Inference
The accuracy.sh script is shown as below:
After the data has been mounted, log in dev board and run the accuracy.sh script in the centernet_resnet101 directory, as shown below:
Inference results will be saved into the eval.log file dumped by dev board program.
Model Accuracy Computing
Please perform the accuracy calculation in docker environment or Linux environment.
Accuracy computing is presented in two cases: PTQ model accuracy computing and QAT model accuracy computing.
PTQ Model Accuracy Computing:
For the PTQ model, the model accuracy computing scripts are placed under the ptq/tools/python_tools/accuracy_tools folder, in which:
| Script | Description |
|---|---|
| cls_imagenet_eval.py | The script is used for computing accuracy of classification models evaluated using the ImageNet dataset. |
| det_coco_eval.py | The script is used for computing the accuracy of models evaluated using the COCO dataset. |
| seg_cityscapes_eval.py | The script is used for computing the accuracy of segmentation models evaluated using the Cityscapes dataset. |
| det_voc_eval.py | The script is used for computing the accuracy of detection models using the VOC dataset. |
Below we provide you with the description of the different types of PTQ model accuracy computing:
| Model Type | Description of the Accuracy Computing |
|---|---|
| Classification Model | Method to compute the accuracy of those models using the ImageNet datasets is shown as below: In which:
|
| Detection Model | 1.Method to compute the accuracy of those models using the COCO dataset is shown as below: In which:
2.Method to compute the accuracy of those detection models using the VOC dataset is shown as below: In which:
|
| Segmentation Model | Method to compute the accuracy of those segmentation models using the Cityscapes dataset is shown as below: In which:
|
QAT Model Accuracy Computing:
Location of the accuracy computing scripts: oe package/samples/ai_toolchain/horizon_model_train_sample/scripts.
The accuracy computing scripts need to be run in a GPU environment.
Below we provide you with the description of the different types of QAT model accuracy computing:
| Dataset | Description of the Accuracy Computing |
|---|---|
ImageNet Dataset |
In which:
|
COCO Dataset |
In which:
|
Cityscapes Dataset | In which:
|
Kitti3D Dataset | In which:
|
Culane Dataset | In which:
|
Nuscenes Dataset |
In which:
|
Mot17 Dataset | In which:
|
Carfusion Dataset | In which:
|
Argoverse1 Dataset | In which:
|
Argoverse2 Dataset | In which:
|
SceneFlow Dataset | In which:
|
Model Integration
Pre-processing
You can add model pre-processing as needed and deploy it to CPU or DSP, taking centerpoint_pointpillar_nuscenes as an example:
-
Add the preprocessing file
qat_centerpoint_preprocess_method.ccand the header fileqat_centerpoint_preprocess_method.h. -
Add model preprocessing configuration file.
Add Pre-processing File and Header File
The pre-processing qat_centerpoint_preprocess_method.cc files are placed under the ai_benchmark/code/src/method/ folder.
While the header file qat_centerpoint_preprocess_method.h files are placed under the ai_benchmark/code/include/method/ floder.
Add Preprocessing Configuration File
Preprocess of centerpoint_pointpillar_nuscenes can deploy to CPU or DSP depends on whether you config the run_on_dsp parameter in the centerpoint_pointpillar_5dim.json.
If run_on_dsp in config file is set to true then preprocess will be running on DSP otherwise it running on CPU.
To Evalute the Latency of Preprocessing
Run sh latency.sh to evaluate single frame latency of preprocess, as shown below:
In which:
Pre processdenotes the time consumption of pre-processing.Inferdenotes the time consumption of model inference.Post processdenotes the time consumption of post-processing.
Postprocessing
Post-processing consists of 2 steps. Let's take integration of CenterNet model as an example:
-
Add the post-processing file ptq_centernet_post_process_method.cc and the header file ptq_centernet_post_process_method.h.
-
Add a model execution script and a configuration file.
Add Post-processing File
Post-processing code file can reuse any post-processing files in the src/method directory. You only need to modify the InitFromJsonString function and the PostProcess function.
The InitFromJsonString function is used for loading the post-processing related parameters in the workflow.json.
You can customize the corresponding input parameters. The PostProcess function is used for implementing post-processing logic.
The post-processing ptq_centernet_post_process_method.cc files are placed under the ai_benchmark/code/src/method/ folder.
While the header files ptq_centernet_post_process_method.h are placed under the ai_benchmark/code/include/method/ folder.
Add Model Execution and Configuration Files
Directory structure of scripts is shown as below:
-
The centerpoint_pointpillar_nuscenes model:
To process on
DSP, you need to executedsp_deploy.shto deploy theDSPenvironment. For a detailed introduction to dsp deployment, please refer toREADME.md. -
The motr_efficientnetb3_mot17 model:
-
The models except for the centerpoint_pointpillar_nuscenes and motr_efficientnetb3_mot17:
Helper Tools
Log
There are 2 types of logs: sample Log and DNN Log. Wherein, sample log refers to the log in the AI Benchmark Sample Package deliverables, while DNN log refers to the log in the embedded runtime library. You can specify logs as needed.
Sample Log
- Log level.
Both glog and vlog are used in sample log and there are 4 customized log levels:
0: SYSTEM level, this log level is used for generating error information in sample code.1: REPORT level, this log level is used for generating performance data in sample code.2: DETAIL level, this log level is used for generating current system status in sample code.3: DEBUG level, this log level is used for generating debugging information in sample code.
- Set log levels.
Rules to set log levels: The default ranks of log level: DEBUG>DETAIL>REPORT>SYSTEM, the higher the level, the more logs will be output. That is, if you set a high level, the logs corresponding to your own level and the level below it will be output.
When running samples, specify the log_level parameter to set log levels. For example, if log_level=0, then SYSTEM log should be dumped; else if log_level=3, then DEBUG, DETAIL, REPORT and SYSTEM logs should be dumped.
dnn Log
For the configuration of dnn logs, please read the Configuration Info section in the Model Inference API Instruction.
OP Time Consumption
Overview
Use the HB_DNN_PROFILER_LOG_PATH environment variable to specify statistics of OP performance. Types and values of this environment variable are described as below:
HB_DNN_PROFILER_LOG_PATH=${path}: denotes the output path of OP node. After the program is executed, a profiler.log file should be generated.
Sample
Taking the mobilenetv1 as an example, as shown in the following code block: Start 1 threads to run the model at the same time, set export HB_DNN_PROFILER_LOG_PATH=. /, then the profiler.log file will output the performance data of the OPs.
The output information contains model_latency and task_latency.
Wherein, model_latency contains the time consumption required to run each operator of the model; while task_latency contains the time consumption of each task of the model.
Dump Tool
Enable the HB_DNN_DUMP_PATH environment variable to dump the input and output of each node in inference process.
The dump tool can check if there are consistency problems between simulator and real machine, i.e.
Whether the output of the real machine and the simulator are exactly the same, given the same model and the same inputs.